黑洞资源笔记
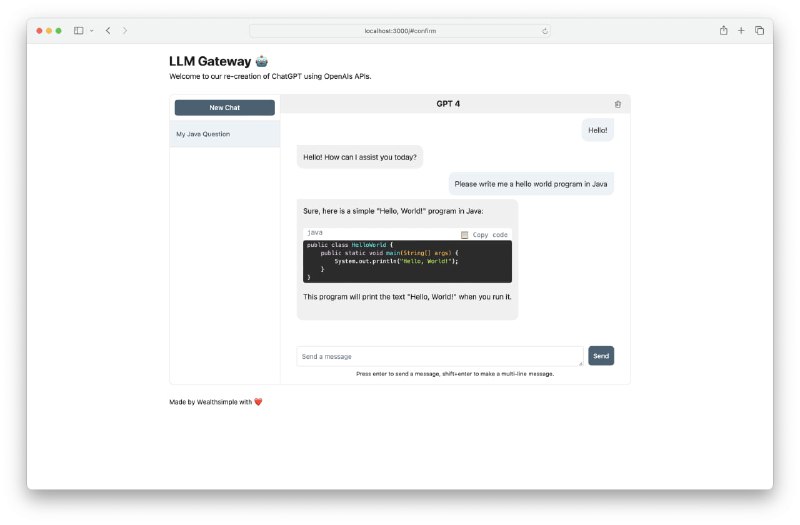
- LLM Gateway:用于安全可靠地与 OpenAI 和其他 LLM(语言模型)提供商进行通信的网关
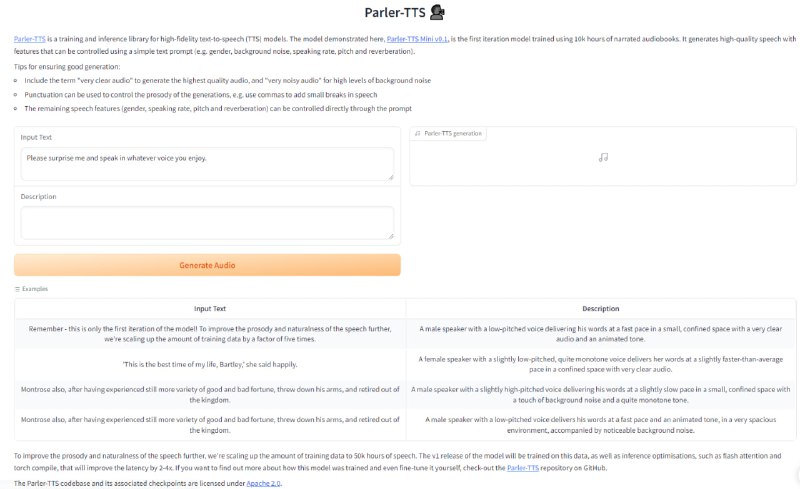
- Parler-TTS:开源的轻量级文本到语音(TTS)模型,可以生成高质量、自然流畅的语音,模仿给定的演讲者(性别、音高、说话风格等
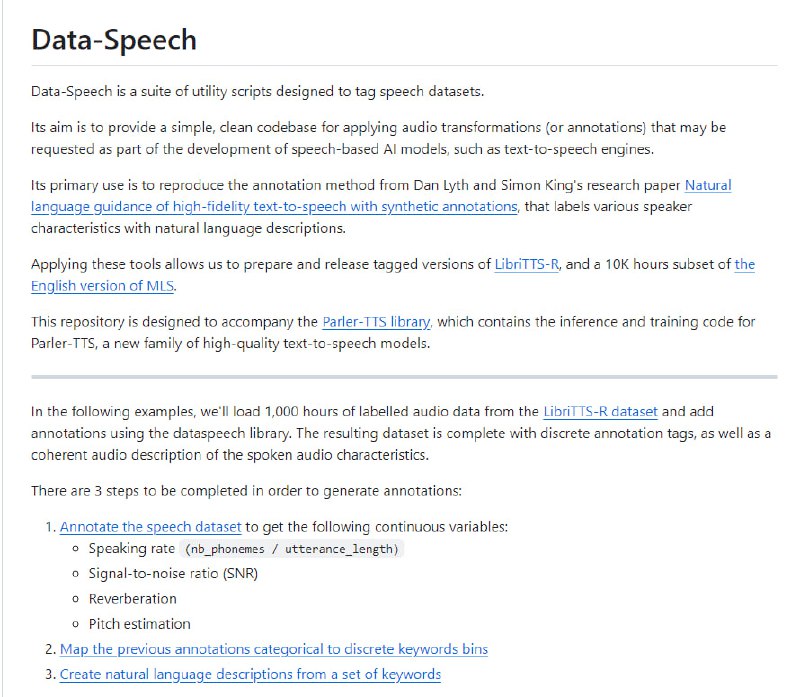
- Data-Speech:用于标注语音数据集的实用脚本套件,旨在为基于语音的人工智能模型(如文本到语音引擎)开发过程中所需要的音频变换(或注释)提供简洁、干净的代码库
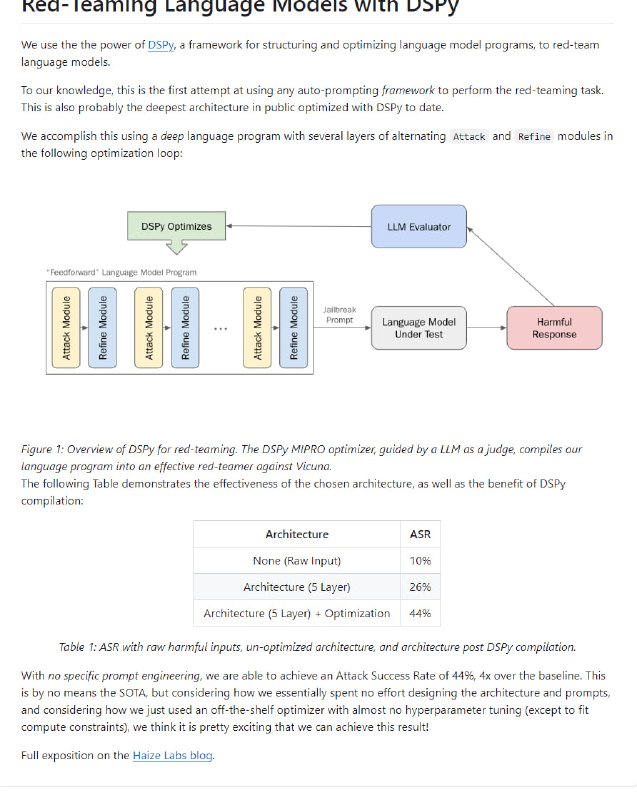
