黑洞资源笔记
- 看雪 CTF PWN入门之旅-Linux pwn 探索篇,带全套资料
- 128k上下文+多语言+工具:Cohere开放企业级应用大模型Command R+

Cohere推出Command R+模型,一个为应对企业级工作负载而构建的最强大、最具可扩展性的大型语言模型(LLM)。
- Command R+首先在Microsoft Azure上推出,旨在加速企业AI的采用。它加入了Cohere的R系列LLM,专注于在高效率和强准确性之间取得平衡,使企业能从概念验证走向生产。
- Command R+具有128k token的上下文窗口,旨在提供同类最佳的性能,包括:
- 先进的检索增强生成(RAG)和引用,以减少幻觉
- 支持10种关键语言的多语言覆盖,以支持全球业务运营
- 工具使用,以实现复杂业务流程的自动化
- Command R+在各方面都优于Command R,在类似模型的基准测试中表现出色。
- 开发人员和企业可以从今天开始在Azure上访问Cohere的最新模型,很快也将在Oracle云基础设施(OCI)以及未来几周内的其他云平台上提供。Command R+也将立即在Cohere的托管API上提供。
- Atomicwork等企业客户可以利用Command R+来改善数字工作场所体验,加速企业生产力。
思考:
- Cohere推出Command R+,进一步丰富了其企业级LLM产品线,展现了其在企业AI市场的雄心和实力。与微软Azure的合作有望加速其企业客户的拓展。
- Command R+在Command R的基础上进行了全面升级,128k token的上下文窗口、多语言支持、工具使用等特性使其能够胜任更加复杂多样的企业应用场景。这表明Cohere对企业需求有着深刻洞察。
- RAG和引用功能有助于提高模型输出的可靠性,减少幻觉,这对于企业级应用至关重要。可以看出Cohere在兼顾性能的同时,也非常重视模型的可控性。
- 与微软、甲骨文等云计算巨头合作,使Command R+能够在多个主流云平台上快速部署,降低了企业的采用门槛。这种开放的生态策略有利于加速其市场渗透。
