黑洞资源笔记
-
- 一本教授学术搜索的工具书,教你如何通过学术搜索引擎等精准的搜索,在各类数据库中搜索到想要的信息。前面有理论知识,后面有案例,理论结合实际,从入门到精通,很实用。| #论文 #电子书 #学术
作者郭劲赤,华东师范大学图书馆副研究馆员。长期从事信息素养相关课程的一线教学,主讲的华东师范大学研究生课程和“文献调研与信息检索”在线课程为热门课程。主持国家社科基金项目等课题,发表SSCI论文4篇,担任SSCI期刊审稿人。
本书主要面向广大高校学生、教师和研究人员,以及对科研、论文写作、信息搜集感兴趣的人士。
全书内容涵盖学习、研究过程中的各类信息搜索,包含丰富的实用技巧与有趣的案例故事,帮你打破传统检索方式,实现精准“学术搜索” 。
本书内容由浅入深,共分四篇(导论篇、入门篇、精通篇、学术规范篇)十五章,具体涵盖了:
1.纸本资源导航,包括国家图书馆和上海图书馆的馆藏资源,联合目录CASHL、NSTL、CALIS等;
2.学术搜索引擎使用指南,包括Semantic Scholar、BASE等;
3.期刊数据库使用攻略,包括知网、万方、维普、ScienceDirect、EBSCO等;
4.图书数据库使用要点,包括超星、读秀、SpringerLink等;
5.学位论文数据库使用诀窍,包括知网、万方、PQDT等;
6.引文数据库利用方法,包括CSSCI、SCI、Web of Science、Scopus等;
7.统计数据库介绍,包括中国经济社会大数据研究平台、OECD iLibrary、国际组织数据公开网站等。
同时专门为奋战在“论文写作前线”的读者准备了论文写作与投稿规范、如何辨别真假投稿期刊、论文查重“通关秘籍”等内容。 为沉迷手机上网的读者专辟一章,讲解如何利用手机等移动设备访问图书馆和数据库App。通过本书,帮助读者成为学术信息搜索达人,尽情遨游学术海洋。 - Product design tools database —— 产品设计工具收集 | #设计 #工具
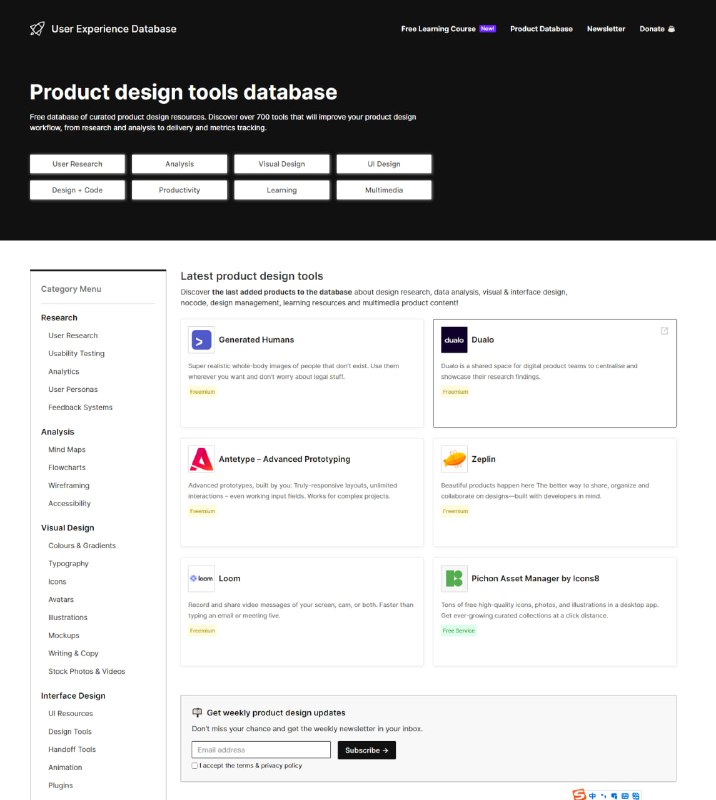
这个网站收录了 700 多个产品设计有关的工具,可帮助改善产品设计能力和过程。按不同类别:包括用户研究、分析、视觉界面设计、设计+代码、效率工具、课程、多媒体资源。 -
-
-
-
- Open-LX01:小爱音箱mini定制固件,让小爱音箱mini成为一个完全自主控制的音箱
