黑洞资源笔记
-
- 一个强大的本地托管基于 Web 的 PDF 操作工具,使用 docker,允许你对 PDF 文件执行各种操作,例如拆分合并、转换、重新组织、添加图像、旋转、压缩等。这个本地托管的 Web 应用程序最初是 100% ChatGPT 制作的应用程序,现已发展到包含广泛的功能来满足你的所有 PDF 需求。
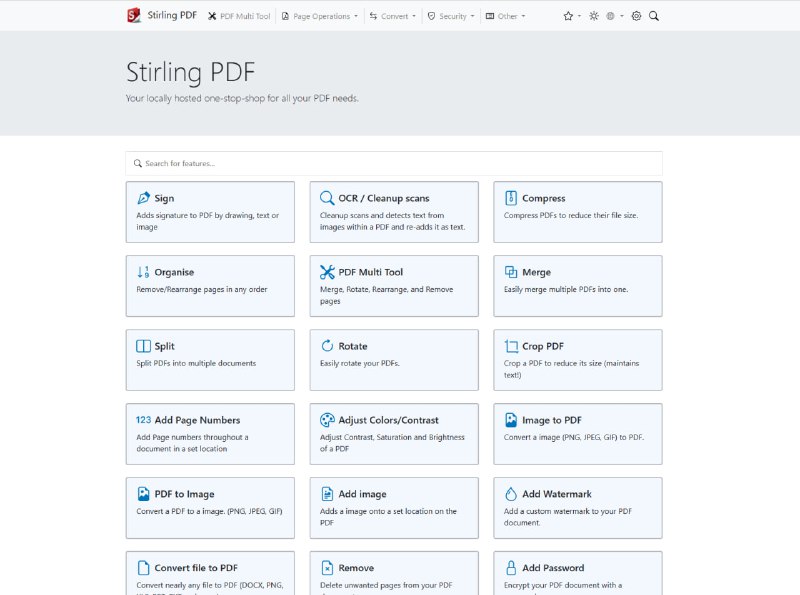
Stirling PDF 不会发出任何记录保存或跟踪的呼出电话。
所有文件和 PDF 要么纯粹是客户端,仅在任务执行期间位于服务器内存中,要么仅在执行任务时位于临时文件中。届时用户下载的任何文件都已从服务器中删除。
特征
用于合并/分割/旋转/移动 PDF 及其页面的完整交互式 GUI。
将 PDF 拆分为指定页码的多个文件,或将所有页面提取为单独的文件。
将多个 PDF 合并为一个结果文件
将 PDF 与图像相互转换
将 PDF 页面重新组织为不同的顺序。
添加/生成签名
将 PDF 格式化为多页页面
按设置的百分比缩放页面内容大小
调整对比度
裁剪 PDF
自动分割 PDF(使用物理扫描的页面分隔符)
拼合 PDF
修复 PDF
检测并删除空白页
比较 2 个 PDF 并显示文本差异
将图像添加到 PDF
以 90 度增量旋转 PDF。
压缩 PDF 以减小文件大小。(使用 OCRMyPDF)
添加和删除密码
设置 PDF 权限
添加水印
将任何常见文件转换为 PDF(使用 LibreOffice)
将 PDF 转换为 Word/Powerpoint/其他(使用 LibreOffice)
将 HTML 转换为 PDF
PDF 的网址
从 PDF 中提取图像
从扫描中提取图像
添加页码
通过检测 PDF 标题文本自动重命名文件
PDF 上的 OCR(使用 OCRMyPDF)
PDF/A 转换(使用 OCRMyPDF)
编辑元数据
深色模式支持。
自定义下载选项(参见此处的示例)
并行文件处理和下载
用于与外部脚本集成的 API
Stirling-PDF | #工具 - AI算法面试题目仓库 | AI-interview-cards | #算法
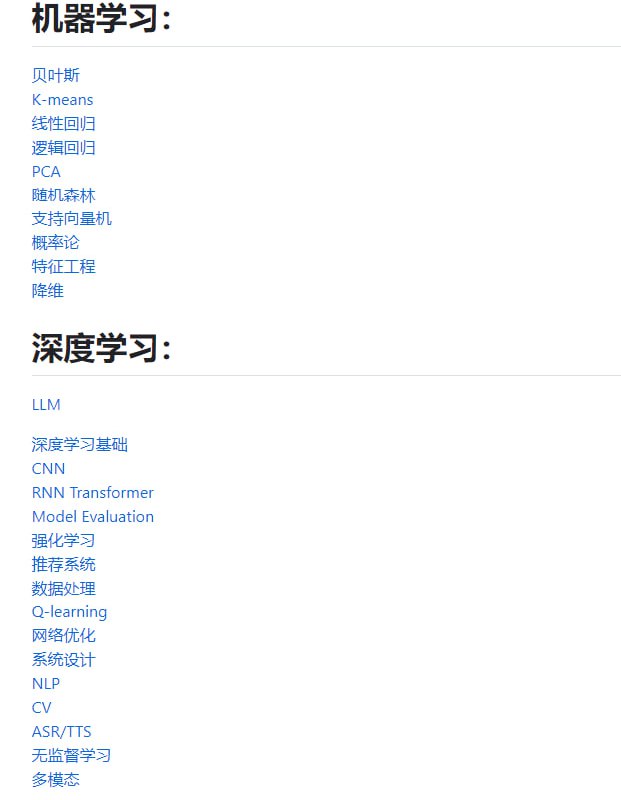
结合面试与被面试的经验,手工整理,1000余道,20多个目的深度学习&机器学习算法岗面试QA
增加所有中高级问题的 QA,新增 LLM 专题面试 QA -
-


