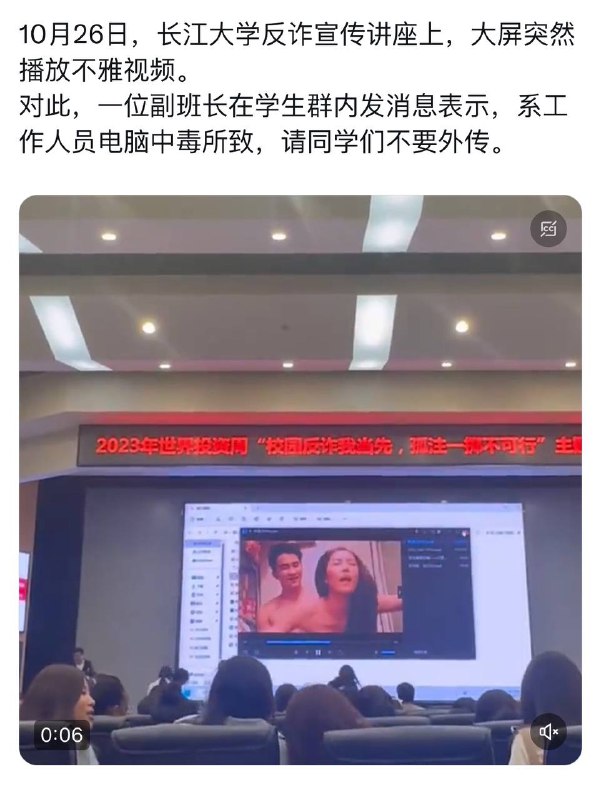
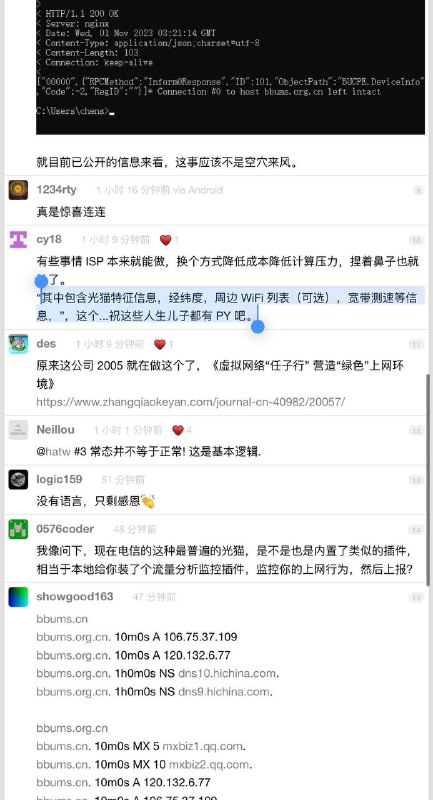
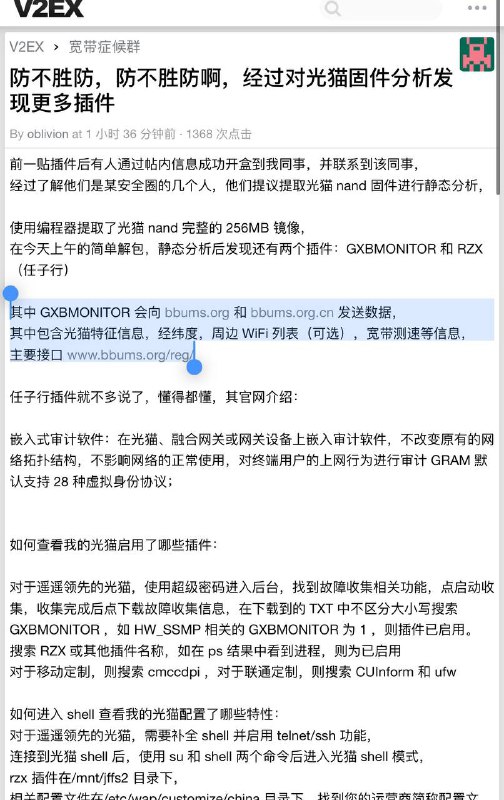
黑洞资源笔记
-
- 《Linux源码趣读》:新书,暂无电子版
一线互联网大厂专家闪客带你解读经典Linux版本源码,深入内核,提升开发和操作系统内核设计能力,深入理解Linux网络张彦飞I码农翻身刘欣等专家力荐。
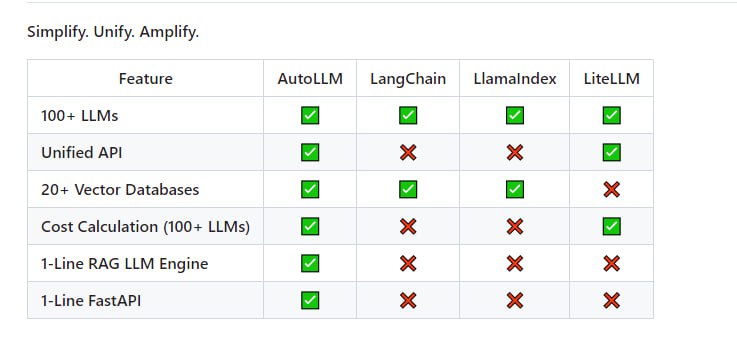
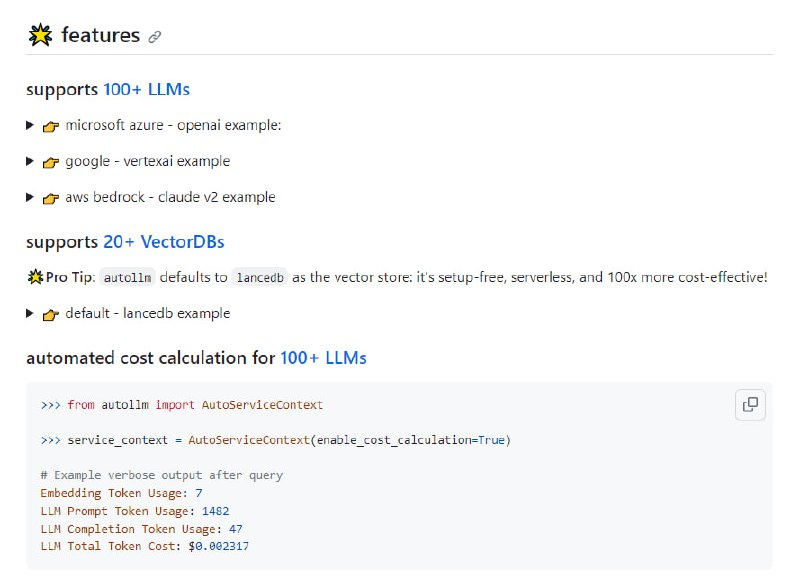
用读一本小说的心态来阅读本书,你会对整个操作系统的体系结构和逻辑细节有非常清晰的认识,从此爱上并阅读更多的操作系统源码。 - 一个免费且开源的机器翻译API,完全自托管。| libretranslate | #API
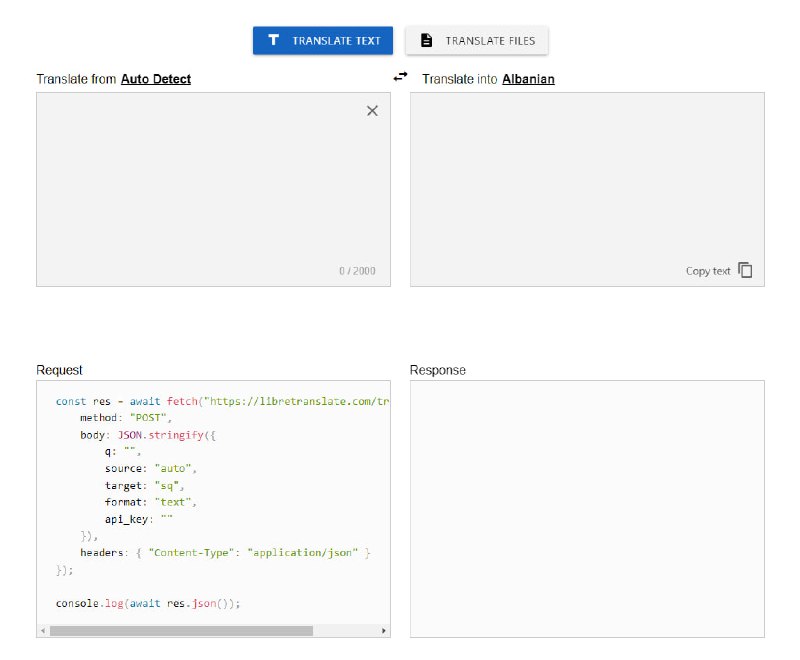
与其他API不同,它不依赖于如Google或Azure这样的专有提供商来进行翻译。相反,其翻译引擎由开源的Argos Translate库驱动。 -



