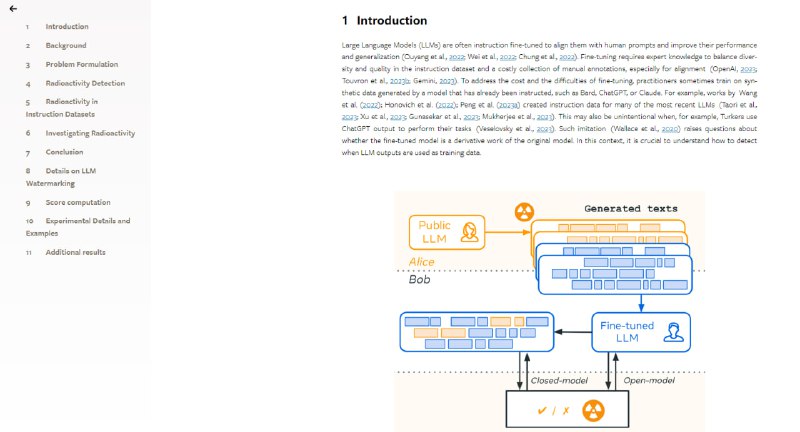
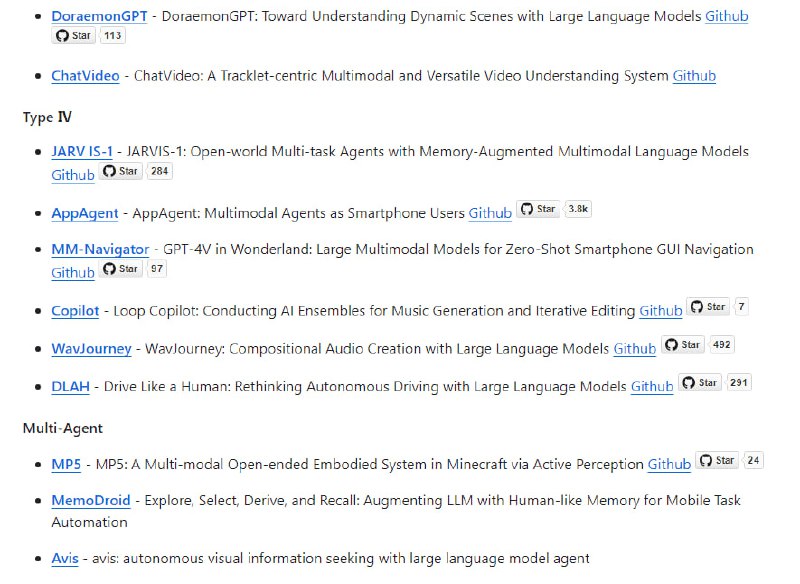
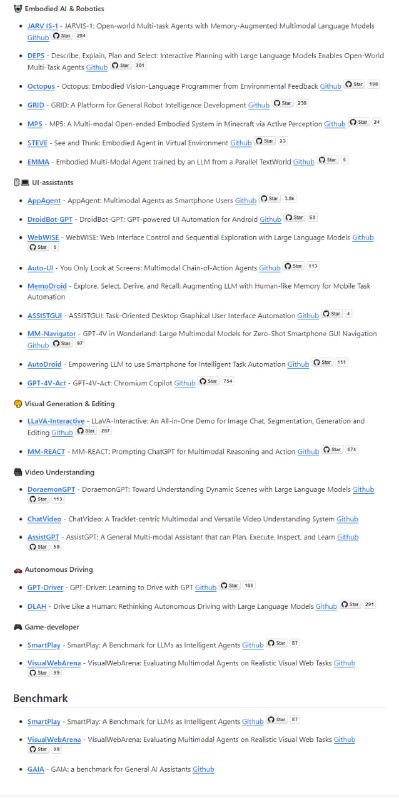
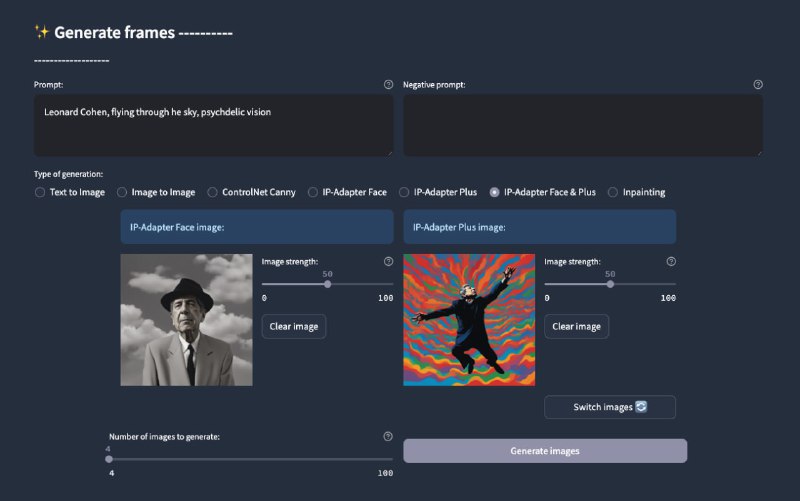
本地LLM使用指南 0.2 |
#指南LLMs,即大型语言模型(Large Language Models),是一种基于人工智能和机器学习技术构建的先进模型,旨在理解和生成自然语言文本。这些模型通过分析和学习海量的文本数据,掌握语言的结构、语法、语义和上下文等复杂特性,从而能够执行各种语言相关的任务。LLM的能力包括但不限于文本生成、问答、文本摘要、翻译、情感分析等。
LLMs例如GPT、LLama、Mistral系列等,通过深度学习的技术架构,如Transformer,使得这些模型能够捕捉到文本之间深层次的关联和含义。模型首先在广泛的数据集上进行预训练,学习语言的一般特征和模式,然后可以针对特定的任务或领域进行微调,以提高其在特定应用中的表现。
预训练阶段让LLMs掌握了大量的语言知识和世界知识,而微调阶段则使模型能够在特定任务上达到更高的性能。这种训练方法赋予了LLMs在处理各种语言任务时的灵活性和适应性,能够为用户提供准确、多样化的信息和服务。