- Red-Teaming Language Models with DSPy:介绍了使用 DSPy 框架对语言模型进行红队攻击的尝试,展示了用 DSPy 编译后的架构效果
- OmniFusion:高级的多模态 AI 模型,旨在通过集成其他数据模态(如图像、音频、3D 和视频内容)来扩展传统语言处理系统的功能。
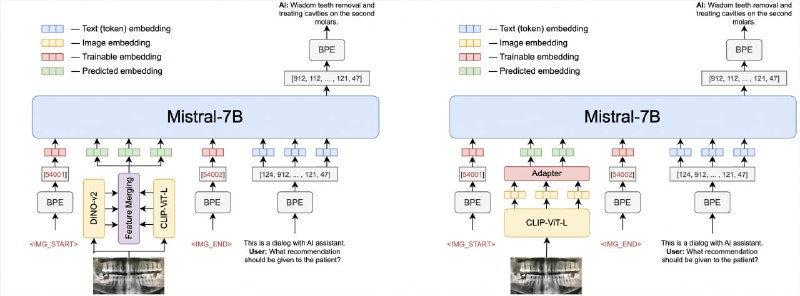
开源 OmniFusion 核心是 Mistral-7B。该模型有两个版本:第一个使用一个视觉编码器 CLIP-ViT-L,第二个使用两个编码器(CLIP-ViT-L 和 Dino V2)。最初专注于图像,我们选择 CLIP-ViT-L 作为视觉编码器,因为它具有高效的信息传输能力。
OmniFusion 最重要的组件是它的适配器,这是一种允许语言模型解释和合并来自不同模式的信息的机制。对于单编码器版本,适配器是单层四头变压器层,与更简单的线性层或 MLP 结构相比,它表现出了卓越的性能。具有两个编码器的模型使用一个适配器,该适配器从视觉编码器的所有层收集特征,该适配器没有注意层。