-
-

- Google 开放 .ing 顶级域名注册
少数派快讯 10 月 31 日,Google 通过官方博文宣布开放 .ing 顶级域名注册,即日起用户可通过支付额外费用(费率随时间推移降低)的方式抢先注册,抢先体验期(EAP)截至 12 月 5 日。Google 表示借助该域名企业可以注册一些非常有趣的域名,比如在线设计和绘图平台 Canva 注册的 design.ing 和 draw.ing、Adobe Acrobat 注册的 edit.ing 和 signing 等。来源 - RedisVL: 用 Redis 作为矢量数据库,以简化在 Redis 中存储、检索以及对向量执行复杂语义和混合搜索的过程,对LLM应用提供更好的支持
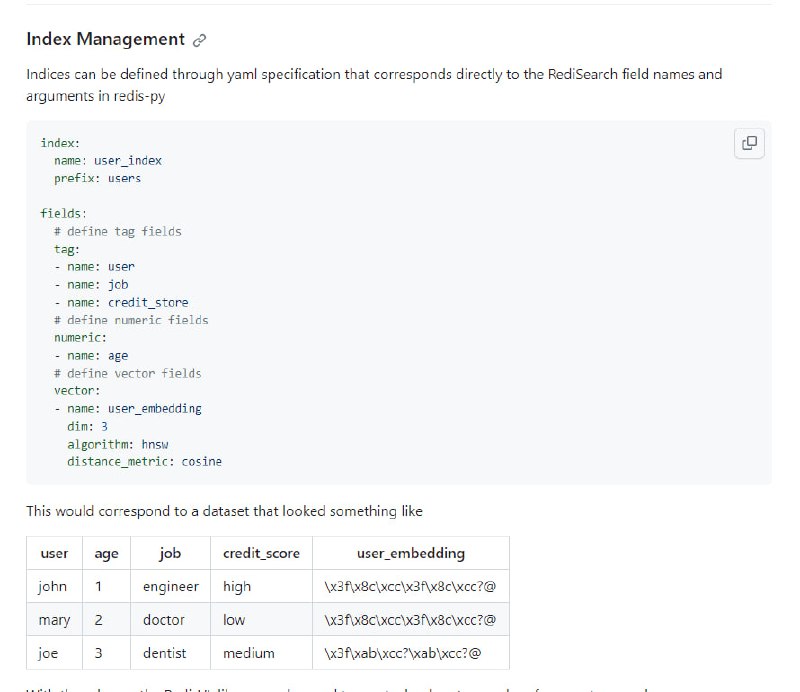
RedisVL 具有许多强大的功能,旨在简化矢量数据库操作。
索引管理:RedisVL 允许轻松创建、更新和删除索引。每个索引的模式可以在 yaml 中定义,也可以直接在 python 代码中定义,并在索引的整个生命周期中使用。
嵌入创建:RedisVL 与 OpenAI、HuggingFace 和 GCP VertexAI 集成,以简化矢量化非结构化数据的过程。图像支持即将推出。提交新矢量化器的 PR。
