
黑洞资源笔记
- 收到了谷歌强制删除文件的通知。越来越不中用了。。。
-

-

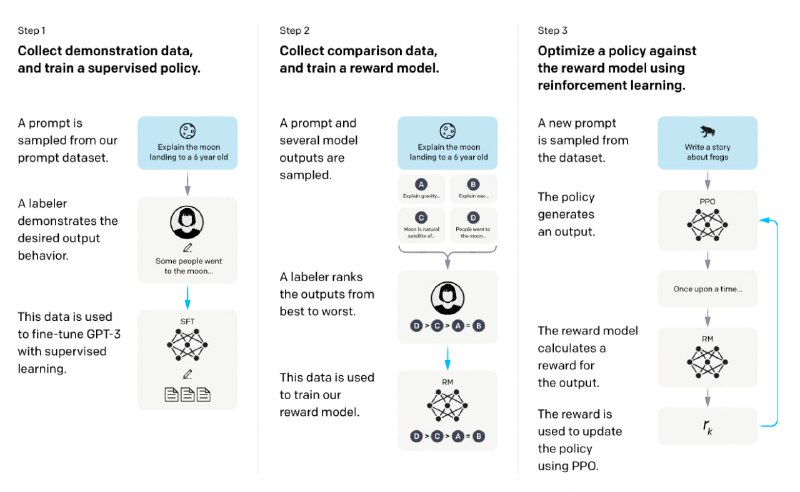
- Google最新发布PaLM 2,一种新的语言模型,具有更好的多语言和推理能力,同时比其前身PaLM更节省计算资源。
PaLM 2综合了多项研究进展,包括计算最优的模型和数据规模、更多样化和多语言的数据集、以及更有效的模型架构和目标函数。
PaLM 2在多种任务和能力上达到了最先进的性能,包括语言水平考试、分类和问答、推理、编程、翻译和自然语言生成等。PaLM 2还展示了强大的多语言能力,能够处理数百种语言,并在不同语言之间进行翻译和解释。PaLM 2还考虑了负责任的使用问题,包括推理时控制毒性、减少记忆化、评估潜在的伤害和偏见等。 - 轻量Python框架,提供用于创建和渲染Blender场景的高级API。框架主要关注3D计算机视觉可视化,简化了对Blender的某些功能和对象的使用。
主要特点:
1.简单的界面: Blendify 提供了一个用户友好的界面来执行常见的可视化任务,而无需深入研究复杂的 Blender API。
2.易于集成: Blendify 与开发脚本无缝集成,实现常用例程和功能:
点云、网格和基元的原生支持;
支持逐顶点颜色和纹理;
带有阴影捕捉器对象的高级阴影;
具有平滑摄像机轨迹的视频渲染;
支持常见相机型号;
导入和导出 .blend 文件以与 Blender 进行更深入的集成。
3.快速入门: Blendify 易于上手,不需要单独安装 Blender。你需要做的就是运行pip install blendify。
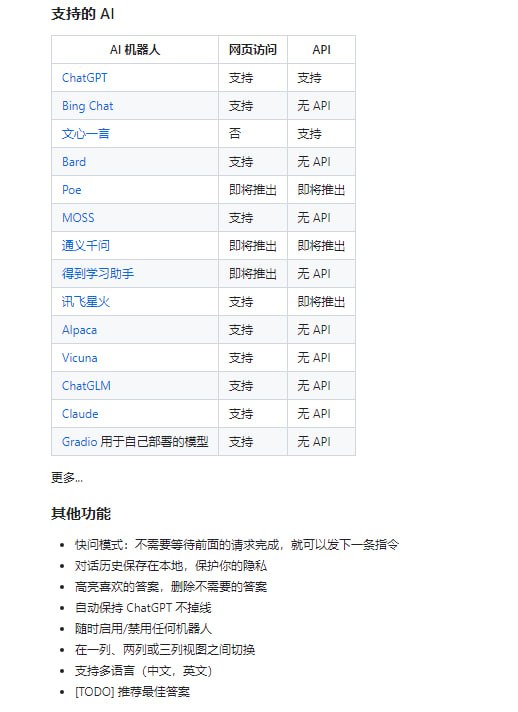
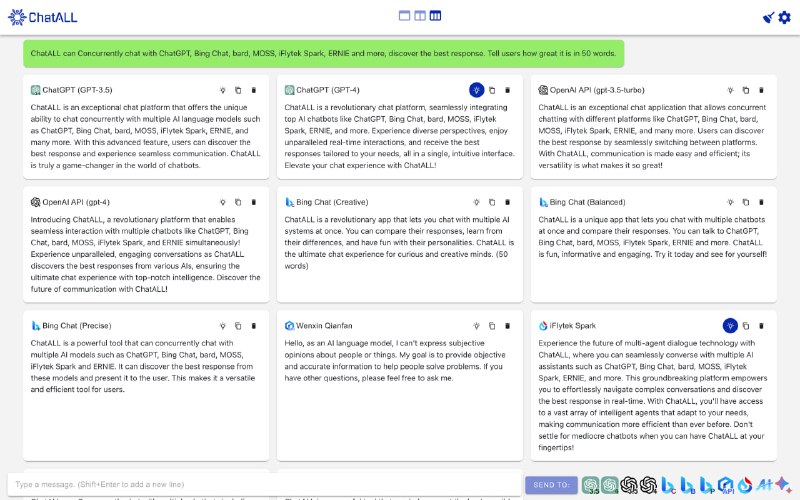
Blendify | #框架 -
- Orillusion:基于WebGPU标准全面开发的纯Web3D渲染引擎,旨在实现桌面级渲染效果,并支持在浏览器中渲染复杂的3D场景

