黑洞资源笔记
- RigelA - 用纯Rust编写的读屏(Screen Reader)项目,用于视力有障碍的人群操作电脑,软件会将屏幕上的各种信息转换成语音输出
- LLM-And-More:一站式大模型训练及应用构建的解决方案,其覆盖了从数据处理到模型评估、从训练到部署、从想法到服务等整个流程。在本项目中,用户可以轻松地通过本项目进行模型训练并一键生成所需的产品服务。
本项目的优势主要体现在以下三点:
总结了不同应用场景下的专业知识和最佳实践,以保证模型在实际生产中的表现优异。
集成了高性能模型并行框架,有效地减少了训练和推理时的算力开销。
用户可以基于自身需要定制化模型及服务,便捷且自由度高。 - 从零开始学习深度强化学习的实践课程 | link
- 面向音乐信息检索的大型语言模型教程 | LLMs heart MIR
- B-MoCA:用于评估移动设备控制Agent在不同配置下性能的基准测试平台
- MLX-VLM:在 Mac 上使用 MLX 运行视觉语言模型(Vision LLM)的包
- MuPDF.js:为 JavaScript 和 TypeScript 构建的 MuPDF 库,利用 WebAssembly 提供快速和高效的 PDF 操作功能
- kvql:为通用键值数据库设计的类似 SQL 的查询语言
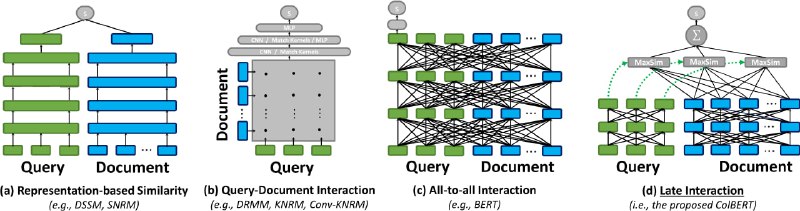
- RAG-Retrieval:开源的Python库,旨在统一高效微调RAG检索模型,包括嵌入、ColBERT和交叉编码器模型,支持多种排序模型并优化长文档处理
-
-
- Mu-Transformer:使用 Jax/Flax 实现的 Transformer 模型,支持 Mu-Parameterization,能在 TPU pods 上运行 FSDP
-
- CCML:用C语言编写的简单自动微分库,旨在教育性地展示计算科学中各种概念的实现细节

- 在线免费教程《命令行中的数据科学》第二版

这本经过彻底修订的指南演示了命令行的灵活性如何帮你成为更高效、更有生产力的数据科学家。 你将学习如何结合小而强大的命令行工具来快速获取、清理、探索和建模数据。 为了让你快速入门,作者 Jeroen Janssens 提供了一个包含 100 多个 Unix 强大工具的 Docker 映像,无论使用 Windows、macOS 还是 Linux,该工具都非常有用。
本书非常适合数据科学家、分析师、工程师、系统管理员和研究人员。 -
- Programming Massively Parallel Processors Fourth Edition | 大规模并行处理器编程实战

这是一本关于并行计算的重要参考书籍。第四版应该还没有中文版引进。这里有部分(目前是前八章)翻译。
本书分为四个部分。
第一部分涵盖了并行编程、数据并行性、GPU和性能优化的基本概念。这些基础章节为读者提供了成为GPU程序员所必需的基本知识和技能。(目前内容主要是这部分)
第二部分涵盖了基本并行模式;第三部分涵盖了更高级的并行模式和应用。这两部分应用了第一部分学到的知识和技能,并在需要时介绍其他GPU架构特性和优化技术。
最后一部分介绍了高级实践,以完成那些想要成为专业GPU程序员的读者的知识体系。 - StoryDiffusion 是一个开源的图像和视频生成模型,它通过一致自注意力机制和运动预测器,能够生成连贯的长序列图像和视频。
这个模型的主要优点在于它能够生成具有角色一致性的图像,并且可以扩展到视频生成,为用户提供了一个创造长视频的新方法。该模型对AI驱动的图像和视频生成领域有积极的影响,并且鼓励用户负责任地使用该工具。
使用场景示例:
使用StoryDiffusion生成一系列漫画风格的图像。
创建一个基于文本提示的长视频,展示一个连贯的故事。
利用StoryDiffusion进行角色设计和场景布局的预可视化。
产品特色:
一致自注意力机制:生成长序列中的角色一致图像。
运动预测器:在压缩的图像语义空间中预测运动,实现更大的运动预测。
漫画生成:利用一致自注意力机制生成的图像,无缝过渡创建视频。
图像到视频的生成:提供用户输入的条件图像序列来生成视频。
两阶段长视频生成:结合两个部分生成非常长且高质量的AIGC视频。
条件图像使用:图像到视频模型可以通过提供一系列用户输入的条件图像来生成视频。
短视频生成:提供快速的视频生成结果。
产品入口 | 在线体验 -