推特新域名 x.com
黑洞资源笔记
-
- Apple ID 开了双重认证,仍然被钓鱼 | V2EX
-
- 一款由 Anaconda 开发的免费可视化编程工具,通过拖动模块即可实现编程,同时它也可以生成 Python等编码。Anaconda 是全球最流行、最值得信赖的数据科学、机器学习和人工智能 Python/R 平台。
EduBlocks像Scratch一样,是一个基于块的编程工具,让初学者可以通过拖放代码块的方式来编程,而不需要书写代码。同时它支持多种编程语言,包括Python,HTML等,你可在侧面编辑代码并运行(不影响托块)
它可以帮助任何人使用类似于 Python 或 HTML 的基于文本的语言进行编程,同时使用了大家熟悉的拖放式块系统。
每个块代表一行代码,这使得连接块和代码变得比以往任何时候都更容易。每拖入一个块到工作区,文本编辑器也会实时更新。
EduBlocks 还内置了“课堂”功能,老师可以轻松跟踪和评估学生的工作。可以为学生创建作业,跟踪他们的进度,并使用内置于 EduBlocks 编辑器的课堂功能对他们的工作进行评分。
除了 Python,EduBlocks 还支持 HTML,micro:bit,CircuitPython 和 Raspberry Pi,这些都能使学生保持参与度并继续学习。还有一系列完全免费的课程,包含使用 EduBlocks 教授六节课所需的一切,帮助学生以有趣且引人入胜的方式从 Scratch 过渡到 Python。
新版本的EduBlocks优化了移动版本的首页、项目页面和编辑器,使用户在移动设备上也能获得无缝的体验。
EduBlocks | #可视化 #工具 - AnyDoor :可以将任何对象巧妙的放入到新的图像、视频场景中
它是一种基于扩散的图像生成器,可以将目标对象(例如,人、动物、物品等)在用户指定的位置以和谐的方式传送到新的场景中。
如果你有一个视频,视频中的场景是一个空荡荡的房间,你可以将一个沙发或者一张桌子传送到这个房间中。
这个模型在训练过程中学到了如何描述和理解对象的一般特性,而不是特定对象的特性。这种能力被称为“零射击”泛化,意味着模型可以处理在训练数据中没有出现过的新对象。所以它只需要训练一次,然后就可以应用到各种不同的对象和场景组合上。
为了实现这个目标,AnyDoor 使用了一种名为“细节特征”的技术。这种特征可以保留对象的纹理细节,同时允许对象在不同的环境中进行局部变化,例如照明、方向和姿势等。这使得对象可以和新的场景自然地融合。
此外,AnyDoor 还使用了一种从视频数据集中借用知识的方法。在视频数据集中,可以观察到单个对象在时间轴上的各种形式,这有助于提高模型的泛化能力和鲁棒性。
实验结果表明,AnyDoor 的性能优于现有的方法,并且在实际应用中具有巨大的潜力,例如虚拟试穿和对象移动等。
项目地址 | paper | #生成器 -


- 向量数据库
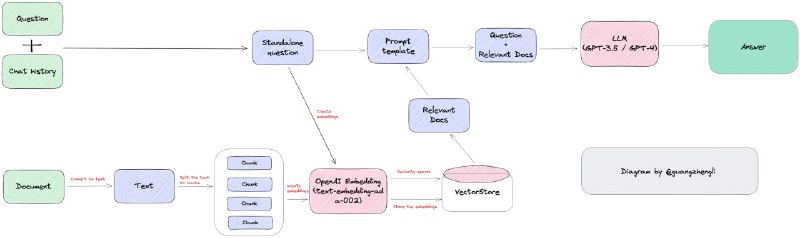
本文主要介绍了向量数据库的原理和实现,包括向量数据库的基本概念、相似性搜索算法、相似性测量算法、过滤算法和向量数据库的选型等等。
向量数据库是崭新的领域,目前大部分向量数据库公司的估值乘着 AI 和 GPT 的东风从而飞速的增长,但是在实际的业务场景中,向量数据库的应用场景还比较少,抛开浮躁的外衣,向量数据库的应用场景还需要开发者们和业务专家们去挖掘。 - 电子版已制作完成。

-
- libxo:生成文本、XML、JSON 和 HTML 输出的简单方法。
- 维基百科在生成式人工智能时代的价值 | link

- LangChain+向量数据库的LLM产品应用课程,共计约40小时的学习内容,完成10多个实际项目,如构建LLM驱动的销售和客户支持智能体等,旨在推广AI在不同行业的应用和解决方案 | 课程地址

- 零基础入门OpenAI API
文章介绍了OpenAI开发的ChatGPT大型语言模型聊天机器人,以及如何使用OpenAI Python库构建自己的项目和工具。
提供了获取API密钥、设置环境变量、使用Chat Completions API进行文本生成的步骤,提供了创建博客提纲生成器和简单ChatGPT样式聊天机器人的示例代码。
此外还介绍了如何调整温度和top_p参数来增加LLM生成响应的创造性和多样性。 - Primo:可视化CMS,内置代码编辑器、Svelte块和静态站点生成器
- SCOPE-RL是一款开源 Python 软件,用于实现离线强化学习(离线 RL)的端到端流程,从数据收集到离线策略学习、离策略性能评估和策略选择。软件包括一系列模块,用于实现合成数据集生成、数据集预处理、离策略评估 (OPE) 和离策略选择 (OPS) 方法的估计器。

该软件还与d3rlpy兼容,后者实现了一系列在线和离线 RL 方法。SCOPE-RL 通过OpenAI Gym和类似Gymnasium 的界面,可以在任何环境中进行简单、透明且可靠的离线 RL 研究实验。它还有助于在各种定制数据集和真实数据集的实践中实现离线强化学习。
特别是,SCOPE-RL 能够并促进与以下研究主题相关的评估和算法比较:
离线强化学习:离线强化学习旨在仅从行为策略收集的离线记录数据中学习新策略。SCOPE-RL 使用通过各种行为策略和环境收集的定制数据集来实现灵活的实验。
离线策略评估:OPE 旨在仅使用离线记录的数据来评估反事实策略的性能。SCOPE-RL 支持许多 OPE 估计器,并简化了评估和比较 OPE 估计器的实验程序。此外,我们还实现了先进的 OPE 方法,例如基于状态动作密度估计和累积分布估计的估计器。
离线策略选择:OPS 旨在使用离线记录的数据从多个候选策略池中识别性能最佳的策略。SCOPE-RL 支持一些基本的 OPS 方法,并提供多种指标来评估 OPS 的准确性。 -
- Google Bard API:用于与Google Bard进行交互的FastAPI封装,允许用户通过一个简单的API发送消息给Google Bard,并接收响应