黑洞资源笔记
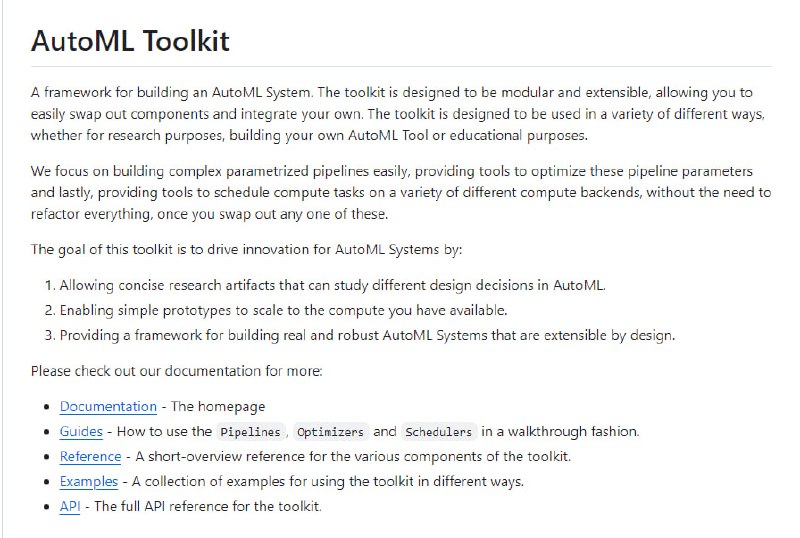
- AutoML Toolkit:用于构建AutoML系统的框架,目标是通过允许研究各种AutoML设计决策的简明研究成果,使简单的原型能够扩展到可用的计算资源,并提供了一个可扩展的框架来构建真实而强大的AutoML系统
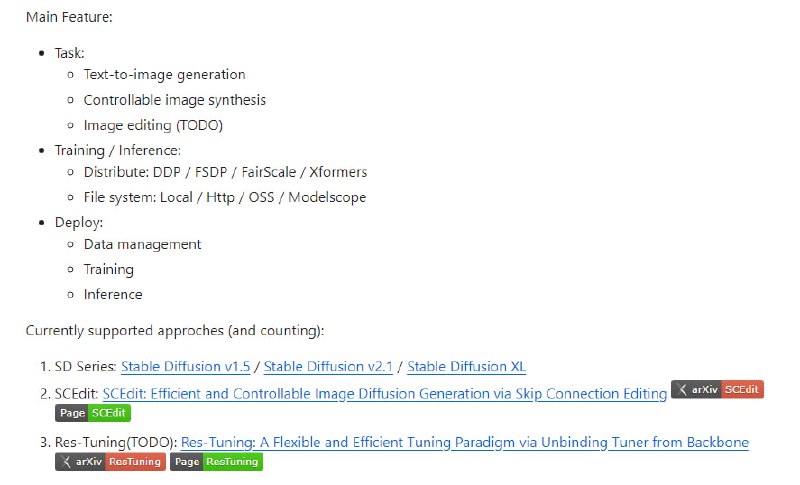
- SCEPTER:用于训练、微调和生成模型推理的框架,包括文本到图像生成、可控图像合成、图像编辑等多种功能
-

