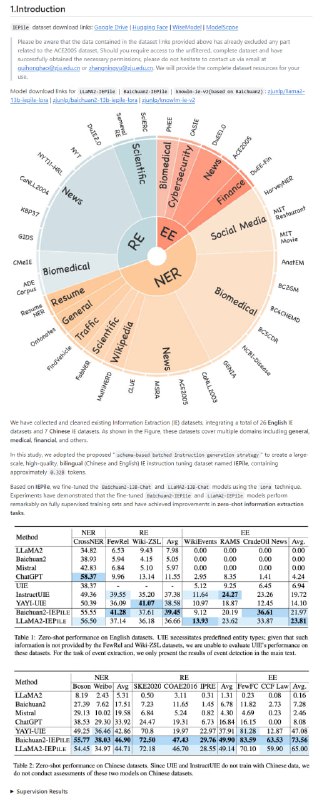
黑洞资源笔记
-
- SDXL Lightning:超快的SDXL文本到图像合成。它可以通过几个步骤生成高质量的 1024px 图像。
- MeloTTS:高质量多语言文本转语音库。支持多种语言,其中包括英语(美国、英国、印度、澳大利亚等)、西班牙语、法语、中文、日语和韩语等。其特色包括支持中英文混合朗读,CPU实时推理速度快等
- TableQAKit: 用于表格问答的工具包,支持LLM模型,提供可扩展的设计、全面的数据集和强大的方法,支持LLM的提示和微调方法、统一的数据接口、可复现的SOTA方法以及高效的LLM评估
-
- Consol3:完全在CPU上执行的图形引擎
- Watermarking Makes Language Models Radioactive | paper
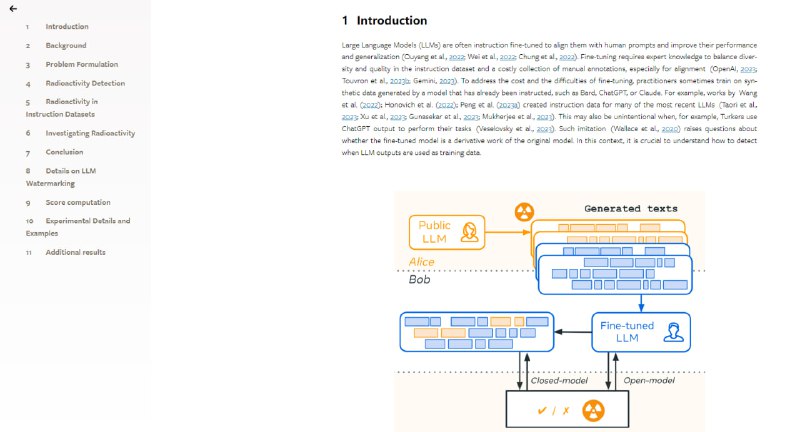
通过引入水印技术,有效提高了检测大型语言模型(LLM)生成文本被用作训练数据的能力,并且即使在微调数据中仅有少量水印文本存在时,也能以极高的置信度进行检测,这发现为数据版权和隐私保护提供了新的视角和工具。 -


- R2R:产品级RAG系统,提供半自主化的RAG框架,旨在弥合实验性RAG模型与鲁棒、产品级系统之间的差距

-


- 一个包含大约100万个AI偏好的数据集,从teknium/OpenHermes-2.5中提取而来。

它结合了来自源数据集和另外两个模型Mixtral-8x7B-Instruct-v0.1和Nous-Hermes-2-Yi-34B的回答,并使用PairRM作为偏好模型对生成结果进行评分和排名。
该数据集可用于训练偏好模型或通过直接偏好优化等技术对齐语言模型。
OpenHermesPreferences | #数据集 - Refined-Anime-Text:包含超过一百万条、约4400万个 GPT-4/3.5 token的、全新合成的文本数据集的动漫主题子集

- Supervoice GPT:将文本转换为音素及其持续时间的GPT模型,适用于输入语音合成器

-
-