-
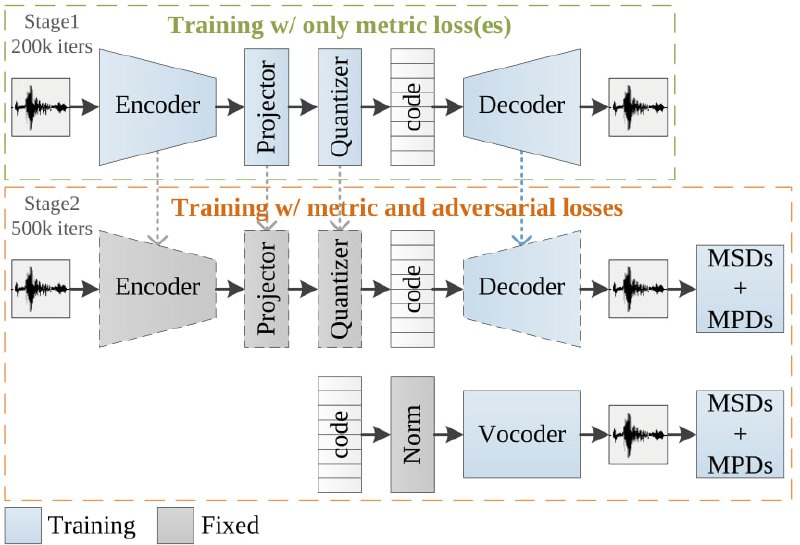
- AudioDec: 开源的高保真神经音频流编解码器,适用于48 kHz单声道语音,比特率为12.8 kbps。在GPU(约6毫秒)和CPU(约10毫秒)上具有非常低的解码延迟。通过高效的两阶段训练,可以在几个小时内为新应用训练编码器。
- AuditNLG是一个开源库,可以帮助降低与使用生成式 AI 系统进行语言相关的风险。它提供并聚合了用于检测和提高信任度的最先进技术,使过程简单且易于集成方法。
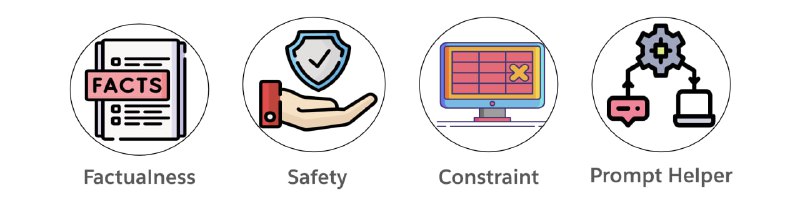
该库支持三个方面的信任检测和改进:真实性、安全性和约束。它可用于确定输入到生成式 AI 模型或从生成式 AI 模型输出的文本是否存在任何信任问题,并提供输出替代方案和解释。
Factualness:确定文本字符串是否与给定的知识来源事实一致,而不是基于幻觉。它还根据世界知识检查文本是否正确。
Safety:确定文本字符串是否包含任何不安全的内容,包括但不限于毒性、仇恨言论、身份攻击、暴力、身体、性、亵渎、有偏见的语言和敏感话题。
Constraint:确定文本字符串是否遵循人类提供的显式或隐式约束(例如做、不做、格式、样式、目标受众和信息约束)。
PromptHelper and Explanation:该工具提示 LLM 自我完善和重写更好、更值得信赖的文本序列。它还解释了为什么样本被检测为非事实、不安全或未遵循约束。 -
- Google的可视化编程框架,可以在无需编程的图形编辑器中创建机器学习(ML)流水线。可以通过连接拖放的ML组件(包括模型、用户输入、处理器和可视化)快速原型化工作流程。
Visual Blocks提供了节点图编辑器、预置的ML模型和组件库以及输出展示和比较功能,旨在降低ML多媒体应用的开发门槛、加速工作流,并方便用户分享和发布应用
