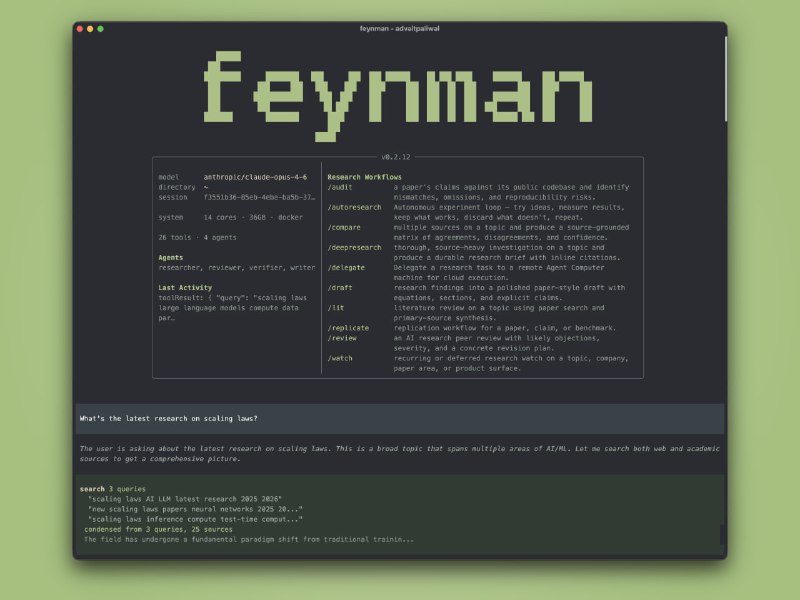
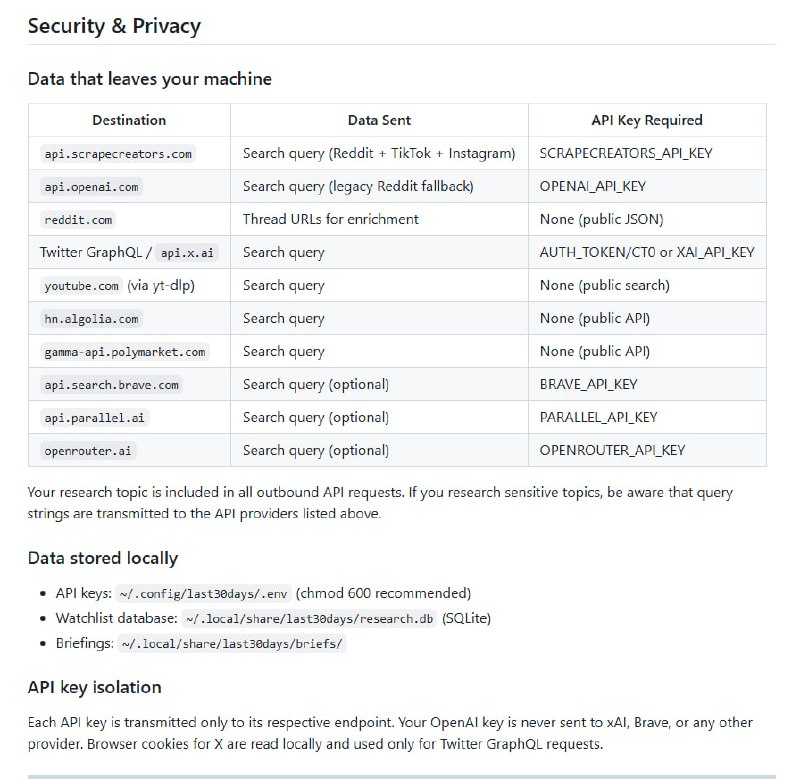
Reddit上一个关于“最短高效提示词”的帖子引起了广泛讨论。核心结论是:几句话的设计,远比长篇大论更有力量。提示词不是越多越好,而是要打在要害上。|
帖子多数人用AI的方式,是在跟一个想取悦你的人聊天。它会点头,会夸你,会把你的问题包装成智慧。
改变这一切只需要一句话:
“Be honest, not agreeable.”
高赞回复里,有观点认为最有效的不是“聪明提问”,而是在提问之前先做一件事:让AI在回答前,先说出你隐含的假设、最常见的错误、以及会改变答案的缺失信息,然后问你一个关键问题,等你回答之后才给出结论。
这个结构的逻辑很简单:AI默认填补你的认知空白,而这个填补过程你是看不见的。把它拿出来,你才知道自己在问一个什么样的问题。
另一个被反复提到的方向是反拍马屁设定。有网友在自定义指令里写:停止表示赞同,作为我的高级顾问,不要验证我,不要软化真相,不要奉承,挑战我的思路,指出我在回避什么,告诉我机会成本。
有观点认为这类提示有个陷阱:命令AI“停止赞同”,它可能变成一个表演批评的模型,而非真正提供有价值的反馈。让它太对抗性,会产生疲惫感,而非突破感。
一些简短但实用的提示词,按效果排列:
-“Think step by step before answering.”多步推理准确率显著提升
-“Assume I am wrong. Show me where.”评审、代码审查、逻辑验证最好用
-“If you don't know exactly, say UNKNOWN.”把不确定变成可识别信号
-“You are a [role]. Never [that role's most common failure mode].”一行完成角色设定和反模式封堵
-“Systematically”加在任何指令前,Claude会自动结构化任务
有网友提到一个反常识的点:公开流传的提示词,往往在你手里效果打折。因为提示词的输出高度依赖对话上下文,原作者隐性提供了大量背景,你复制的只是字面,不是那个上下文。
所以真正的问题或许是:你到底需要AI给你答案,还是帮你想清楚问题本身?