黑洞资源笔记
-
-
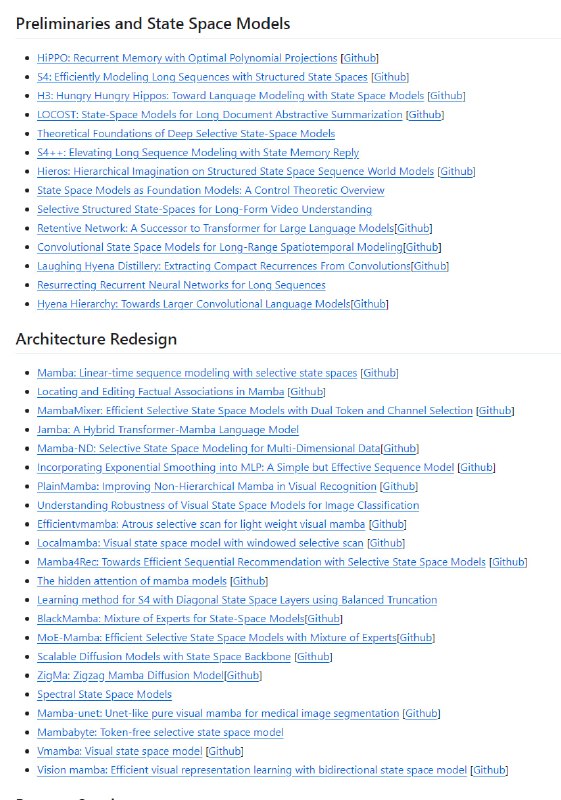
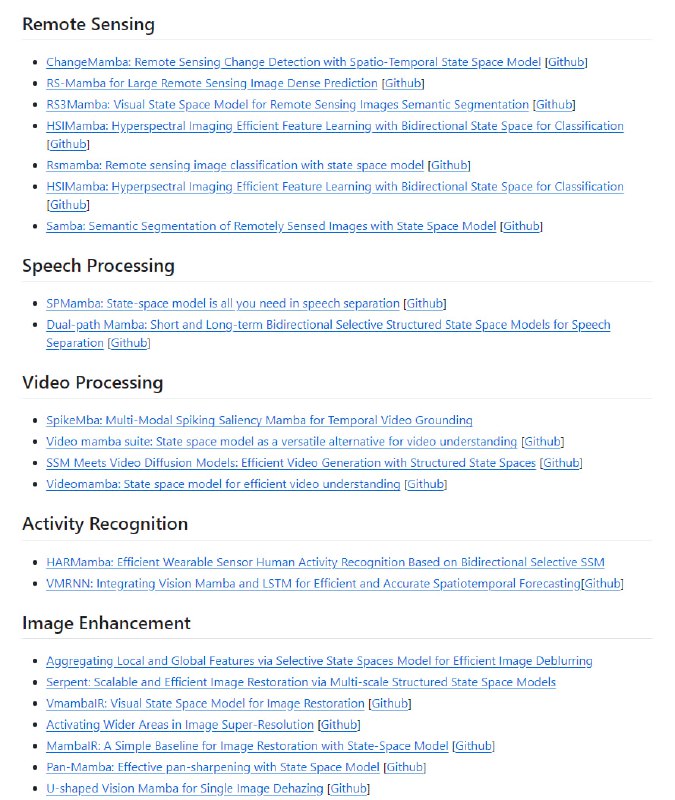

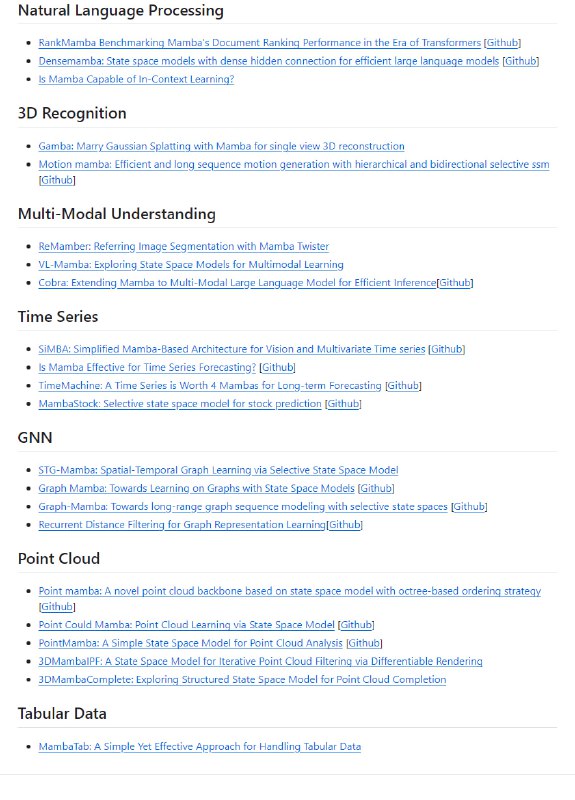
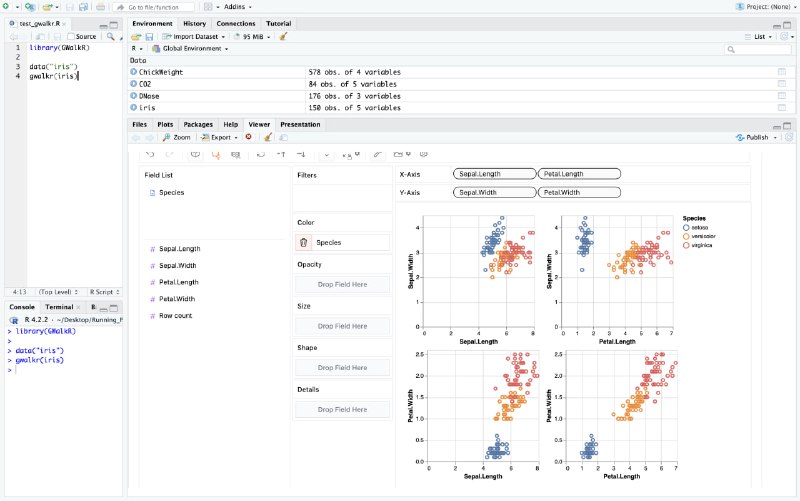
- DeepBI:AI原生的数据分析平台,DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据,用户可以使用DeepBI洞察数据并做出数据驱动的决策
-
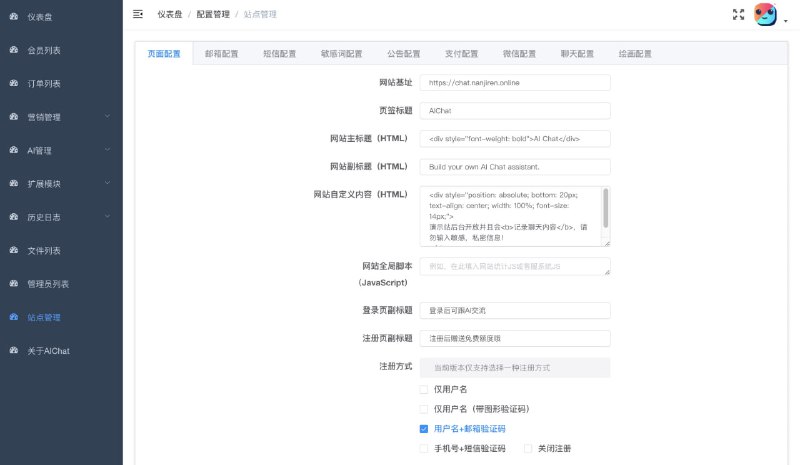
- GPT-AI-Code-Interpreter:基于云运行时的 Python & JavaScript SDK,用于构建自定义代码解释器。它支持 LLM(如 OpenAI、Cohere 和 Anthropic)生成的代码块之间的状态共享,允许用户逐步执行代码,并支持图表输出等功能
