黑洞资源笔记
-
- MagCode:让所有智能手机都能享受NFC支付体验 | paper
香港理工大学的研究人员开发出一种技术,即使是不支持NFC的智能手机,也能通过摄像头拍摄NFC读取器来完成支付。
目前,大约有一半的智能手机要么没有装载NFC模块,要么由于安全原因不能使用NFC功能。这项技术可以解决这一问题。
工作原理:用户只需将手机的摄像头靠近NFC读取器,摄像头的屏幕上会出现特定的条纹模式。这些条纹实际上是用于数据传输的编码,通过读取这些编码,可以实现与NFC相同的数据交换。
技术灵感:这项技术是基于一个现象,即NFC读取器产生的磁场会对手机的CMOS图像传感器产生无害的磁干扰(Magnetic Interference,MI)。当手机摄像头靠近NFC读取器时,这种磁干扰会在摄像头的屏幕上产生类似于条形码的条纹模式。
性能表现:该技术已经通过11种不同的智能手机进行了测试,所有手机都表现出非常高的性能。特别是与基于磁感应的方法相比,数据传输速度快了58倍。 - 百川智能发布Baichuan2-192K大模型 | 详情
上下文窗口长度高达192K,是目前全球最长的上下文窗口,能够一次处理约35万个汉字。
官方宣称:Baichuan2-192K不仅在上下文窗口长度上超越Claude2,在长窗口文本生成质量、长上下文理解以及长文本问答、摘要等方面的表现也全面领先Claude2。
10项长文本评测7项取得SOTA,全面领先Claude2
Baichuan2-192K在Dureader、NarrativeQA、LSHT、TriviaQA等10项中英文长文本问答、摘要的评测集上表现优异,有7项取得SOTA,显著超过其他长窗口模型。
此外,LongEval的评测结果显示,在窗口长度超过100K后Baichuan2-192K依然能够保持非常强劲的性能,而其他开源或者商用模型在窗口长度增长后效果都出现了近乎直线下降的情况。Claude2也不例外,在窗口长度超过80K后整体效果下降非常严重。
Baichuan2-192K正式开启内测,已落地法律、媒体等诸多真实场景
Baichuan2-192K现已正式开启内测,以API调用的方式开放给百川智能的核心合作伙伴,已经与财经类媒体及律师事务所等机构达成了合作,将Baichuan2-192K全球领先的长上下文能力应用到了传媒、金融、法律等具体场景当中,不久后将全面开放。 - 具有3D预览功能的购物APP程序演示 | github
使用了 Reanimated(React Native的动画库) 和 ThreeJS ,该应用提供了一种3D预览功能,让用户能够更直观地查看商店中的商品。 -
- 孙思邈中文医疗大模型(Sunsimiao)
希望能够遵循孙思邈的生平轨迹, 重视民间医疗经验, 不断累积中文医疗数据, 并将数据附加给模型, 致力于提供安全、可靠、普惠的中文医疗大模型.
目前, Sunsimiao是由baichuan-7B和ChatGLM-6B系列在十万级高质量的中文医疗数据中微调而得, 后续将收集更多数据, 扩充模型能力, 不断迭代更新. 相关细节工作正在整理。 - 一个实用的地图生成器:DataV.GeoAtlas | #生成器 #地图
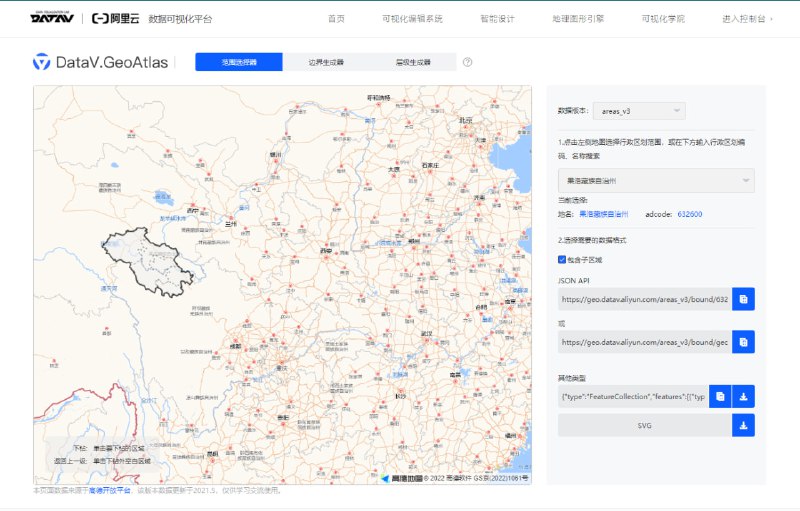
点关注的省份,会展现精致的省级轮廓地图,再点具体城市可以深入到市县级的地理细节。允许以SVG格式轻松下载地图,以便随时导入到PPT中进行编辑。相比网上随意搜寻的图像,这种方式不仅美观,还具有极高的便捷性和可编辑性。 -
-
-

-
-

- 个性化Copilot编程助手实战 | personal-copilot
这是一个根据 GitHub 组织的公共存储库中的代码内容进行微调的代码huggingfaceLLM,介绍了从GitHub克隆代码库、提取和清理代码数据的流程。对StarCoder等模型进行了全微调和QLoRA参数高效微调,并进行了比较。展示如何组合不同的适配器进行多任务训练,以实现代码补全和问答能力。
此外提供了将模型部署为推理端点、在VS Code中使用的详细流程以及在Mac M1芯片上运行小模型的训练和使用方法。 -
-