黑洞资源笔记
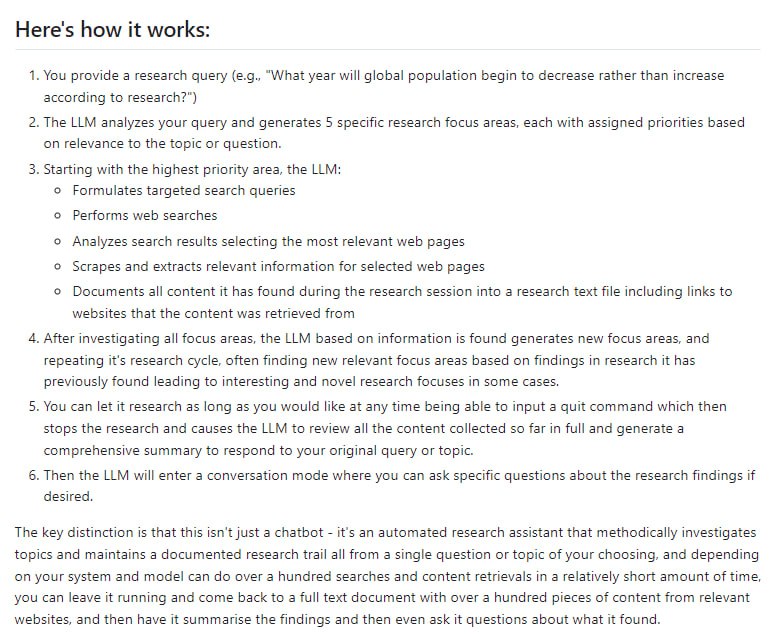
- Automated-AI-Web-Researcher-Ollama:基于Ollama的自动化研究助手,能够自主执行网络研究任务。输入一个查询后,它会自动确定研究重点、执行网页搜索和内容抓取、保存发现的内容。特色功能包括优先级研究规划、系统化网络搜索、结果自动保存、研究总结生成以及基于研究结果的问答功能
-
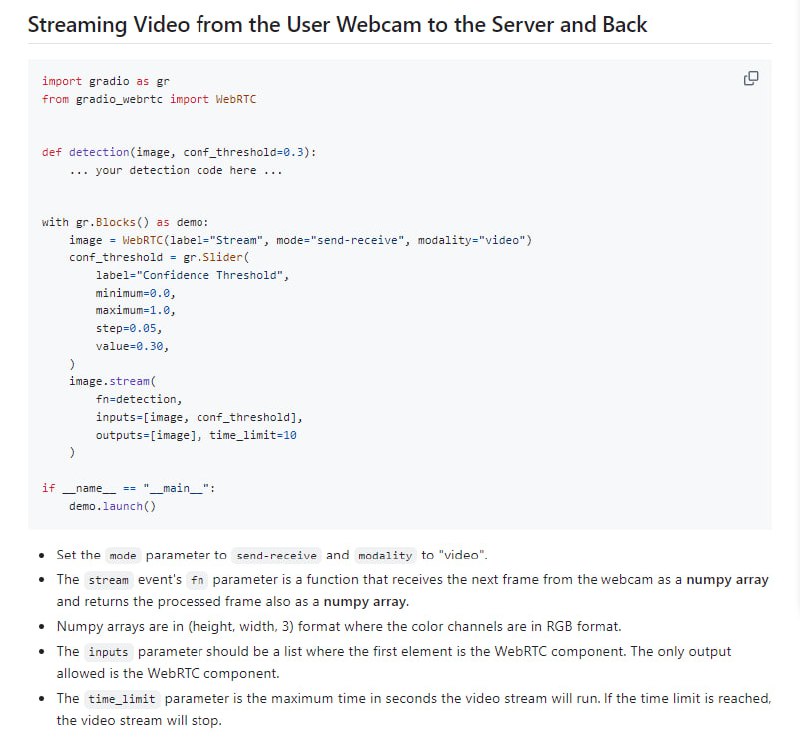
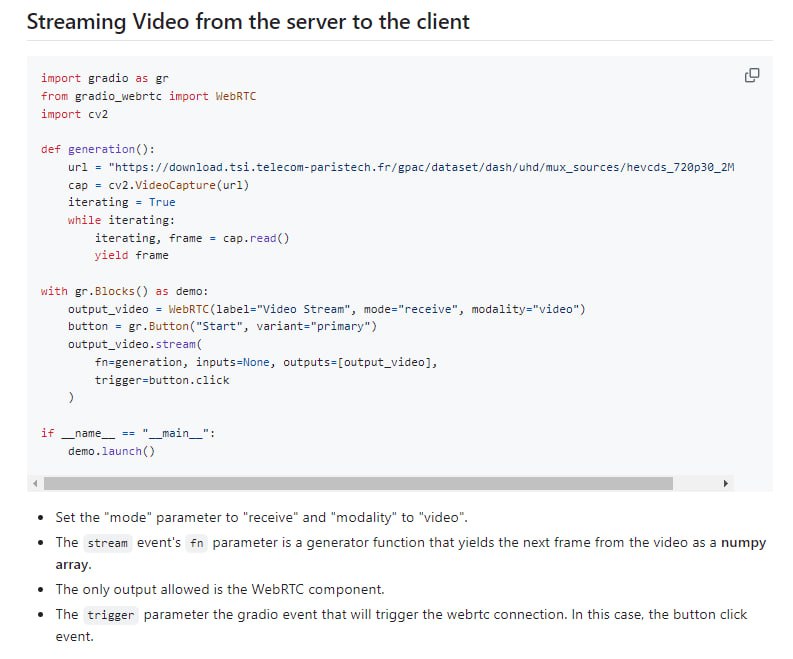
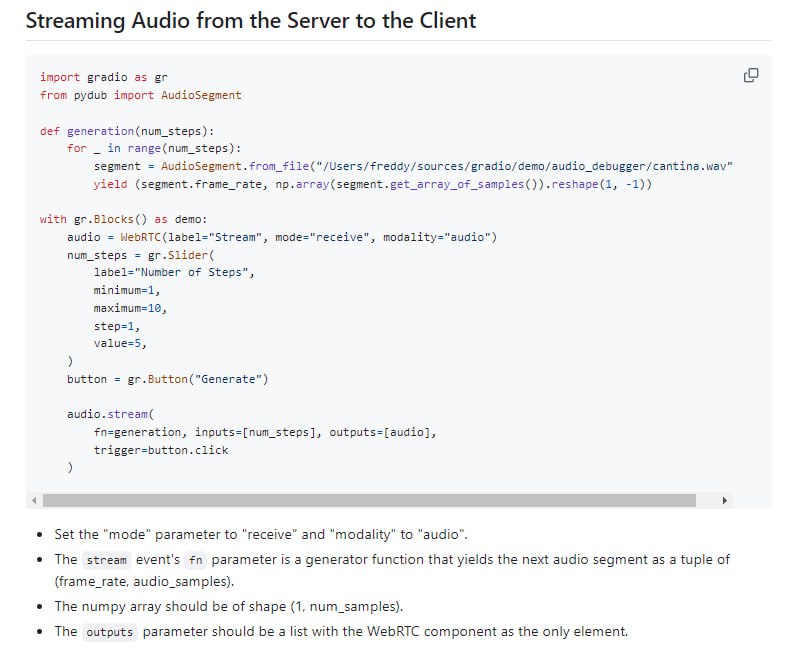
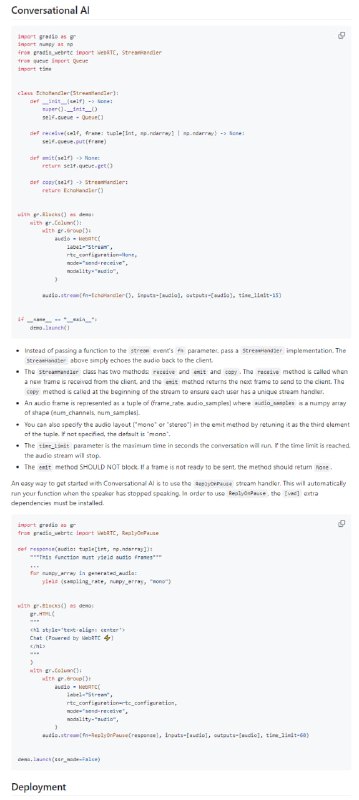
-
- 一个面向AI Agent的Stripe API集成工具库,支持Python和TypeScript,可与LangChain、CrewAI和Vercel AI SDK等主流AI Agent框架无缝对接。通过函数调用方式实现Stripe支付API的智能化集成,并支持计量计费功能。
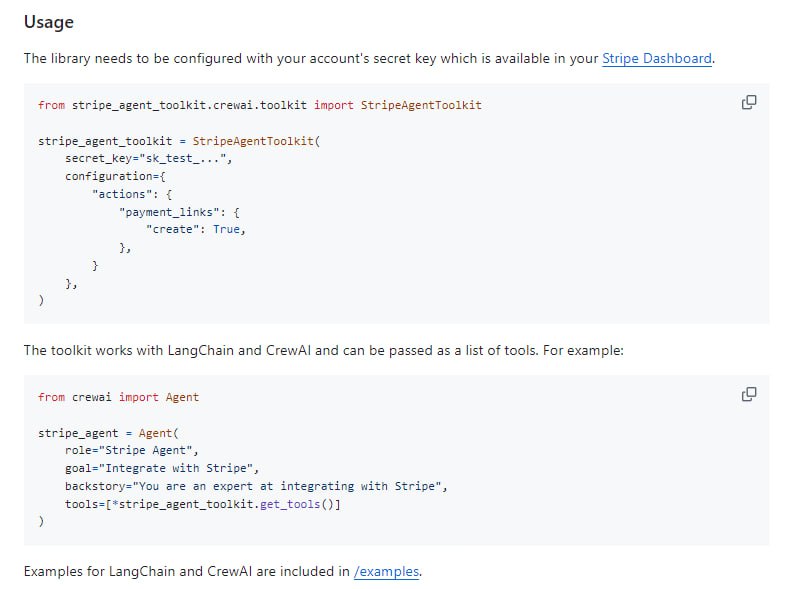
Stripe Agent Toolkit | #工具 -

- 一篇介绍编译器优化的文章

主要介绍了编译器优化的概念、实例和技术,旨在以易于理解的语言向读者解释编译器优化的工作原理和它们对代码的影响。
具体内容包括优化的类型、优化时的考虑因素以及编译器如何在不同优化级别下对代码进行优化。