- AudioCraft:用于深度学习音频生成研究的PyTorch库
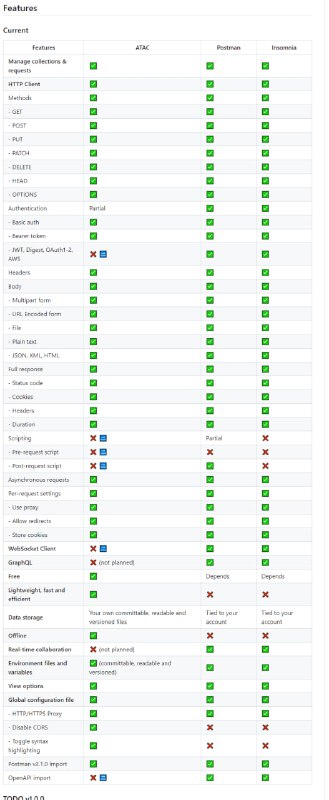
- ATAC:命令行简单API客户端(类似postman)
-

- SRGS: Super-Resolution 3D Gaussian Splatting

通过高分辨率密集化和纹理学习,提出一种只需低分辨率多视图输入就可以实现高质量高分辨率小场景新视图合成的方法SRGS。 - Pile-T5:更好的通用预训练语言模型

Pile-T5通过在Pile数据集上预训练T5模型,并使用LLAMA分词器,改进了原始T5的编码能力。
Pile-T5总体上明显优于原始T5v1.1模型,尤其在代码任务上的提升更大。这主要得益于Pile中包含代码数据以及LLAMA分词器包含编程常用字符。
在多个下游任务的微调中,Pile-T5不同规模的模型表现优异,如在SuperGLUE、CodeXGLUE、MMLU和BigBench Hard上的结果。
尽管与专门微调的Flan-T5相比略逊色,但Pile-T5仍优于T5v1.1,表明其预训练质量更高,更适合多任务微调。