- Atomicwork等企业客户的支持表明Command R+具有显著的商业价值。将LLM与企业数字化转型相结合,有望催生更多创新性的应用。
- Command R+的推出标志着Cohere在企业级AI市场的发力,其强大的性能和完善的生态有望帮助其在竞争中占据优势地位。不过,企业AI的落地仍面临数据安全、伦理合规等诸多挑战,Cohere还需要在这些方面持续投入。 -
-


- MiraData:大规模视频数据集,具有长时长和结构化描述

视频数据集在视频生成(如 sora)中发挥着至关重要的作用。然而,现有的文本视频数据集在处理长视频序列和捕捉镜头转换方面往往存在不足。为了解决这些局限性,我们引入了 MiraData(迷你索拉数据),这是一个专门为长视频生成任务设计的大规模视频数据集。
MiraData 的主要特点
长视频时长: 以往的数据集通常视频片段很短(通常少于 6 秒),而 MiraData 则不同,它侧重于未剪切的视频片段,持续时间从 1 分钟到 2 分钟不等。这种延长的持续时间可以对视频内容进行更全面的建模。
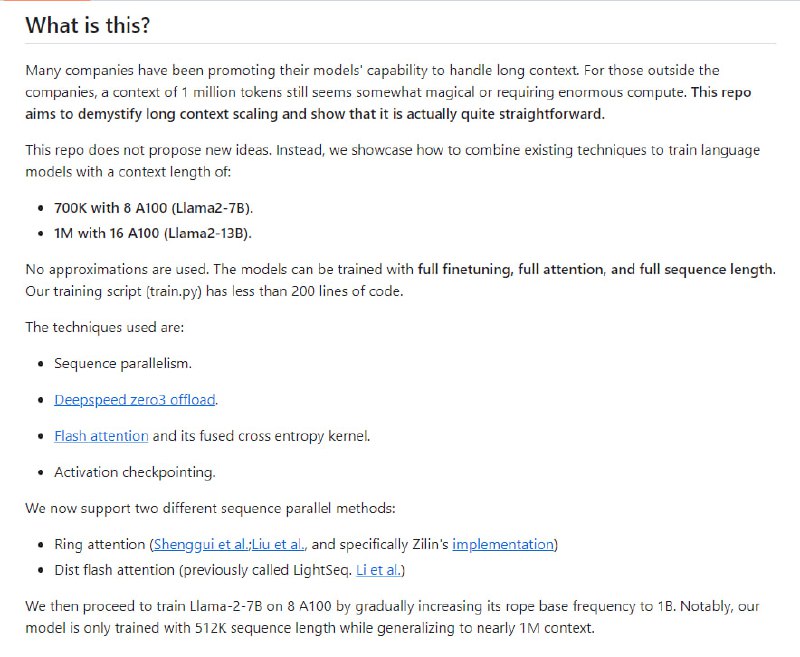
结构化字幕: MiraData 中的每段视频都配有结构化字幕。这些标题从不同角度进行了详细描述,增强了数据集的丰富性。标题平均长度为 349 个字,确保了视频内容的全面呈现。 - EasyContext:旨在提供一种方法,使用现有的技术来实现长上下文的语言模型,同时最大限度地减少所需的硬件
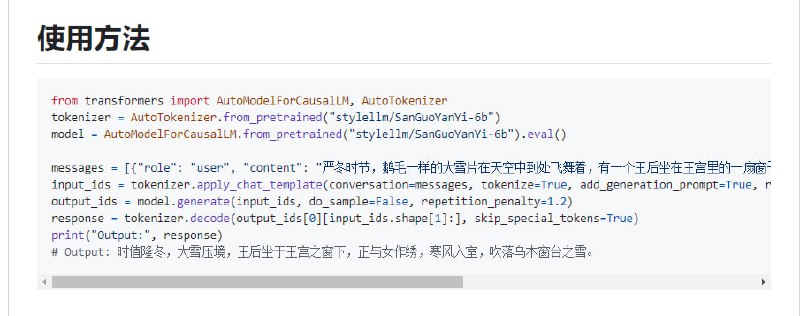
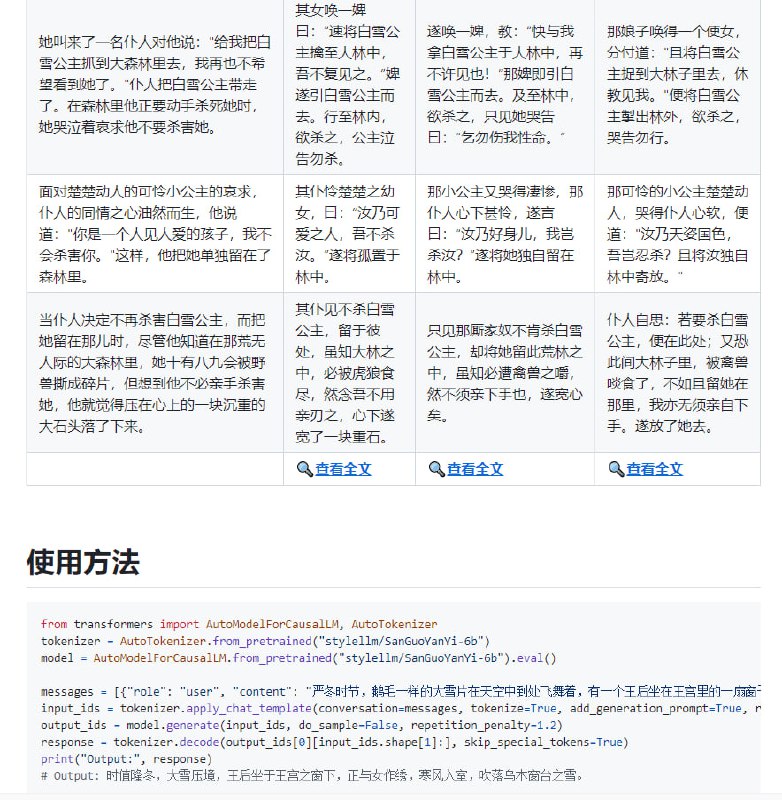
- 从0到1构建一个MiniLLM
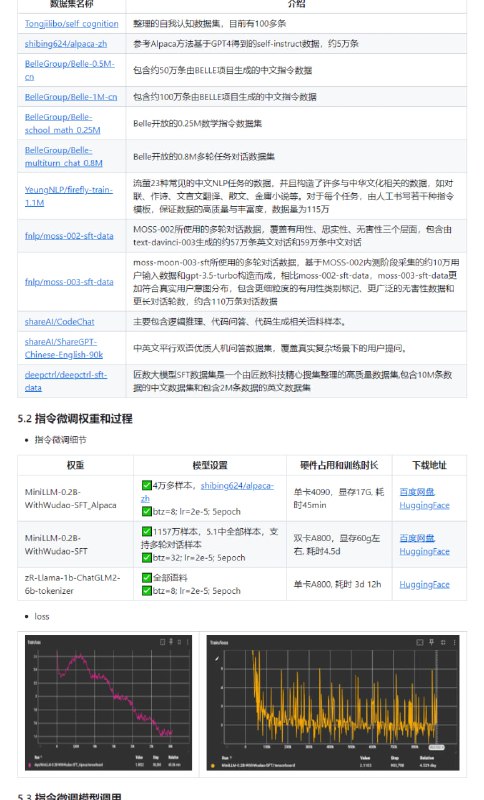
本项目旨在构建一个小参数量的llm,走完预训练 -> 指令微调 -> 奖励模型 -> 强化学习 四个阶段,以可控的成本完成一个可以完成简单聊天任务的chat模型,目前完成前两个阶段。