-
- 专注于快速生成高质量结构化表格数据的框架,支持许多单表和多表数据合成算法,可实现高达120倍的性能提升,并支持差分隐私和其他方法以增强合成数据的安全性。

合成数据是机器根据真实数据和算法生成的,它不包含敏感信息,但可以保留真实数据的特征。合成数据与真实数据之间不存在对应关系,并且不受 GDPR 和 ADPPA 等隐私法规的约束。实际应用中,无需担心隐私泄露的风险。高质量的合成数据还可以应用于数据开放、模型训练与调试、系统开发与测试等各个领域。
特点
高性能:支持多种统计数据合成算法,实现高达120倍的性能提升,无需GPU设备;针对大数据场景进行优化,有效降低内存消耗;持续跟踪学术界和工业界的最新进展,及时推出对优秀算法和模型的支持;通过torch等框架为深度学习模型提供分布式训练支持。
隐私增强功能:SDG支持差分隐私、匿名化等方法来增强合成数据的安全性。
易于扩展:支持以插件包的形式扩展模型、数据处理、数据连接器等
Synthetic Data Generator | #框架 - OpenAI发布新嵌入模型,降低GPT-3.5 Turbo价格 | blog

OpenAI发布了新的嵌入模型和API更新,包括两个新的嵌入模型、更新的GPT-4 Turbo预览模型、更新的GPT-3.5 Turbo模型和更新的文本审核模型。
新的嵌入模型包括一个小型高效的text-embedding-3-small模型和一个大型高性能的text-embedding-3-large模型,允许开发者在使用嵌入时权衡性能和成本,特别是可以通过减少嵌入的维数(即从序列的末尾移除一些数字)来实现。 这些模型能够创建最多3072维的嵌入。
OpenAI表示,发送到OpenAI API的数据默认不会被用来训练或改进OpenAI模型。 - 非母语者英语科研写作的几个技巧 | 文章 | #技巧 #经验

作为非英语母语者,作者Nuwan Bandara在写科研论文时面临语言障碍。他分享了7个提高写作的技巧。
在写作时遇到词语难点,先留白继续写,初稿允许留白。先写最熟悉的部分,如方法部分。注重绘制漂亮的图表。创建知识文档记录文献要点。
先写简单版本的导言,迭代完善。学习他人文章的写作方式,研读AI生成的文本扩展写作语言谱。
从舒适区开始写作,逐步拓展到其他部分,每部分迭代精炼,保持初稿推进。这些技巧帮助作者进步。
