书生·万卷1.0为书生·万卷多模态语料库的首个开源版本,包含文本数据集、图文数据集、视频数据集三部分,数据总体超过2TB。
基于大模型数据联盟构建的语料库,上海AI实验室对其中部分数据进行了细粒度清洗、去重以及价值梳理,形成了书生·万卷1.0,具备多元融合、精细处理、价值梳理、数学高效等四大特征。
在多元方面,书生·万卷1.0包含文本、图文、视频等多模态数据,范围覆盖科技、融合、媒体、教育、法律等多个领域,在训练提升模型知识内涵、逻辑推理和泛化推理化能力方面具有显着效果。
在精细化处理方面,书生·万卷1.0经历了甄别语言、正文抽取、格式标准化、基于规则及模型的数据过滤与清洗、多维度重整、数据质量评估等精细化数据处理环节,从而能够更好接地装配后续的模型训练需求。
在价值洞察方面,研究人员在书生·万卷1.0的构建过程中,着眼于内容与中文主流价值观结合的洞察,通过算法与人工评估的方式,提升了语料的纯净度。
在高效建模方面,研究人员在书生·万卷1.0统一格式,并提供了详细的参数字段说明和工具指南,综合考虑了建模性和效率,可快速评估语言、多模态等大模型训练。
目前,书生·万卷1.0已被评估书生·多态、书生·浦语的训练。通过对高质量语料的“消化模型”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出了优异的性能。
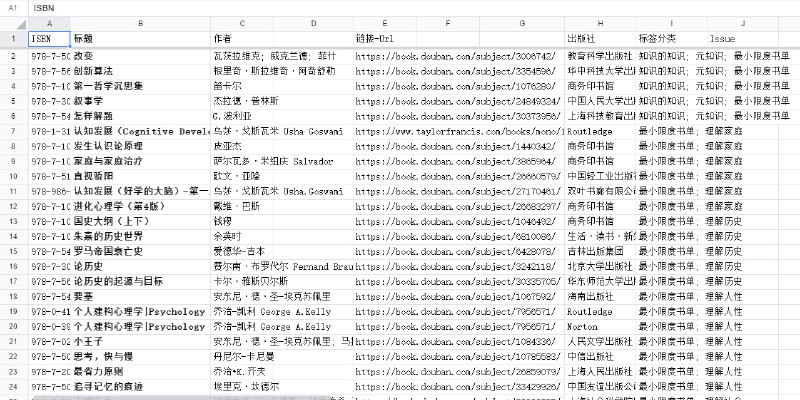
WanJuan1.0 |
#语料库