黑洞资源笔记
-
-
-

- 深度学习数学工程 | YouTube | #机器学习 #电子书

本书提供了深度学习的完整且简明的数学工程概述。内容包括卷积神经网络、递归神经网络、transformer、生成式对抗网络、强化学习、图神经网络等。
书中聚焦于深度学习模型、算法和方法的基本数学描述,很大程度上与编程代码、神经科学关系、历史视角无关。数学基础的读者可以快速掌握现代深度学习算法、模型和技术的本质。
深度学习可以通过数学语言在许多专业人员可理解的层面上进行描述。工程、信号处理、统计、物理、纯数学等领域的读者可以快速洞察该领域的关键数学工程组成部分。
书里包含深度学习的基础原理、主要模型架构、优化算法等内容。另外还提供了相关课程、工作坊、源代码等资源。
本内容面向想要从数学工程视角理解深度学习的专业人员,内容覆盖了深度学习的主要技术,使用简明的数学语言描述深度学习的关键组成部分,是了解深度学习数学本质的很好资源。 - TACO(Topics in Algorithmic COde Generation dataset)是一个专注于算法代码生成的数据集,旨在为代码生成模型领域提供更具挑战性的训练数据集和评估基准。
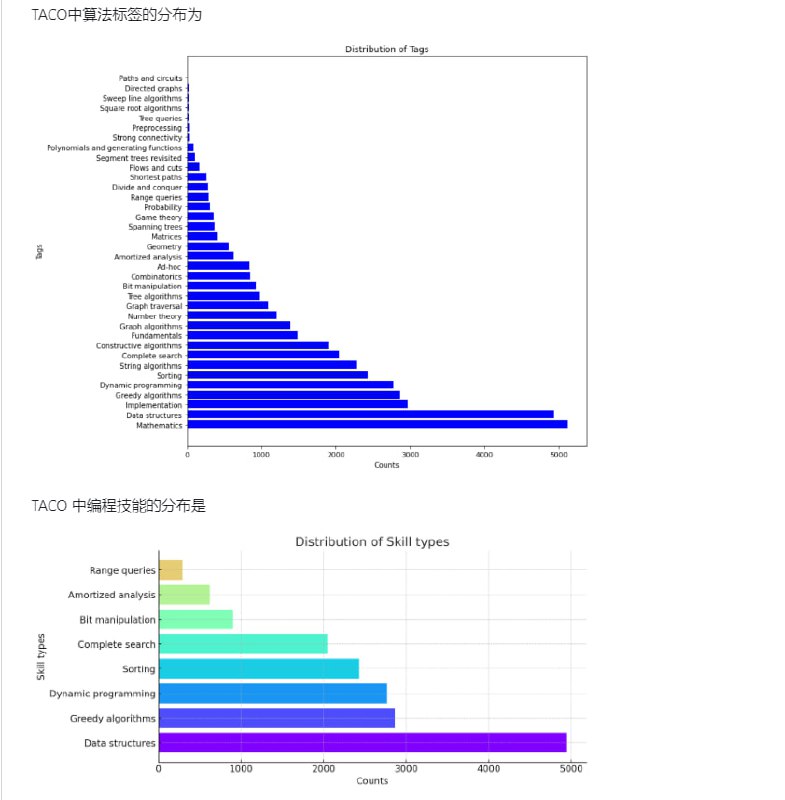
该数据集由难度更大、更接近真实编程场景的编程竞赛题组成。它强调在实际应用场景中提高或评估模型的理解和推理能力,而不仅仅是实现预定义的函数功能。
规模更大:TACO 包括训练集(25,443 个问题)和测试集(1,000 个问题),使其成为当前可用的最大的代码生成数据集。
更高质量:TACO 数据集中的每个问题都旨在匹配一组不同的解决方案答案,答案大小高达 1.55M。这保证了模型在训练过程中不易出现过拟合,并验证了评估结果的有效性。
细粒度标签:TACO 数据集中的每个问题都包含细粒度标签,例如任务主题、算法、技能和难度级别。这些标签为代码生成模型的训练和评估提供了更准确的参考。 - Inpaint-iOS:基于CoreML技术的免费开源的修复图片应用,可在iPhone/iPad/MacBook上使用,支持本地处理,无需服务器
-
- XunziALLM:为响应古籍活化利用号召,推动大语言模型与古籍处理深度融合,以古籍智能化的研究为目的,南京农业大学国家社科基金重大项目“中国古代典籍跨语言知识库构建及应用研究”课题组与中华书局古联公司推出了一系列古籍处理领域大语言模型:荀子古籍大语言模型。

荀子系列专为古籍智能处理而设计,这一系列模型的推出将推动古籍研究与保护工作的新发展,提高中华传统文化传承的效率与质量。
模型亮点:
古籍智能标引,荀子模型具备强大的古籍文献标引能力,能够对古籍中的内容进行高质量主题标引,帮助研究人员快速了解文章主题。
古籍信息抽取,荀子模型能够自动从古籍中抽取关键信息,如人物、事件、地点等,大大节省了研究人员的信息整理时间。
诗歌生成:荀子模型还具备诗歌生成的能力,能够根据给定的主题或关键词,自动生成符合语法规则和韵律要求的古诗,为诗词爱好者提供创作灵感。
古籍高质量翻译:对于那些难以理解的古籍文献,荀子模型能够提供高质量的翻译服务,帮助研究人员更好地理解原文含义。
阅读理解:荀子模型能够对给出的古文文本进行分析解释,实现对古籍文本的自动阅读。
词法分析:荀子模型可以完成古籍文本的自动分词和词性标注,能够有效提升语言学工作者的研究效率。
自动标点:荀子大模型可以快速完成古籍文本的断句和标点,提升研究者以及业余爱好者对古籍文本的阅读体验。
用户也可以根据自己的需求,使用本地的训练语料微调荀子基座模型,使得其能够在古籍下游处理任务上取得更佳的处理性能。| #古籍 -