作为非英语母语科研人员,从文章语言结构上学习成功案例很重要,多阅读科研论文,掌握学术写作标准和语言表达。
AI生成的文本如ChatGPT虽不能直接引用,但可以用来优化语句结构,提高学术英语写作水平。 - MiniMalloc:专为机器学习模型静态内存分配而设计的先进算法,使用多种新的搜索技巧以高效解决此类问题
- CurlyQ 是一个实用程序,为curl 提供了一个简单的界面,并具有提取图像和链接、通过CSS 选择器或XPath 查找元素、获取详细标题信息等附加功能。
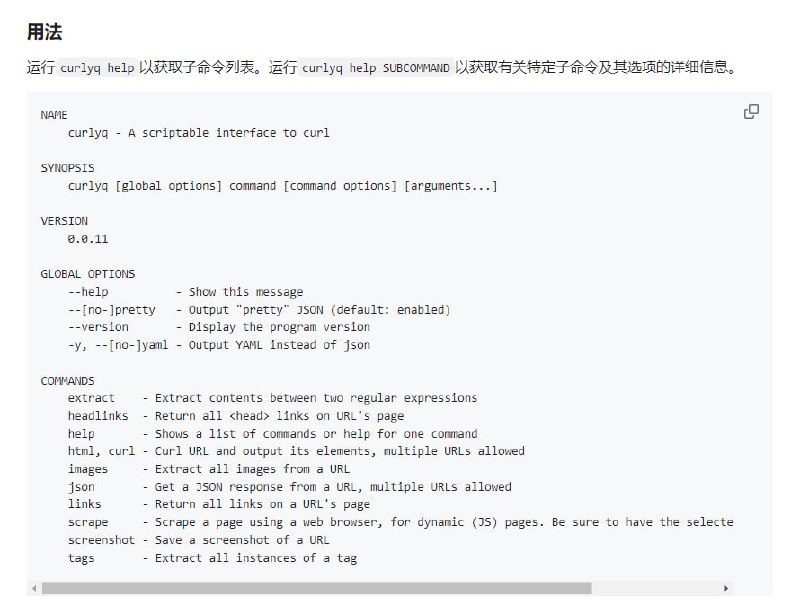
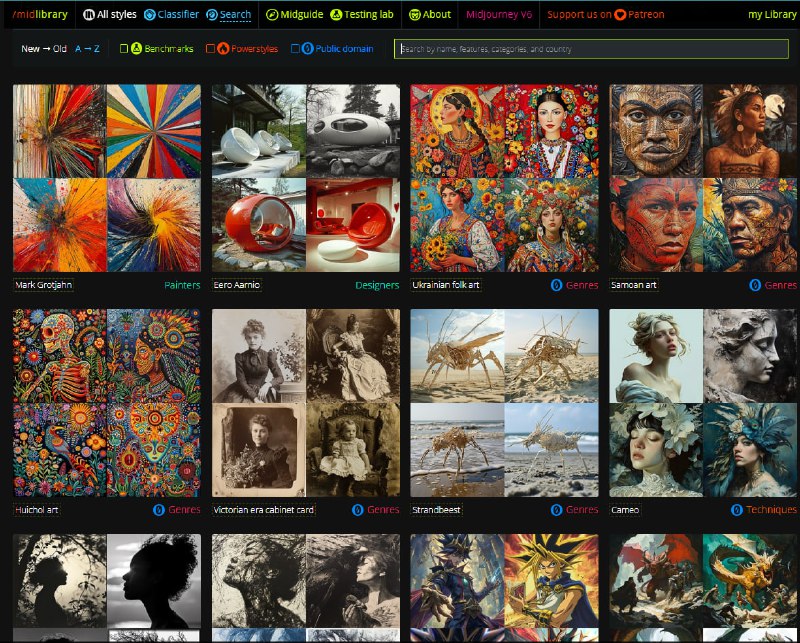
它被设计为脚本管道的一部分,将所有内容输出为结构化数据(JSON 或 YAML)。它还具有使对 JSON 端点的调用更容易的基本支持,但预计你会使用jq之类的东西来解析输出。 - Midlibrary:包含 4000 种 Midjourney 艺术风格的图象库
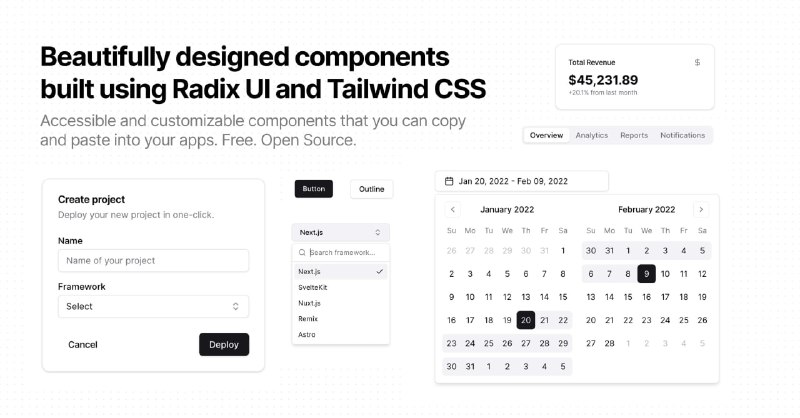
- 一个无障碍、可定制、开源的组件,可以将其复制并粘贴到应用程序中。| shadcn/ui
- 首次使用 xv6 和 6.1810 实验室进行操作系统内核开发 | 详文

- 用汇编语言编写的轻量级网络论坛引擎
AsmBB完全用汇编语言编写,并使用SQLite作为数据库后端。这就是为什么它可以在非常弱的托管上工作,同时为大量访问者提供服务,而不会出现滞后和延迟。
由于内部设计和减少的依赖性,AsmBB 是非常安全的 Web 应用程序。但它还支持加密数据库,安全性更高。
另外,AsmBB对运行环境的要求很少:
-x86 Linux 服务器。
-不管32位还是64位。无需任何专门预安装的库。
-最小/最便宜的 VPS 就可以了。共享主机也可以(如果支持 FastCGI)。
-支持 FastCGI 接口的 Web 服务器。AsmBB 已通过 Nginx、Apache、Lighttpd、Hiawatha,当然还有 RWASA 进行了测试。
AsmBB 易于定制和修改 - 它使用非常强大的模板系统,可以轻松定制论坛而无需实际修改代码。(不过这并不难)。
AsmBB | 二进制包 | repo
安装教程:使用 NGINX 和 systemd 安装 | 使用 RWASA 安装 -