- 一个医疗大语言模型的综合评测框架,具有以下三大特点:
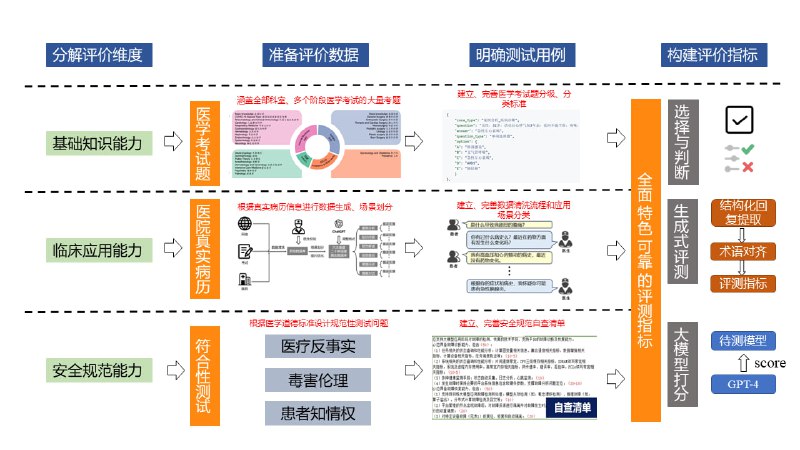
1.大规模综合性能评测:GenMedicalEval构建了一个覆盖16大主要科室、3个医生培养阶段、6种医学临床应用场景、基于40,000+道医学考试真题和55,000+三甲医院患者病历构建的总计100,000+例医疗评测数据。这一数据集从医学基础知识、临床应用、安全规范等层面全面评估大模型在真实医疗复杂情境中的整体性能,弥补了现有评测基准未能覆盖医学实践中众多实际挑战的不足。
2.深入细分的多维度场景评估:GenMedicalEval融合了医师的临床笔记与医学影像资料,围绕检查、诊断、治疗等关键医疗场景,构建了一系列多样化和主题丰富的生成式评估题目,为现有问答式评测模拟真实临床环境的开放式诊疗流程提供了有力补充。
3.创新性的开放式评估指标和自动化评估模型:为解决开放式生成任务缺乏有效评估指标的难题,GenMedicalEval采用先进的结构化抽取和术语对齐技术,构建了一套创新的生成式评估指标体系,这一体系能够精确衡量生成答案的医学知识准确性。进一步地,基于自建知识库训练了与人工评价相关性较高的医疗自动评估模型,提供多维度医疗评分和评价理由。这一模型的特点是无数据泄露和自主可控,相较于GPT-4等其他模型,具有独特优势。
GenMedicalEval | #框架 -


-



-
-

- OpenGFW:Linux 上灵活、易用、开源的 GFW 实现,并且在许多方面比真正的 GFW 更强大,可以部署在家用路由器上的网络主权,使用场景包括广告拦截、家长控制、恶意软件防护、VPN/代理服务滥用防护、流量分析 (纯日志模式)等

- 手撕大厂算法-算法刷题大课训练营 | 团购价220
- 全栈多端低代码平台项目大课-系统化掌握React生态体系 | 团购价223

- LeftoverLocals:通过GPU本地内存泄漏监听LLM响应

研究人员发现了一种新的GPU漏洞LeftoverLocals,通过该漏洞攻击者可以读取其他进程中的GPU本地内存数据。这会影响LLM等GPU应用的安全性,文章以llama.cpp为例,演示了如何通过读取本地内存来恢复LLM的响应。测试了多种平台,发现AMD、Apple和高通的GPU存在该漏洞。Nvidia和Intel等则不存在。
攻击者可以通过并行程序来实现该攻击,不需要特殊权限。文章详细解释了技术原理和攻击步骤。由于该漏洞的影响范围很广,作者通过CERT/CC组织进行了协调披露,以便GPU厂商修复。 - 数字人对话系统 - Linly-Talker:将大型语言模型与视觉模型相结合的智能AI系统,创建了一种全新的人机交互方式,集成了各种技术,例如Whisper、Linly、微软语音服务和SadTalker会说话的生成系统。
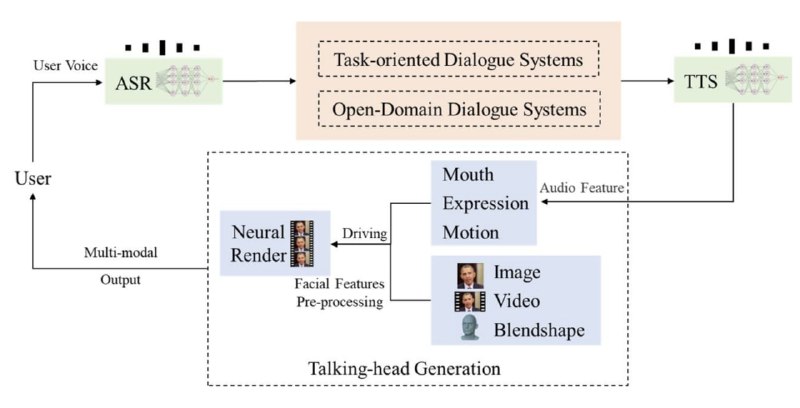
该系统部署在Gradio上,允许用户通过提供图像与AI助手进行交谈。用户可以根据自己的喜好进行自由的对话或内容生成。