黑洞资源笔记
-
-
- luminal:一个深度学习库,利用可组合的编译器实现高性能。它以极快的速度运行,支持Metal和CUDA,使用Rust编写,直接与底层API交互,无需中间层。
其核心思想是提前编译所有内容,采用静态计算图实现惰性执行,使得编译器可以全局优化,实现了高效的核心运算与编译时间的分离。 - 北京大学Yuangroup团队发起了一个 Open-Sora计划,旨在复现OpenAI 的Sora模型。
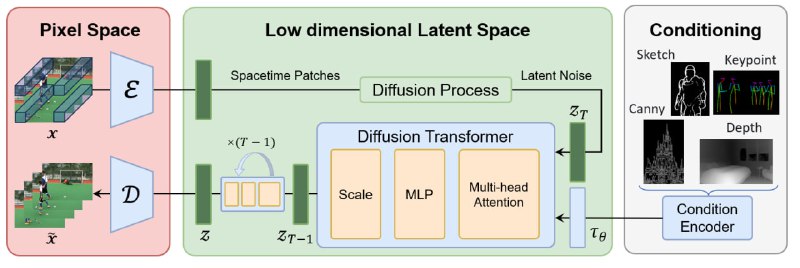
Open Sora Plan通过视频VQ-VAE、Denoising Diffusion Transformer和条件编码器等技术组件,来实现Sora模型的功能。
它由以下组成部分组成。
1. Video VQ-VAE.
2. Denoising Diffusion Transformer.
3. Condition Encoder. -

- LTX Studio:由AI驱动的一键生成电影
只需要输入简单的文字提示和创意,它就能帮你生成完整的剧本,同时将剧本直接转化为视频。
利用AI,它可以精确指导每个场景,包括特定的摄像机角度、生成一致性的角色演员、修改场景、背景、造型等。仅需一键,即可创建包含特效、音乐和旁白的最终剪辑。
LTX Studio正在开创AI与视频制作整合的先河,使单一的想法能够转化为连贯的、由AI生成的视频。主要功能:
框架控制:利用专门的AI,精确指导每个场景,包括特定的摄像机角度。
AI叙事:将一个简单的想法或完整的剧本转化为详细的视频制作。
角色一致性:生成角色并在各个帧中保持身份和风格的一致性。
自动剪辑:仅需一键,即可创建包含特效、音乐和旁白的视频项目的最终剪辑。 - 作为 2024 开年王炸,Sora 的出现树立了一个全新的追赶目标,每个文生视频的研究者都想在最短的时间内复现 Sora 的效果。
最近,新加坡国立大学尤洋团队开源的一个名为 OpenDiT 的项目为训练和部署 DiT 模型打开了新思路。
OpenDiT 是一个易于使用、快速且内存高效的系统,专门用于提高 DiT 应用程序的训练和推理效率,包括文本到视频生成和文本到图像生成。 | 详文 - Sora:探索大型视觉模型的前世今生、技术内核及未来趋势 | blog