该适配器从视觉编码器(不包括 CLS 令牌)获取嵌入,并将它们映射到与语言模型兼容的文本嵌入。 - 用于评估语言模型准确性的轻量库,包含多个评估,如 MMLU、MATH、GPQA、DROP、MGSM 和 HumanEval,并为 OpenAI 和 Anthropic API 提供了采样接口 | github
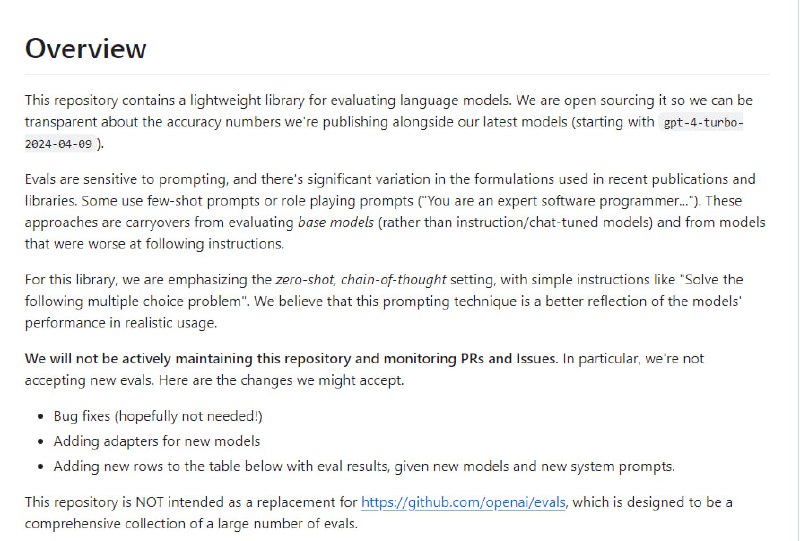
-

-
- PCToolkit: 统一的即插即用大语言模型提示压缩工具包
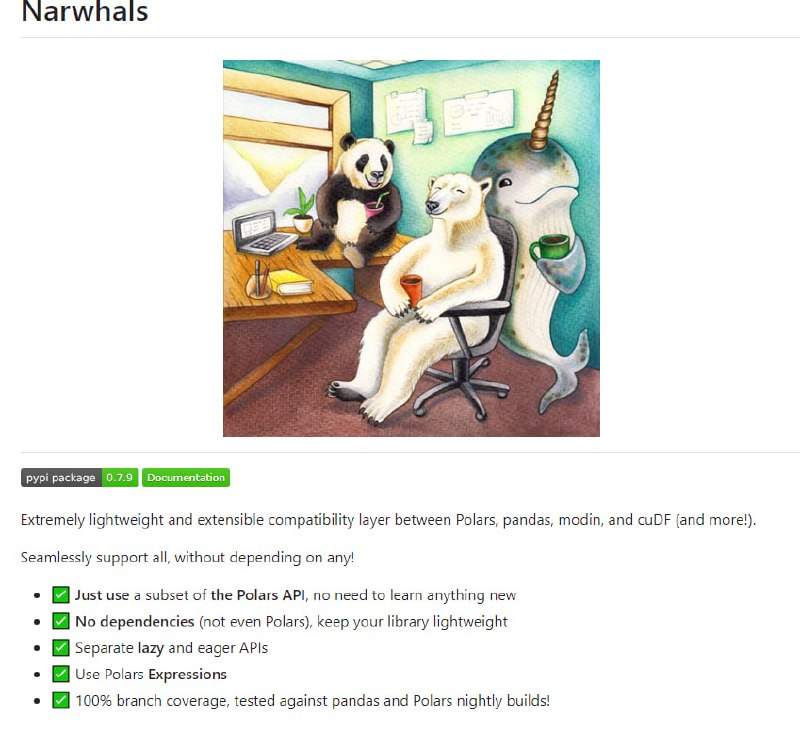
- Narwhals:轻量可扩展的数据框架兼容层,支持 Polars、pandas、cuDF、Modin 等多种数据框架
-


- 谢公子-域渗透攻防 1-6章
-