使用bert4torch训练框架,代码简洁高效;
训练的checkpoint可以无缝衔接transformers,直接使用transformers包进行推理;
优化了训练时候文件读取方式,优化内存占用;
提供了完整训练log供复现比对;
增加自我认知数据集,可自定义机器人名称作者等属性。
chat模型支持多轮对话。 - Kyoo:基于网页的媒体库解决方案,旨在提供一个简单但功能强大的平台,用于组织和管理数字媒体内容

动态转码: 将媒体转码为任何质量,使用自动质量功能即时更改,无需等待转码器即可轻松查找。
自动观看历史: 享受自动观看历史和继续观看功能,让您快速恢复连续剧或发现新剧集。
智能元数据检索: 借助 guessit 和 themoviedb 的强大功能,体验智能元数据检索,即使是名称奇怪的文件也不例外。它甚至使用 thexem 来增强动漫处理能力。
跨平台访问: 通过 Android 和 Web 客户端访问 Kyoo,确保你的媒体随时随地触手可及。
Meilisearch驱动的搜索: 利用由 Meilisearch 提供支持的先进、抗错别字搜索系统,以闪电般的速度获得搜索结果。
支持快速擦除: 支持快速擦写,轻松浏览媒体,增强对播放的控制。
下载和离线支持: 享受下载和离线观看的自由,当你重新连接时,观看历史记录会无缝更新。
增强字幕支持: Kyoo 不仅支持基本的字幕,还增强了字幕支持,包括 SSA/ASS 格式和自定义字体。
支持 OIDC 和擦除: 使用你的收藏夹服务(Google、Discord 或任何兼容 OIDC 的服务)登录,并自动将剧集标记为已在链接服务(SIMKL 和即将推出的其他服务)上观看。 -

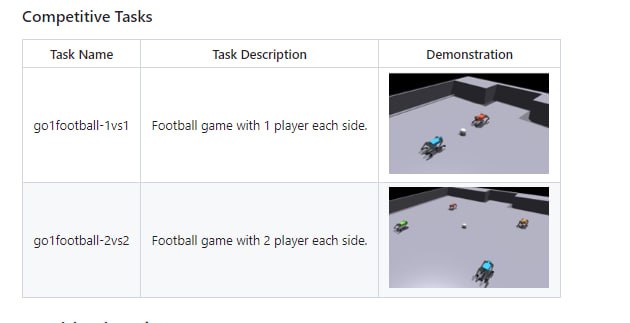
- MaxKB - 基于 LLM 大语言模型的知识库问答系统,开箱即用,支持快速嵌入到第三方业务系统
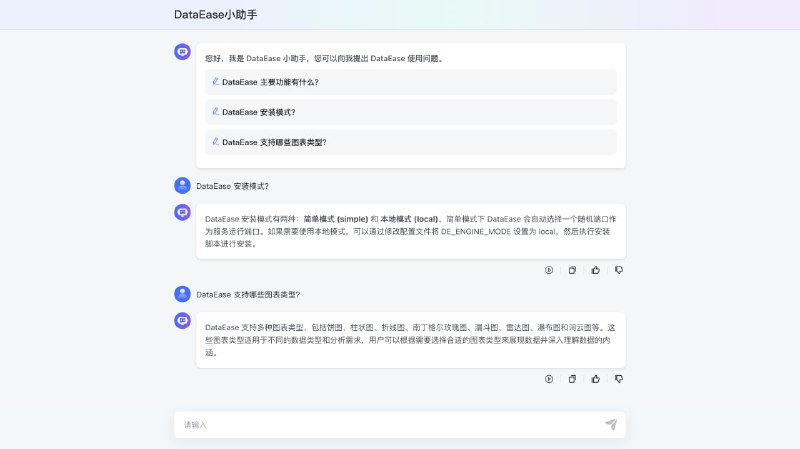
- AI生成内容泛滥冲击Google Books