公开了Pile-T5模型在不同训练步长的中间检查点,这有利于模型演化和解释性研究。
Pile-T5 Large模型在某些任务上的表现不佳,可能存在bug,用户需谨慎使用。 - Mistral AI发布了新的开源模型Mixtral 8x22B。该模型以39B活跃参数实现141B参数规模,极大提升了模型规模与成本效率。
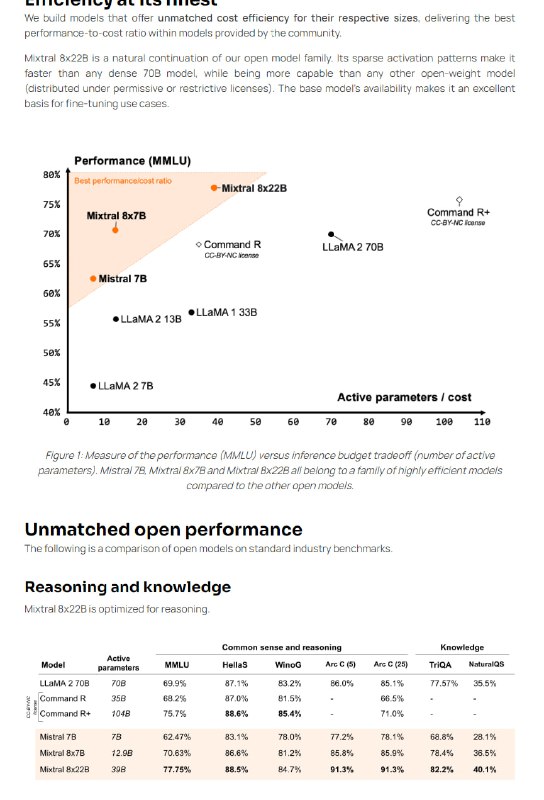
Mixtral 8x22B支持英语、法语、意大利语、德语和西班牙语,并具有强大的数学和编程能力。其支持函数调用,可大规模实现应用开发和技术栈现代化。
Mistral AI坚信开源的力量,Mixtral 8x22B以最宽松的Apache 2.0许可证发布。
Mistral AIModels追求卓越的成本效率。Mixtral 8x22B相较同规模模型,提供最佳的性能价格比。其稀疏激活可提升速度。
Mixtral 8x22B在推理、知识、多语言、编程、数学等多个基准测试上,表现优于其他开源模型。后续会发布指导版本,数学表现更佳。