活动结束,感谢支持。祝各位新年快乐!
黑洞资源笔记
-
- Alvea:一款革命性的应用程序,旨在通过利用生成式用户界面来增强生产力和用户体验。
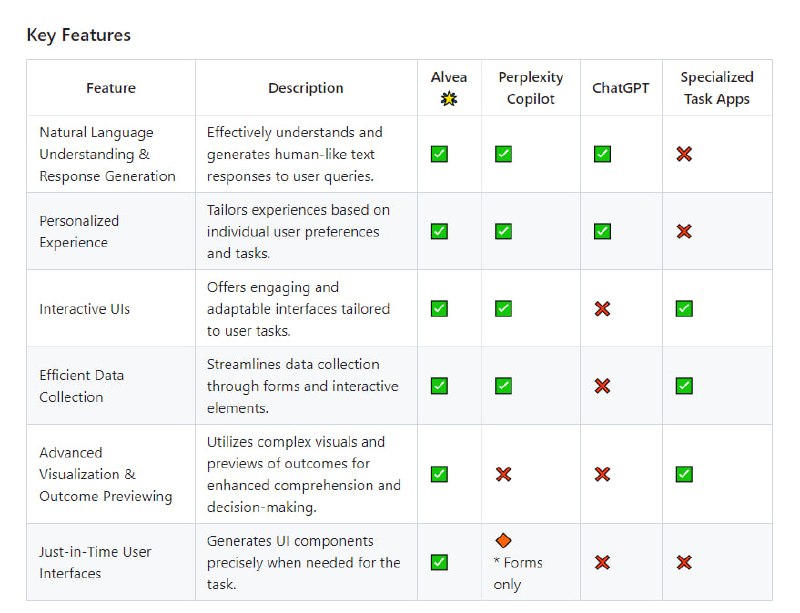
它在AGI House SF的生成式UI黑客马拉松中开发,通过提供动态的、随时适应用户任务和需求的用户界面,解决了现有AI聊天应用的局限性,这些应用因依赖文本通信而无法提供最佳的协作和信息体验。
其关键特点包括能够理解和生成类似人类文本响应的自然语言理解和响应生成,个性化体验,交互式用户界面,以及高效的数据收集和先进的可视化和结果预览 -
-
-
- Kaggle AI生成文本检测竞赛第一名方案 | github

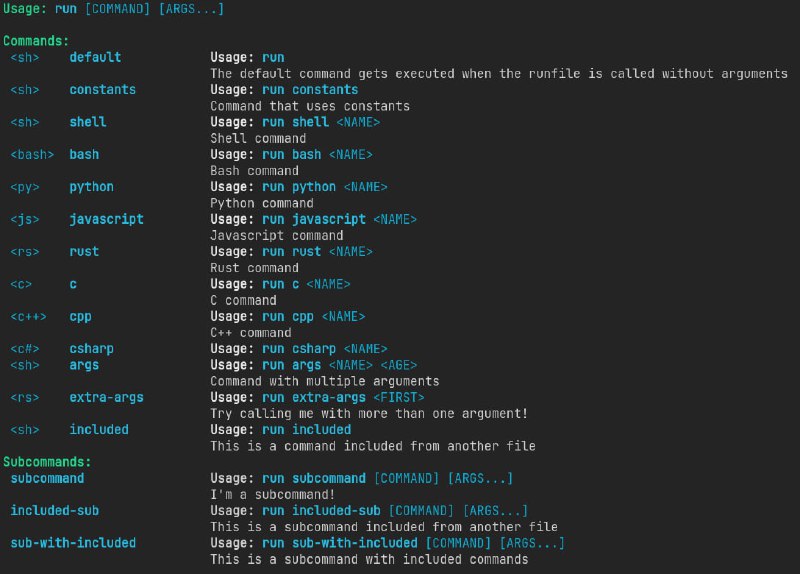
- run:允许用户在多种编程语言中运行命令,并支持混合使用这些语言
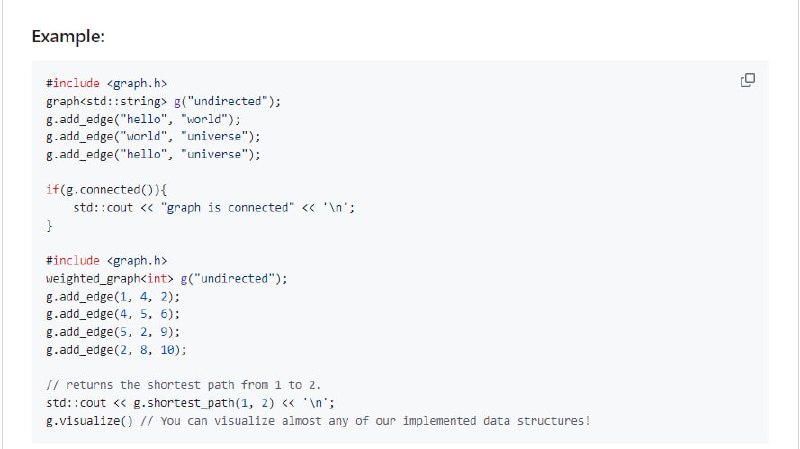
- AlgoPlus:一个C++库,包含了现成的复杂数据结构和算法,支持图结构、最短路径计算以及可视化
- 2023年值得关注的顶级Python库 | blog | #Python
1.LiteLLM:一个简化大型语言模型(LLM)调用和嵌入调用的开源库,支持OpenAI格式,提供统一的输入输出格式,便于在不同模型间切换。
2.PyApp:一个简化Python应用部署的工具,允许开发者创建自安装包,支持跨操作系统,并且具有自更新功能。
3.Taipy:一个低代码Python库,专为数据科学家设计,用于构建交互式Web UI,无需掌握Web堆栈工具,支持机器学习产品的可视化。
4.MLX:专为Apple Silicon设计的机器学习数组框架,提供NumPy风格的API,支持自动微分、向量化和计算图优化。
5.Unstructured:一个全面的文本预处理工具包,能够处理多种格式的文档,如PDF、HTML和Word文档,提供清洗、格式化和信息提取功能。
6.ZenML和AutoMLOps:一个开源MLOps框架,用于创建可移植的生产就绪机器学习管道,以及AutoMLOps服务,用于生成、配置和部署集成CI/CD的MLOps管线。