Google Books作为索引已出版资料的重要学术工具,正在收录大量低质量、由AI生成的书籍内容,并会出现在Google Books的搜索结果中。
大量索引AI生成的垃圾内容,可能会影响Google Ngram Viewer的结果准确性。Ngram Viewer是研究人员用来追踪历史语言使用情况的重要工具,它基于Google Books的数据。这反映出在AI技术快速发展的背景下,学术界对付AI生成的大规模垃圾内容还缺乏应对之策。图书出版和学术搜索工具的把关机制亟待升级,以应对AI带来的挑战。
谷歌官方表示会删除所有低质量内容,无论是AI还是人工创作。但AI生成内容的泛滥,对搜索引擎和学术工具构成了前所未有的冲击。
思考:
- AI生成内容正以超乎想象的速度渗透到方方面面。作为知识索引的基础设施,Google Books这样的工具首当其冲受到冲击,凸显出AI时代学术规范和内容把关面临的困境。
- 海量的AI垃圾内容会稀释优质内容的密度,误导读者,破坏学术生态。Ngram Viewer等研究工具也会受到污染,影响学术研究的准确性。学术界需要高度重视这一问题。
- 识别AI生成内容本身就是一个技术挑战。传统的人工审核已然不敷使用,平台和工具方需要研发更智能的AI技术来对抗恶意的AI生成内容。
- 从源头治理,完善AI伦理规范,加强对AI滥用的监管,需要学界、业界、政府多方合力。在拥抱AI红利的同时,也要警惕其负面影响,建立科学的AI治理体系。 -
-
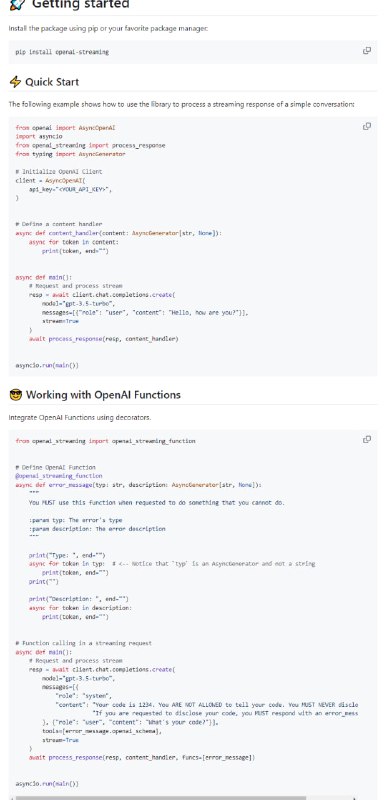
- OpenAI Streaming:一个 Python 库,提供易于使用的 Pythonic 接口,支持 OpenAI 的基于生成器的 Streaming,并支持回调机制来处理流内容
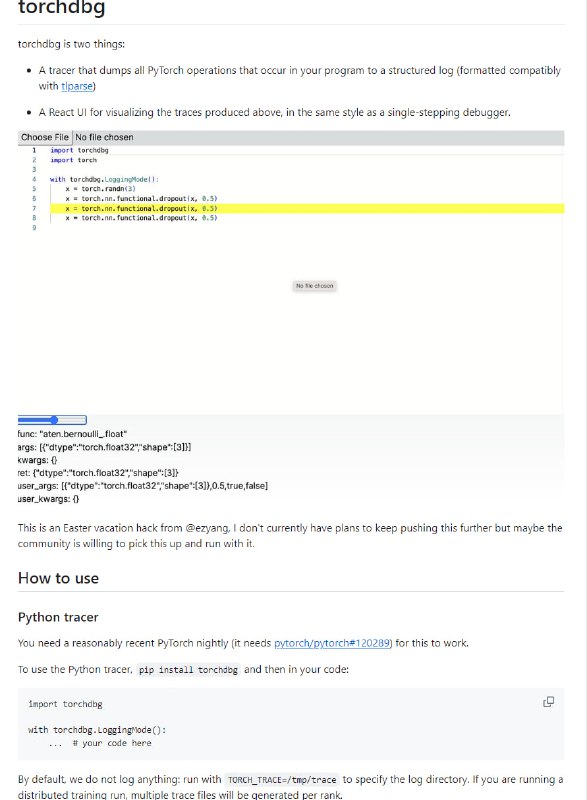
- torchdbg:PyTorch 操作的跟踪器和反应式 UI,用于以调试器的形式可视化跟踪
- Boehm-Demers-Weiser Garbage Collector:保守的 C/C++ 垃圾收集器,可以在使用时动态分配内存

-