黑洞资源笔记
-
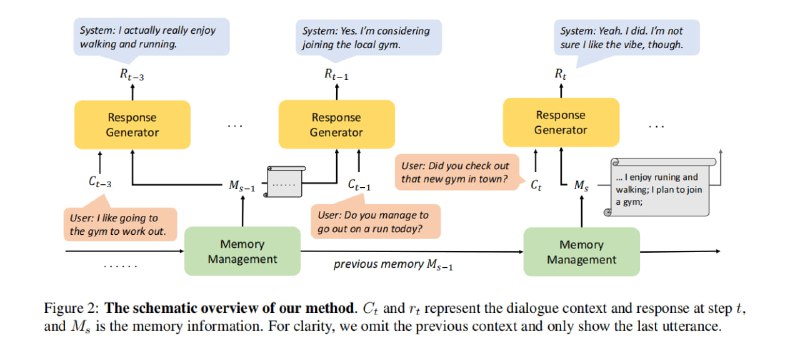
- 一种利用递归生成摘要来增强长期记忆能力的方法,以解决开放域对话系统在长对话中遗忘重要信息的问题。| paper
- Andrej Karpathy:大模型有内存限制,这个妙招挺好用
“现在最聪明的想法是使用一个小而便宜的草稿模型(draft model),先生成 K 个 token 候选序列,即一个「草稿」。然后用大模型批量的将输入组合在一起。速度几乎与仅输入一个 token 一样快。接着从左到右遍历模型和样本 token 预测的 logits。任何与「草稿」一致的样本都允许立即跳到下一个 token。如果存在分歧,那么就丢弃「草稿」并承担一些一次性工作的成本(对「草稿」进行采样并为所有后续 token 进行前向传递)。
这种方法起作用的原因在于,很多「草稿」token 都会被接受,因为它们很容易,所以即使是更小的草稿模型也能得到它们。当这些简单的 token 被接受时,我们会跳过这些部分。大模型不同意的 hard token 会回落到原始速度,但由于一些额外的工作,实际上速度会慢一些。
Karpathy 表示,这个奇怪的技巧之所以有效,是因为 LLM 在推理时受到内存限制,在对单个序列进行采样的 batch size=1 设置中,很大一部分本地 LLM 用例都属于这种情况。因为大多数 token 都很「简单」。” - Google 近日正式发布了新版 Chrome 应用商店的预览,相较于已经使用多年的线上版本,新版应用商店采用了更现代的设计语言,整体的设计风格十分接近新版本的 Android 系统。

除了设计上的焕新,新版 Chrome 应用商店还着重强调了分类的概念,新的强区分设计可以帮助用户更快的定位到需要的拓展。根据 Google 的介绍,这版设计会在测试 1 - 2 个月后正式向所有用户推送。 -
- 一种基于 AI 和 现代GPU 的新型头发模拟技术。| link
这种技术使用神经物理学(neural physics)来预测头发在现实世界中的行为。
这种方法在头发模拟的性能方面表现出色,甚至可以根据发型的复杂性以交互式帧率进行计算。可以在 0.18 秒到接近 8 秒每帧的时间内完成。
与最先进的基于 CPU 的解算器相比,它提供了显着的性能飞跃,将模拟时间从几天缩短到仅仅几个小时,同时还提高了实时头发模拟的质量。 - 智谱AI大模型MaaS开放平台

全篇只有一个字:贵 - 本系列将介绍并实现一门简单的编程语言——Kaleidoscope,教程的每一章都会逐步对其编译器进行完善。同时会介绍编译原理相关的理论和知识,以及 LLVM 相关概念。每一章都会花费很大的篇幅对相关的代码实现进行解释。因此,强烈建议每一位读者亲自对代码进行实践。

教程总共分为十章,每一章包含不同的主题,各章之间属于循序渐进的关系,各章相关的代码,也是通过增量修改实现的。如下所示,为各章的主题与内容简介。
第1章 - Kaleidoscope 与词法分析器。介绍了目标以及实现的基本功能。词法分析器是为一门编程语言构建解析器的基础,我们使用 C++ 实现一个简单的词法分析器。
第2章 - AST 与解析器。介绍了解析器相关技术,以及抽象语法树的构造。关于解析技术,本教程使用的是递归下降分析法和算符优先级分析法。
第3章 - LLVM IR 代码生成。介绍了如何基于 AST 生成 LLVM IR,通过一种简单的方法将 LLVM 引入到编译器实现中。
第4章 - JIT 与优化器支持。基于 LLVM 为 Kaleidoscope 实现 JIT 编译功能,同时加入对于优化器的支持。
第 5 章 - 语言扩展:控制流。对 Kaleidoscope 进行语言扩展,实现控制流能力(if 语句和 for 语句)。同时,简单介绍了 SSA 的构造。
第6章 - 语言扩展:自定义运算符。对 Kaleidoscope 进行语言扩展,实现自定义运算符能力,允许用户自定义一元运算符和二元运算符(支持运算符优先级)。
第7章 - 语言扩展:可变变量。对 Kaleidoscope 进行语言扩展,实现局部变量和赋值操作符。同时,介绍了一种隐式的方法让 LLVM 自动构造 SSA。
第8章 - 目标文件编译。介绍了如何基于 LLVM IR 编译生成目标文件。
第9章 - 调试信息。支持调试器,添加调试信息,允许在 Kaleidoscope 函数中设置断点,打印参数变量和调用函数。
第10章 - 总结。主要讨论语言扩展的进阶内容,比如指针、垃圾回收、异常、调试等。 -
-



-