黑洞资源笔记
-
-
-

- 个性化Copilot编程助手实战 | personal-copilot
这是一个根据 GitHub 组织的公共存储库中的代码内容进行微调的代码huggingfaceLLM,介绍了从GitHub克隆代码库、提取和清理代码数据的流程。对StarCoder等模型进行了全微调和QLoRA参数高效微调,并进行了比较。展示如何组合不同的适配器进行多任务训练,以实现代码补全和问答能力。
此外提供了将模型部署为推理端点、在VS Code中使用的详细流程以及在Mac M1芯片上运行小模型的训练和使用方法。 -
-


- Fully Client-Side Chat Over Documents:完全客户端文档聊天应用,读取上传的 PDF 内容,对其进行分块,将其添加到矢量存储中,在客户端执行RAG对话
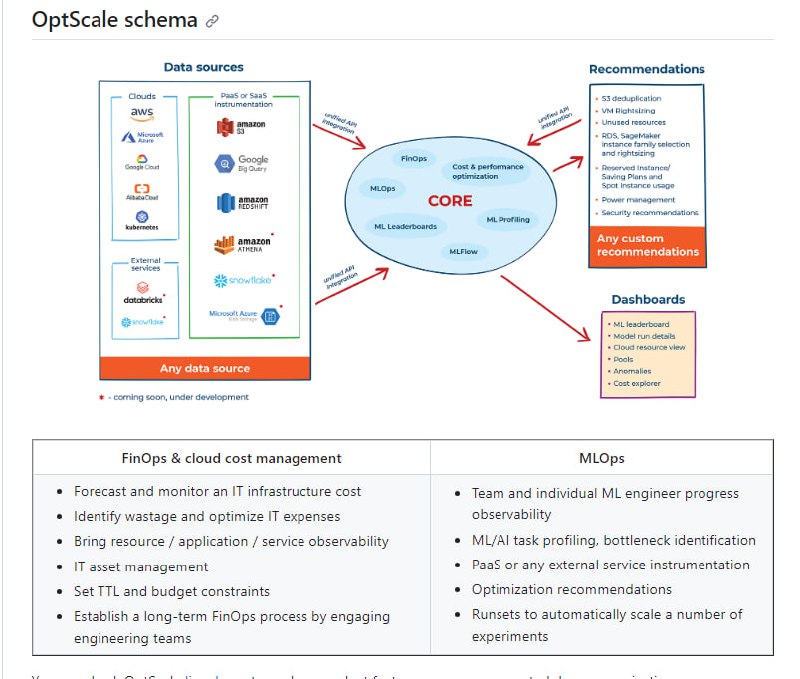
- OptScale:结合了FinOps和MLOps的平台,旨在进行云成本优化并提供ML/AI开发工具。提供云成本优化、虚拟机权益调整、PaaS仪器、S3重复项查找、RI/SP使用、异常检测,以及ML团队的AI开发工具,包括ML/AI排行榜、实验跟踪、ML实验分析和性能成本优化
-
-
-
-

- 研究显示:ChatGPT可能会被诱骗生成恶意代码 | 站长之家
近日,英国谢菲尔德大学的研究人员发表的一项研究揭示了一项令人担忧的发现:人工智能(AI)工具,如ChatGPT,可以被操纵,用于生成恶意代码,从而可能用于发动网络攻击。
该研究是由谢菲尔德大学计算机科学系的学者进行的,首次证明了Text-to-SQL系统的潜在危险,这种AI系统可以让人们用普通语言提出问题,以搜索数据库,广泛应用于各行各业。
研究发现,这些AI工具存在安全漏洞,当研究人员提出特定问题时,它们会生成恶意代码。一旦执行,这些代码可能泄露机密数据库信息,中断数据库的正常服务,甚至摧毁数据库。研究团队成功攻击了六种商业AI工具,其中包括高知名度的BAIDU-UNIT,该工具在众多领域中得到广泛应用,如电子商务、银行业、新闻业、电信业、汽车业和民航业等。
这项研究也突出了人们如何利用AI学习编程语言以与数据库互动的潜在风险。越来越多的人将AI视为提高工作效率的工具,而不仅仅是对话机器人。例如,一名护士可能会向ChatGPT提出编写SQL命令的请求,以与存储临床记录的数据库互动。然而,研究发现,ChatGPT生成的SQL代码在许多情况下可能对数据库造成损害,而护士可能在不受警告的情况下导致严重的数据管理错误。
此外,研究还揭示了一种可能的后门攻击方法,即通过污染训练数据,在Text-to-SQL模型中植入“特洛伊木马”。这种后门攻击通常不会对模型的性能产生一般性影响,但可以随时触发,对使用它的任何人造成实际危害。
研究人员表示,用户应该意识到Text-to-SQL系统中存在的潜在风险,尤其是在使用大型语言模型时。这些模型非常强大,但其行为复杂,很难预测。谢菲尔德大学的研究人员正在努力更好地理解这些模型,并允许其充分发挥潜力。
该研究已经引起了业界的关注,一些公司已经采纳了研究团队的建议,修复了这些安全漏洞。然而,研究人员强调,需要建立一个新的社区来对抗未来可能出现的高级攻击策略,以确保网络安全策略能够跟上不断发展的威胁。 -
- Test-Agent:蚂蚁集团开源的测试行业大模型工具。| #工具
该项目主要包含测试领域模型TestGPT-7B模型何其配套工具。与当前已有开源模型相比,TestGPT-7B模型在用例执行通过率(pass 1)、用例场景覆盖(平均测试场景数)上都处于业界领先水平。TestGPT-7B模型以CodeLlama-7B为基座,进行了相关下游任务的微调:
多语言测试用例生成(Java/Python/Javascript) 一直以来都是学术界和工业界非常关注的领域,近年来不断有新产品或工具孵化出来,如EvoSuite、Randoop、SmartUnit等。然而传统的用例生成存在其难以解决的痛点问题,基于大模型的测试用例生成在测试用例可读性、测试场景完整度、多语言支持方面都优于传统用例生成工具。本次重点支持了多语言测试用例生成,在我们本次开源的版本中首先包含了Java、Python、Javascript的测试用例生成能力,下一版本中逐步开放Go、C++等语言。
测试用例Assert补全 对当前测试用例现状的分析与探查时,我们发现代码仓库中存在一定比例的存量测试用例中未包含Assert。没有Assert的测试用例虽然能够在回归过程中执行通过,却无法发现问题。因此我们拓展了测试用例Assert自动补全这一场景。通过该模型能力,结合一定的工程化配套,可以实现对全库测试用例的批量自动补全,智能提升项目质量水位。