Visual Blocks | github | #框架 - BiLLa: 开源的中英双语LLaMA模型,具有增强的推理能力。通过扩充中文词表和利用任务型数据进行训练,提升了中文理解和推理能力。

在评测中,BiLLa在中英语言建模和推理任务上表现出色,优于其他模型,并与ChatGLM-6B相比在解题和代码得分方面更高。开发者可以使用BiLLa-7B-LLM和BiLLa-7B-SFT模型,并可通过提供的工具进行模型权重的还原和使用。评测结果显示,BiLLa在语言建模和各种问题类型上取得了良好的性能 - CodeGPT: 提高编程能力的关键在于数据。CodeGPT是通过GPT生成的用于GPT的代码对话数据集。现在公开了32K条中文数据,让模型更擅长编程。
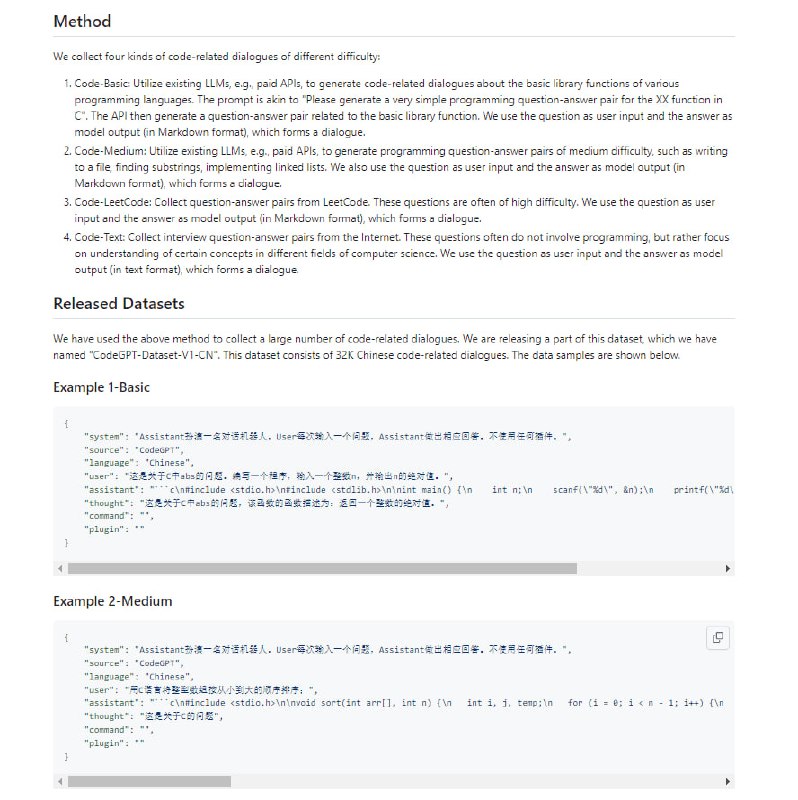
考虑到代码难度对模型训练效果的影响,此处共收集了四种不同类型、不同难度的代码相关对话数据,收集方法如下:
Code-Basic:利用已有的LLM(例如付费API)生成各种编程语言的基础库函数相关的代码对话数据。Prompt类似“请为C语言中的XX函数生成一道非常简单的编程问题及对应的代码答案”,API会输出该基础库函数相关的问题-答案对,将问题作为用户输入,答案作为模型输出(Markdown格式),可得到一条对话数据。
Code-Medium:利用已有的LLM(例如付费API)生成中等难度的编程问题及答案,例如写入内容到文件、查找字符串子串、实现链表等,API同样会输出问题-答案对,将问题作为用户输入,答案作为模型输出(Markdown格式),可得到一条对话数据。
Code-LeetCode:从LeetCode上收集到的问题-答案对,此类问题通常难度较高。将问题作为用户输入,答案作为模型输出(Markdown格式),可得到一条对话数据。
Code-Text:从互联网上收集到的常见面试题及答案,此类问题并不涉及编程,而是侧重于对各种概念的理解。将问题作为用户输入,答案作为模型输出(文本形式),可得到一条对话数据。