Sora,一款由 OpenAI 在 2024 年 2 月推出的创新性文转视频生成式 AI 模型,能够依据文字说明,创作出既真实又富有想象力的场景视频,展现了其在模拟现实世界方面的巨大潜能。
本文基于公开技术文档和逆向工程分析,全面审视了 Sora 背后的技术背景、应用场景、当前面临的挑战以及文转视频 AI 技术的未来发展方向。
文章首先回顾了 Sora 的开发历程,探索了支撑这一“数字世界构建者”的关键技术。接着探讨了 Sora 在电影制作、教育、市场营销等多个领域内的应用潜力及其可能带来的影响。
文章还深入讨论了为实现 Sora 的广泛应用需克服的主要挑战,例如保证视频生成的安全性和公正性。
最后展望了 Sora 乃至整个视频生成模型技术未来的发展趋势,以及这些技术进步如何开创人机互动的新方式,进而提升视频创作的效率和创新性。 - Hugging Face挂了
-
- SSH客户端的替代品,除了提供标准功能外,还增加了诸如登录提示、trzsz(trz / tsz)、批量登录、记住密码、zmodem(rz / sz)等实用功能
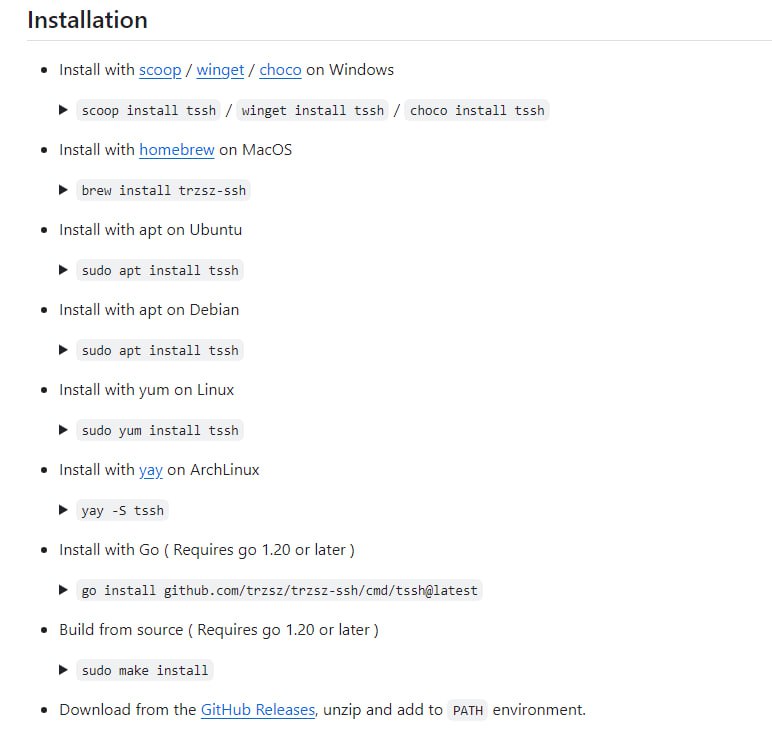
trzsz-ssh ( tssh ) | #替代品 -




-
- SDXL Lightning:超快的SDXL文本到图像合成。它可以通过几个步骤生成高质量的 1024px 图像。
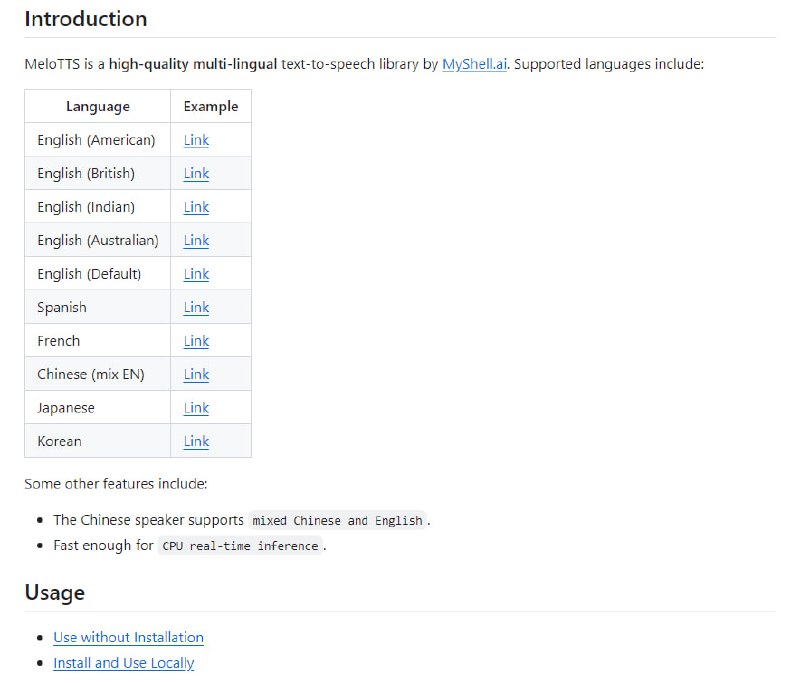
- MeloTTS:高质量多语言文本转语音库。支持多种语言,其中包括英语(美国、英国、印度、澳大利亚等)、西班牙语、法语、中文、日语和韩语等。其特色包括支持中英文混合朗读,CPU实时推理速度快等
- TableQAKit: 用于表格问答的工具包,支持LLM模型,提供可扩展的设计、全面的数据集和强大的方法,支持LLM的提示和微调方法、统一的数据接口、可复现的SOTA方法以及高效的LLM评估