黑洞资源笔记
-
-
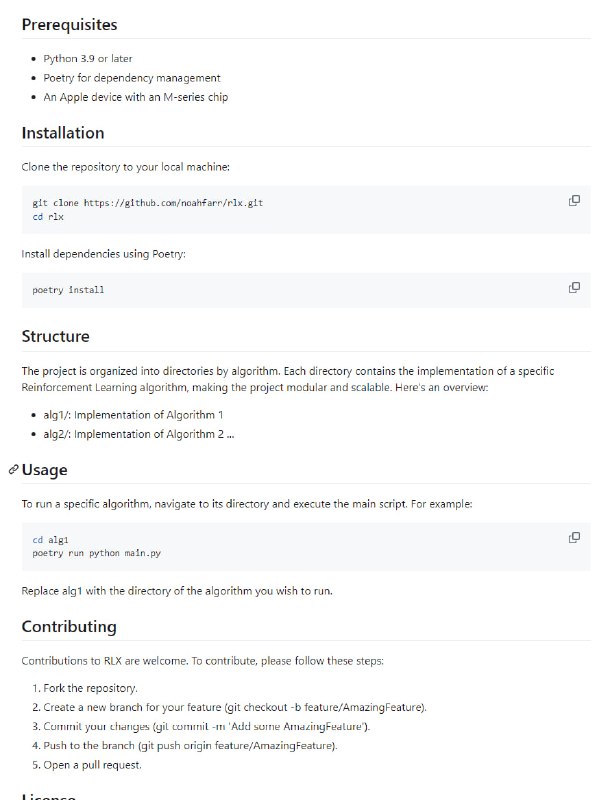
- Linux 中国所有原创文章的 Markdown 内容备份 | attachments
- SocraSynth是一个多LLM Agent推理平台,通过条件统计和连续论证来增强上下文,并通过可调节的辩论争议水平,解决了大型语言模型在偏见、幻觉和推理能力不足方面的问题,提供了全面的评估和增强合作的功能。

-
-


- OpenAI为ChatGPT和GPTs增加记忆能力 | blog
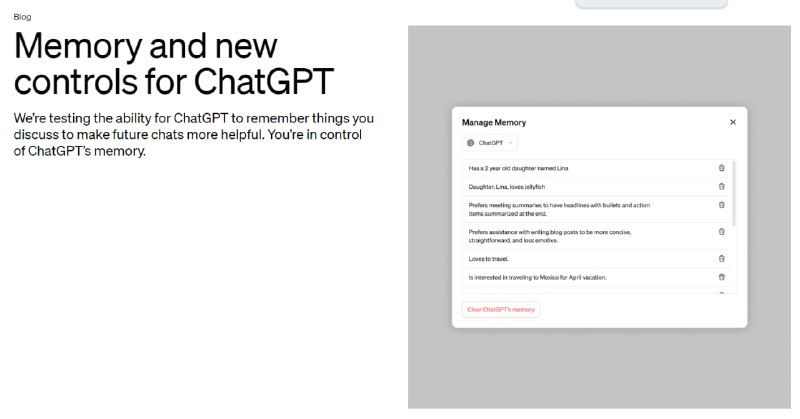
OpenAI正在测试ChatGPT的记忆能力,使其能够记住用户的讨论内容,从而提高未来聊天的有效性,用户可以控制ChatGPT的记忆。记忆可以让ChatGPT记住用户的偏好和详细信息,从而提供更加个性化和连贯的对话。例如记住用户喜欢的会议纪要格式、拥有的咖啡店细节、孩子的喜好等。
用户可以随时关闭记忆功能,也可以让ChatGPT遗忘特定记忆或清除所有记忆,删除聊天不会删除其记忆。
OpenAI可能会使用用户提供的内容(包括记忆)来改进模型,用户可以通过数据控制关闭此功能。可以使用临时聊天功能进行不需要记忆的对话。
自定义指令可以让ChatGPT更好地了解用户及回复方式。记忆可以补充聊天中获得的信息。团队版和企业版用户可以通过记忆更高效地使用ChatGPT,例如记住格式偏好、编程语言等,企业版用户可以关闭组织的记忆功能。
GPTs也将拥有独立的记忆。建造者可以选择为GPTs开启记忆,用户与不同GPTs的记忆是独立的。OpenAI将关注记忆带来的隐私和安全问题,避免主动记住敏感信息。 - Chat With RTX:NVIDIA的本地聊天机器人项目
Chat With RTX让用户可以个性化训练一个连接自定义内容(文档、视频等)的大型语言模型,并与其聊天获取相关回复。
Chat With RTX利用了检索增强型生成(RAG)、TensorRT-LLM和RTX加速,可以快速从自定义聊天机器人中获取与上下文相关的回复。它支持各种文件格式,包括文本、pdf、doc/docx、xml等。用户可以指向含有这些文件的文件夹,应用可以在几秒内加载它们。
Chat With RTX技术演示基于GitHub上的TensorRT-LLM RAG开发者参考项目构建。开发者可以基于该项目开发部署自己的RAG应用。
Chat With RTX需要Windows 11系统,NVIDIA GeForce RTX 30/40系列或支持TensorRT-LLM的GPU,16GB以上RAM。
RTX GPU通过TensorRT-LLM可以实现下一级别的AI性能,提供增强的创造力、生产力,以及极快的游戏体验。
NVIDIA提供了各种面向开发者的生成AI工具和面向企业的解决方案。 - 圣克鲁斯加利福尼亚大学的老师Eric Lengyel总结的二进制运算基础

