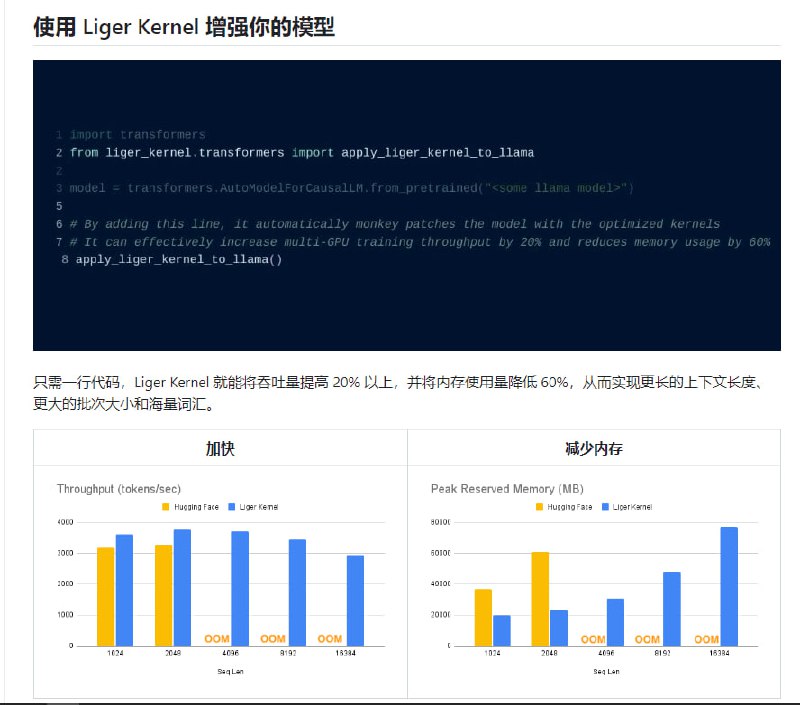
Liger-Kernel:为大型语言模型训练设计的高效 Triton 内核,通过一行代码提升模型性能,降低内存使用,支持更长上下文长度、更大批量大小和庞大词汇量
主要特点
易于使用:只需用一行代码修补您的 Hugging Face 模型,或者使用我们的 Liger Kernel 模块组成您自己的模型。
时间和内存效率高:与 Flash-Attn 秉承同样的精神,但适用于RMNSNorm、RoPE、SwiGLU和CrossEntropy等层!通过内核融合、就地替换和分块技术,可将多 GPU 训练吞吐量提高 20%,并将内存使用量降低 60% 。
精确:计算精确——无近似值!前向和后向传递均通过严格的单元测试实现,并在没有 Liger Kernel 的情况下针对训练运行进行收敛测试,以确保准确性。
轻量级: Liger Kernel 的依赖性极小,只需要 Torch 和 Triton — 无需额外的库!告别依赖性烦恼!
支持多 GPU:兼容多 GPU 设置(PyTorch FSDP、DeepSpeed、DDP 等)。
目标受众
研究人员:寻求使用高效可靠的内核为前沿实验构建模型。
ML 从业者:专注于通过最佳、高性能内核最大化 GPU 训练效率。
新手:渴望学习如何编写可靠的 Triton 内核以提高训练效率。