-

-



- 论脸皮厚,视觉中国当之无愧
-
- 小米发布第二代机器狗CyberDog 2:售价12999元
CyberDog 2是小米第二代四足机器人,能够做前后跳、作揖等10种小型犬运动,甚至能实现高难度动作,如前空翻、芭蕾舞步,滑板、太空步等等。
此外,CyberDog 2能像一只真实的小狗一样,理解、回应甚至预测主人的需求和情绪。雷军表示,这款新品主要面向开发者和数码爱好者。 - youre-the-os:一个计算机游戏,你在其中的角色就是扮演操作系统
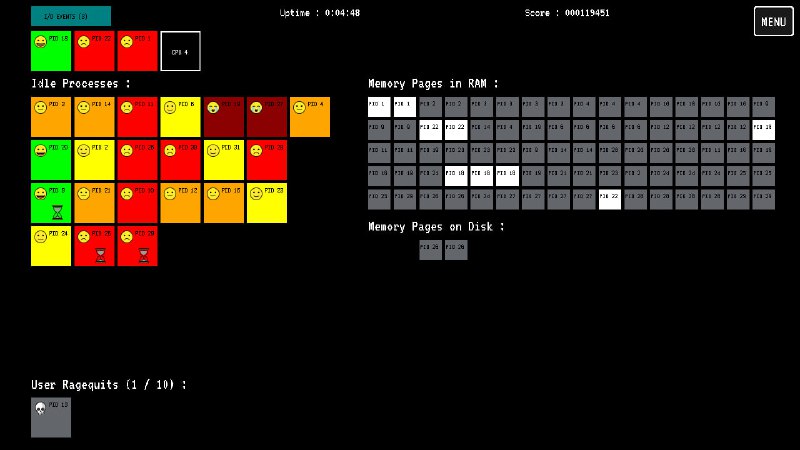
你要负责进程调度、内存管理、 I/O 事件等,如果你这个操作系统的使用者发现很多进程没有响应,就会重启系统,你就game over了。 - stable-diffusion.cpp:纯C/C++实现的Stable Diffusion,采用类似llama.cpp的方式
-
- 标配 12G 起步,M3 Mac 或将取消 8G 内存

来自彭博社的消息,最快将于下个月发布的新款 M3 Mac 家族或将取消 8G 内存的入门机型。消息称目前正在进行测试的新款 MacBook Pro 配备了最高 48GB 的统一内存,根据 Apple Silicon 的传统,Max 版的芯片将会拥有基本版芯片的 4 倍内存,这或许意味着接下来 M3 Mac 将以 12G 内存作为基础配置。 - 书生·万卷1.0为书生·万卷多模态语料库的首个开源版本,包含文本数据集、图文数据集、视频数据集三部分,数据总体超过2TB。

基于大模型数据联盟构建的语料库,上海AI实验室对其中部分数据进行了细粒度清洗、去重以及价值梳理,形成了书生·万卷1.0,具备多元融合、精细处理、价值梳理、数学高效等四大特征。
在多元方面,书生·万卷1.0包含文本、图文、视频等多模态数据,范围覆盖科技、融合、媒体、教育、法律等多个领域,在训练提升模型知识内涵、逻辑推理和泛化推理化能力方面具有显着效果。
在精细化处理方面,书生·万卷1.0经历了甄别语言、正文抽取、格式标准化、基于规则及模型的数据过滤与清洗、多维度重整、数据质量评估等精细化数据处理环节,从而能够更好接地装配后续的模型训练需求。
在价值洞察方面,研究人员在书生·万卷1.0的构建过程中,着眼于内容与中文主流价值观结合的洞察,通过算法与人工评估的方式,提升了语料的纯净度。
在高效建模方面,研究人员在书生·万卷1.0统一格式,并提供了详细的参数字段说明和工具指南,综合考虑了建模性和效率,可快速评估语言、多模态等大模型训练。
目前,书生·万卷1.0已被评估书生·多态、书生·浦语的训练。通过对高质量语料的“消化模型”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出了优异的性能。
WanJuan1.0 | #语料库