- DataDreamer:一个强大的开源Python库,用于提示、合成数据生成和训练工作流,旨在简单、高效,且适用于研究。

使用DataDreamer,可以轻松创建和运行多步骤的提示工作流,生成合成数据集,对模型进行训练。 -
-
-
- Shoggoth:点对点匿名网络,用于发布和分发开源人工智能(AI)。
加入Shoggoth网络无需注册或批准,节点和客户端操作匿名,身份与现实世界的身份分离。任何人都可以自由加入网络,并立即开始发布或访问资源。
Shoggoth的目的是为了对抗AI审查制度,赋予软件开发人员创建和分发开源AI的权力,而无需集中式服务或平台 - Aya Dataset是一个开放获取的数据集合,旨在填补自然语言处理中的语言差距,包括一个由人工策划的涵盖65种语言的指令遵循数据集,以及一个跨越114种语言的多语言数据集,共包含5.13亿个实例。

该项目旨在为指令微调提供资源,并为未来的研究合作提供宝贵的框架。该数据集对于AI语言建模的突破至关重要,并强调了多样性和包容性数据集的重要性。 - babelfish by sync:在不到15分钟内部署一个应用,利用AI将任意视频完美翻译成任意语言并实现唇语同步
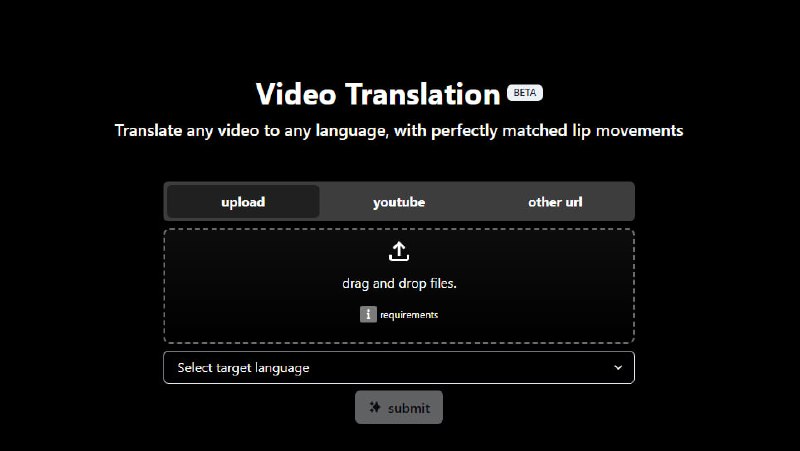
-