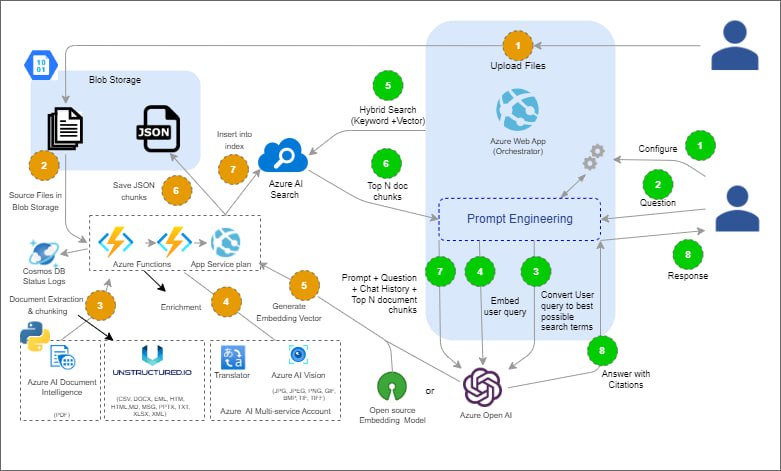
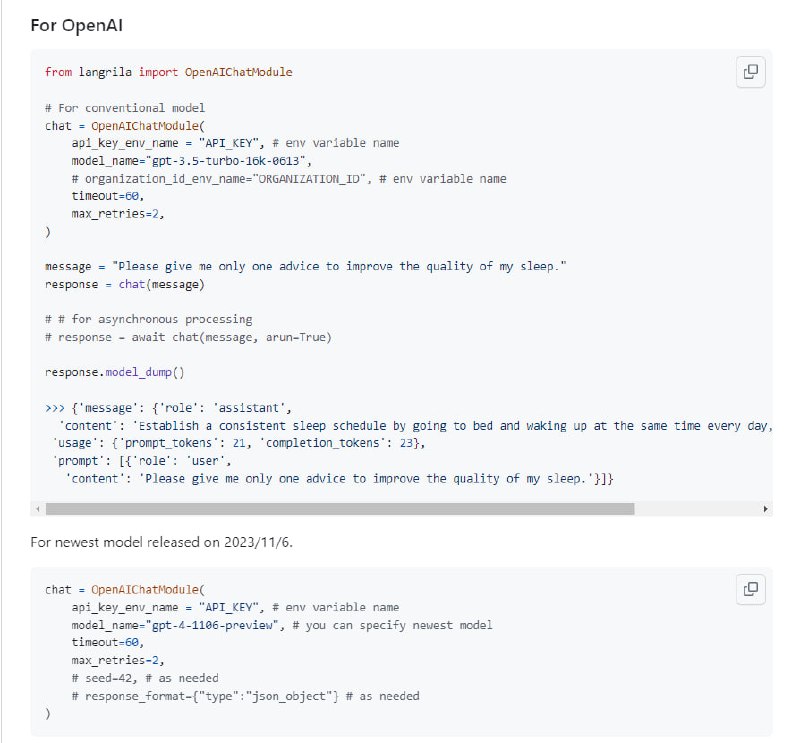
本书提供了深度学习的完整且简明的数学工程概述。内容包括卷积神经网络、递归神经网络、transformer、生成式对抗网络、强化学习、图神经网络等。
书中聚焦于深度学习模型、算法和方法的基本数学描述,很大程度上与编程代码、神经科学关系、历史视角无关。数学基础的读者可以快速掌握现代深度学习算法、模型和技术的本质。
深度学习可以通过数学语言在许多专业人员可理解的层面上进行描述。工程、信号处理、统计、物理、纯数学等领域的读者可以快速洞察该领域的关键数学工程组成部分。
书里包含深度学习的基础原理、主要模型架构、优化算法等内容。另外还提供了相关课程、工作坊、源代码等资源。
本内容面向想要从数学工程视角理解深度学习的专业人员,内容覆盖了深度学习的主要技术,使用简明的数学语言描述深度学习的关键组成部分,是了解深度学习数学本质的很好资源。