作者通过实例演示了编译器如何优化算术运算、消除公共子表达式、处理未优化的构建、进行内联、进行强度降低优化以及在编译时进行优化和消除死码。还探讨了编译器在处理浮点运算时的精度问题,以及如何通过调整编译器选项来影响优化结果。 - 搜索引擎中广泛使用的文档排序算法——BM25(Best Matching 25)原理介绍 | blog

- 中国独立开发者项目列表:一个展示中国独立开发者作品的精选合集,收录了1000多个优秀项目,涵盖AI工具、效率软件、浏览器插件、游戏开发等多个领域。项目按类别整理,每个项目都包含开发者、项目名称、链接和简介等详细信息

-

- 黑马程序员-2024年11月AI版Java全栈开发课程
-
- 学习如何设计大型系统 | The System Design Primer
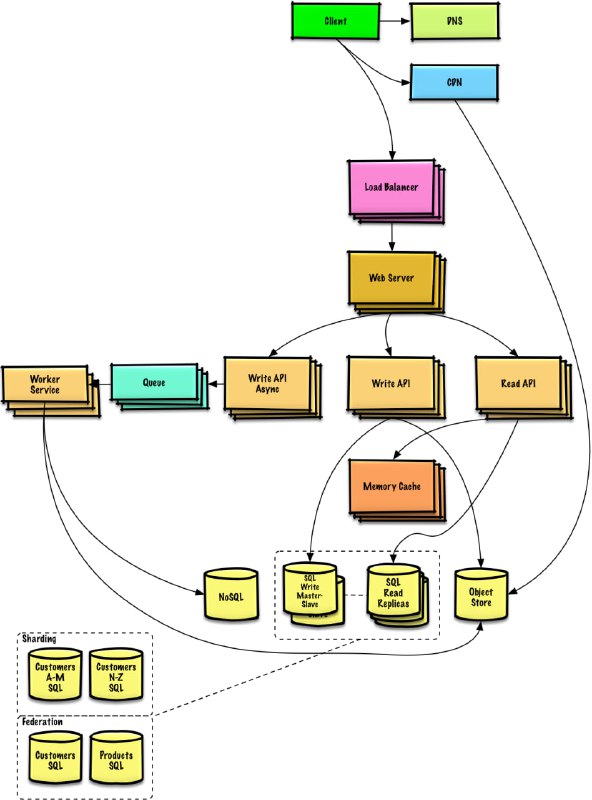
学习如何设计可扩展的系统将会有助于你成为一个更好的工程师。
系统设计是一个很宽泛的话题。在互联网上,关于系统设计原则的资源也是多如牛毛。
这个仓库就是这些资源的组织收集,它可以帮助你学习如何构建可扩展的系统。 - bRAG-langchain: 构建企业级 RAG 系统指南 | #指南
![bRAG-langchain: 构建企业级 RAG 系统指南 | #指南项目通过 5 个循序渐进的 Jupyter notebooks,指导开发者从零开始构建、优化和部署企业级 RAG 系统,涵盖从基础配置到高级技术(如多查询、语义路由、重排序等)的全过程实践项目的核心价值:1. 提供了一个从入门到高级的完整 RAG 实现教程2. 使用 @LangChainAI 框架构建3. 包含了多个进阶技术的实现示例项目包含 5 个主要教程笔记本,按难度递进:1. 基础设置概述 ([1]_rag_setup_overview.ipynb)- 环境配置- 数据加载和预处理- 使用 OpenAI 生成嵌入- 向量数据库(ChromaDB/Pinecone)设置- 基础 RAG 管道搭建2. 