7.WhisperX:OpenAI的Whisper模型的增强版本,提供更准确的时间戳和多说话人检测,以及更快的处理速度和更低的内存占用。
8.AutoGen:一个框架,允许开发者使用多个agent进行对话协作,以解决任务,类似于软件工程团队的协作。
9.Guardrails:一个用于指定结构和类型、验证和纠正大型语言模型输出的库,确保模型输出符合预期。
10.Temporian:一个用于处理时间序列数据的库,支持多变量时间序列、事件日志和跨源事件流。
这些库不仅展示了Python在AI领域的强大能力,也为开发者提供了更多样化的工具,以应对各种挑战。 - Gaia:以C++编写的物理仿真代码库,旨在提供高效且灵活的仿真解决方案,支持独立运行或作为第三方模块集成到其他应用中。
它包含了一系列实用工具,如高效的三角/四面体网格数据结构、便捷的参数输入输出模块、碰撞检测器以及可扩展的虚拟物理框架,以支持各种求解器。 -
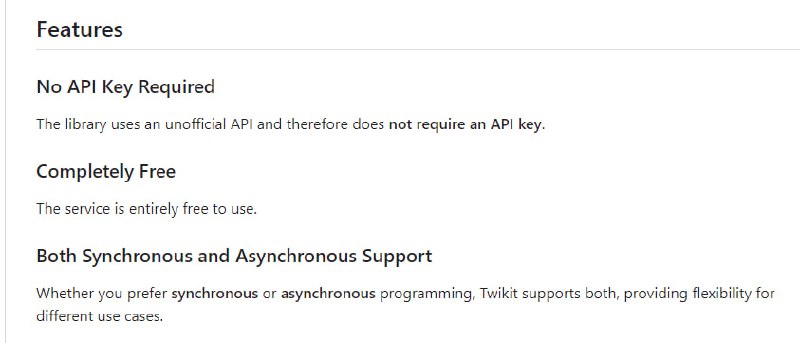
- Twikit:无需API密钥的Python Twitter API包装器,允许用户通过Twitter的内部API进行交互和数据访问
- arXiv Readability:通过提供HTML5格式的科学论文,使arXiv上的内容更加广泛地可用和可访问

- apple vision pro + 实时换脸
- InstructIR:按照人类指令进行高质量图像恢复
你只需要使用文字描述就能修复和改善图片
比如说,如果你有一张因为雨滴而看起来模糊的照片,你可以告诉它:请去掉照片上的雨滴,但保持图片内容不变”,它就能自动帮你操作。
它能够处理包括去噪、去雨、去模糊、去雾以及(低光)图像增强等问题。
主要功能:接收图像和人类书面指令作为输入,根据这些指令对图像进行改善;支持多种图像恢复任务,包括去噪、去雨、去模糊、去雾和图像增强;实现了状态最先进的恢复效果,提供了高质量的图像输出。
工作原理:
InstructIR使用一个文本编码器将人类提供的自然语言指令转换为模型可以理解的向量表示。这些指令明确指导模型关注图像的哪些退化问题,并提供改善的方向。
全能图像恢复模型:采用NAFNet作为图像恢复的核心模型架构,它是一个高效且性能卓越的图像处理网络。NAFNet能够处理多种图像退化类型,为全方位图像恢复提供支持。
指令条件块(ICB):InstructIR引入了ICB来实现任务特定的转换,根据文本编码器输出的指令向量,ICB能够调整图像模型的处理流程,使模型能够针对具体的退化类型进行专门的恢复处理。
多任务学习与任务路由:通过利用任务路由技术,InstructIR能够在单一模型中学习并执行多种图像恢复任务。模型根据输入的人类指令自动判断需要执行的任务类型,并采取相应的恢复策略。
项目地址 | paper | github | 在线体验 - 美图发布公告称宣布收购站酷。
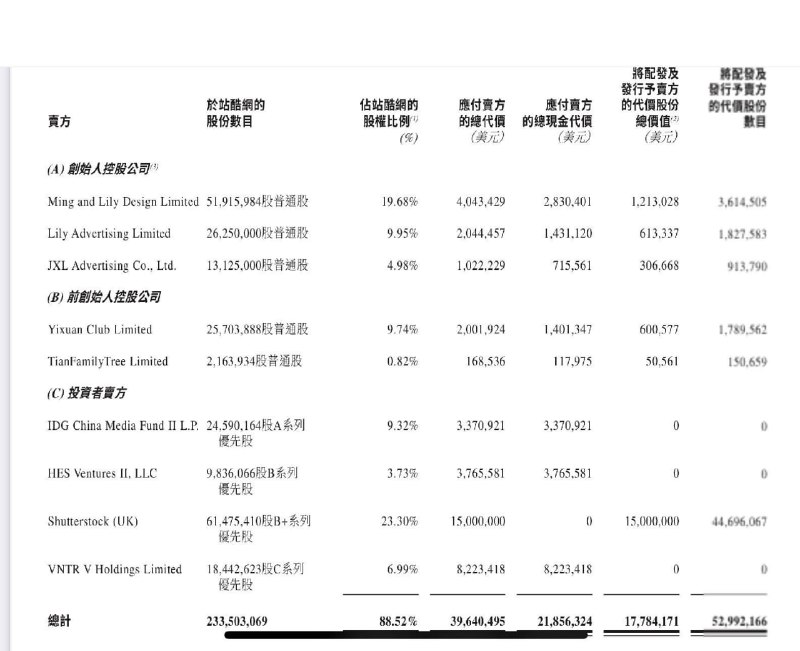
总价为3964.05万美元(约2.85亿元),其中1778.4万美元将以配发及发行52,992,166股代价股份支付,而余额约2185.6万美元将以现金支付。
站酷成立于2006年,聚集了来自全球300多个城市的设计师、摄影师、插画师等视觉创意从业者,拥有近1700万注册用户。
美图CEO吴欣鸿表示,随着站酷的加入,美图影像与设计产品业务将得到进一步升级,为自研AI视觉大模型MiracleVision(奇想智能)的生态带来优质的协同效应,同时帮助美图在专业设计领域进行业务扩展,在版权和共创等方面增强美图的服务能力。 - Apple Vision Pro 正式发售

- iFixit 发布 Apple Vision Pro 拆解视频 | YouTube
- Gemini Ultra即将上线,Bard将更名为 Gemini
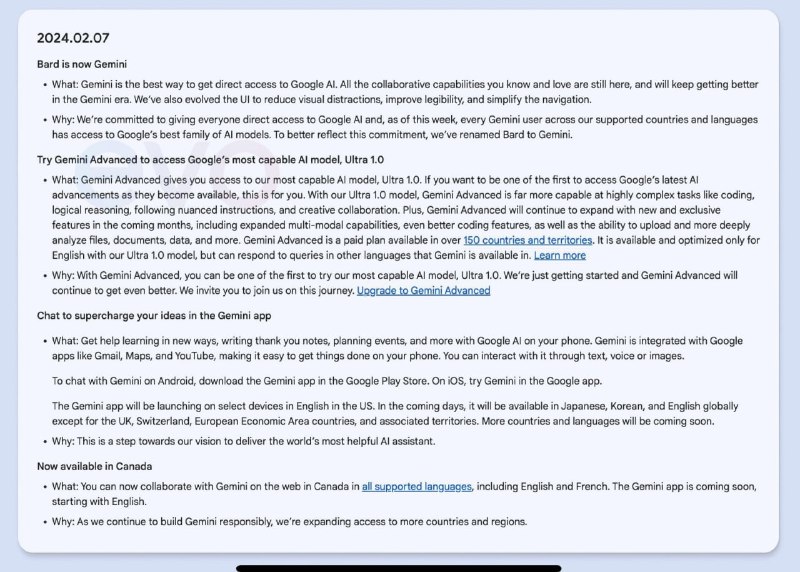
一份泄露的文档显示,Google的Gemini Ultra模型将在2月7号上线,同时Google聊天机器人Bard将更名为Gemini。
Gemini将开启付费计划:Gemini Advanced,这是一个类似ChatGPT Plus的付费模式,可以访问Gemini Ultra 1.0,Gemini Pro可能将继续免费。