向量搜索:RedisVL 提供强大的搜索功能,使您能够同步和异步查询向量。还支持利用标签、地理、数字和其他过滤器(如全文搜索)的混合查询。
强大的抽象:语义缓存:LLMCache是直接内置于 RedisVL 中的语义缓存接口。它允许缓存 GPT-3 等 LLM 生成的输出。由于语义搜索用于检查缓存,因此可以设置阈值来确定缓存结果是否足够相关以返回。如果没有,则调用模型并缓存结果以供将来使用。这可以提高 QPS 并降低在生产中使用 LLM 模型的成本。 -

- 昆仑万维开源了自己的Skywork大模型 | Skywork
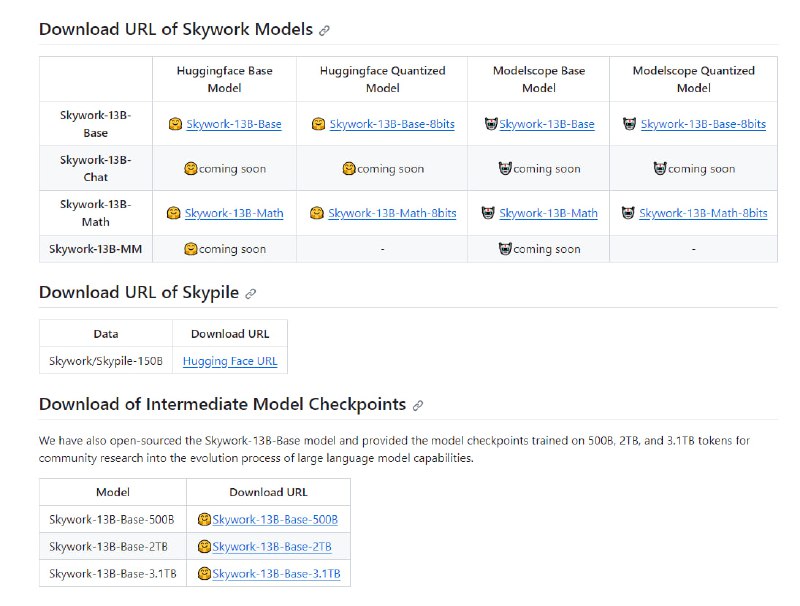
本次开源的模型有Skywork-13B-Base模型、Skywork-13B-Chat模型、Skywork-13B-Math模型和Skywork-13B-MM模型,以及每个模型的量化版模型,以支持用户在消费级显卡进行部署和推理。
Skywork开源项目的特点有:
Skywork-13B-Base模型在高质量清洗过滤的3.2万亿个多语言(主要是中文和英文)和代码数据上进行预训练,它在多种评测和各种基准测试上都展现了同等规模模型的最佳效果。
Skywork-13B-Chat模型具备强大的对话能力,我们在文创领域进行了进一步的针对性增强。我们通过构建一万多条高质量指令数据集,在10个文创任务上进行了针对性微调,使我们的模型在文创任务中能够接近ChatGPT的效果。此外,我们开源了针对这10个文创任务上的大约500条样本组成的benchmark。
Skywork-13B-Math模型经过专门的数学能力强化训练。在13B参数规模下,我们的模型在GSM8K评测上得分第一,同时在MATH数据集以及CMATH上也表现优异,处于13B模型顶尖水平。
Skywork-13B-MM多模态模型支持用户输入图片信息进行问答,对话等任务。
Skywork/Skypile-150B数据集是根据我们经过精心过滤的数据处理流程从中文网页中筛选出的高质量数据。本次开源的数据集大小约为600GB,总的token数量约为150B,是目前开源最大中文数据集。
除此之外,我们还公开了训练Skywork-13B模型中使用的评估方法、数据配比研究和训练基础设施调优方案等信息。我们希望这些开源内容能够进一步启发社区对于大型模型预训练的认知,并推动人工智能通用智能(AGI)的实现。 -