多查询技术 ([2]_rag_with_multi_query.ipynb)- 实现多查询检索- 使用多个嵌入模型- 对比单查询和多查询性能3. 路由和查询构建 ([3]_rag_routing_and_query_construction.ipynb)- 逻辑路由实现- 语义路由(用于数学/物理问题分类)- 结构化搜索模式- 向量存储集成4. 索引和高级检索 ([4]_rag_indexing_and_advanced_retrieval.ipynb)- 多表示索引- 文档摘要存储- ColBERT 集成- RAPTOR 实现5. 检索和重排序 ([5]_rag_retrieval_and_reranking.ipynb)- RAG-Fusion 多查询生成- 倒数排名融合(RRF)- @cohere重排序- CRAG 和 Self-RAG 检索](/static/https://cdn5.telesco.pe/file/dZxdd2CtMKgTB-6IFDN3y2krbcul95x_jNIGBgRUm9TomQFrujrqCiZ2JKGHvNnNEqcEAeQJTQEZGjYbDJbbqTtqBKilLj1uaFQGHePv4UKgWT5keNHMRc45pVJnqEm4hzp2kfwMFNt-iapukZ27VWBRCADDxjKkB5MWp7F7_PWhkBRdjleM19C1UThMhwmSJD_IZcxE7Crmua8VwwuE_c6bH3nLFwbBQHa15J0JI5YVLo0LsEmbeuvr100ZRmRycXrbCZ3wliLnuc_86HvLhWb29DtBet_M9gxmrXy47jZiENLns78Mt7RSPiY2hh9dxFQ1Eb9gQ73BagltNHmKOg.jpg)