核心要点:
界面优化:Gemini的用户界面经过优化,以减少视觉干扰,提高可读性,并简化导航。
Gemini Advanced付费计划:提供访问Google最强大的AI模型Ultra 1.0的能力,可以执行复杂任务如编程、逻辑推理和创造性协作等。
Gemini Advanced将引入新功能和独家特性,如增强的多模态能力和编程特性,以及上传和深入分析文件的能力。
将推出Gemini APP,用户可以在手机上下载使用Gemini来学习、写信、规划活动等。该应用与Google的其他应用(如Gmail、Maps和YouTube)集成,支持文本、语音或图片交互。 - ML Blocks:无代码AI图像生成和分析工作流平台
它提供了一个拖放式的界面,允许用户轻松地创建复杂的图像处理工作流,无需编写任何代码。
你只根据需要将不同的功能块(如图像编辑功能和AI模型)组合在一起,即可实现个性化的图像自动化处理。
该工具主要解决在电商领域遇到的批量处理图片问题。
ML Blocks允许用户创建可以处理多步骤图像生成或分析管道的自定义图像处理工作流,使用基于图的工作流。用户只需按顺序连接几个块,如去背景 -> 裁剪 -> AI上采样,就可以在几分钟内得到完整的图像处理工作流。
主要功能:
生成图像:使用 Stable Diffusion 等 AI 模型生成或绘制图像。
编辑图像:提供编辑功能,如裁剪、调整大小、重新着色等,来修改图像。
分析图像:利用检测或分割模型从图像中提取数据。
实际应用示例:基于提示模糊图像特定区域:传统方法需要使用DINO模型生成提示中提到的对象周围的边界框,然后使用像Segment Anything这样的分割模型生成这些区域的遮罩,最后使用Pillow或OpenCV库编写模糊功能来模糊遮罩区域。
而使用ML Blocks,用户只需将分割、遮罩和模糊块连接起来,就能在2分钟内完成工作流程。
你还可以自动生成博客帖子或推文的横幅图像、根据提示移除图像中的对象、去除背景并用AI创建新背景等多种工作流程。
工作原理 | Home