项目通过 5 个循序渐进的 Jupyter notebooks,指导开发者从零开始构建、优化和部署企业级 RAG 系统,涵盖从基础配置到高级技术(如多查询、语义路由、重排序等)的全过程实践
项目的核心价值:
1. 提供了一个从入门到高级的完整 RAG 实现教程
2. 使用 @LangChainAI 框架构建
3. 包含了多个进阶技术的实现示例
项目包含 5 个主要教程笔记本,按难度递进:
1. 基础设置概述 ([1]_rag_setup_overview.ipynb)
- 环境配置
- 数据加载和预处理
- 使用 OpenAI 生成嵌入
- 向量数据库(ChromaDB/Pinecone)设置
- 基础 RAG 管道搭建
2. 多查询技术 ([2]_rag_with_multi_query.ipynb)
- 实现多查询检索
- 使用多个嵌入模型
- 对比单查询和多查询性能
3. 路由和查询构建 ([3]_rag_routing_and_query_construction.ipynb)
- 逻辑路由实现
- 语义路由(用于数学/物理问题分类)
- 结构化搜索模式
- 向量存储集成
4. 索引和高级检索 ([4]_rag_indexing_and_advanced_retrieval.ipynb)
- 多表示索引
- 文档摘要存储
- ColBERT 集成
- RAPTOR 实现
5. 检索和重排序 ([5]_rag_retrieval_and_reranking.ipynb)
- RAG-Fusion 多查询生成
- 倒数排名融合(RRF)
- @cohere重排序
- CRAG 和 Self-RAG 检索 -