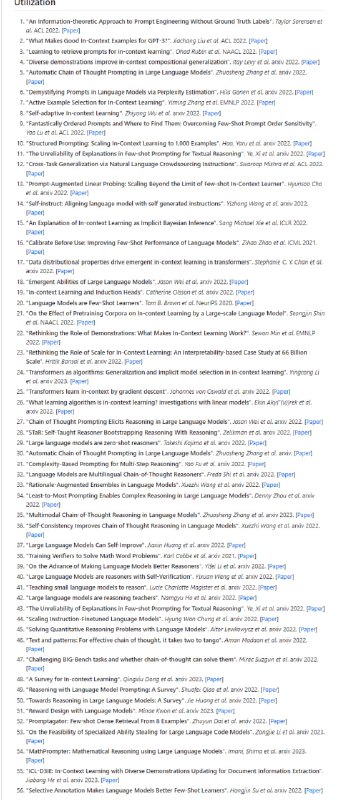
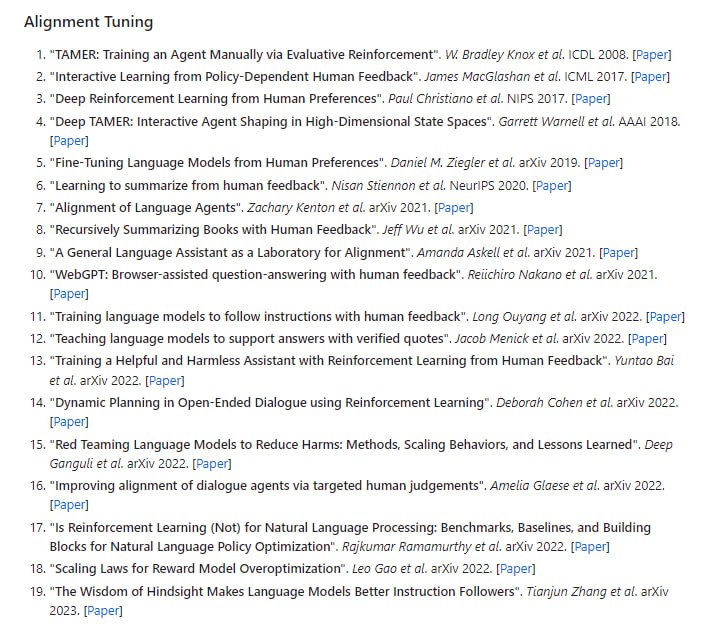
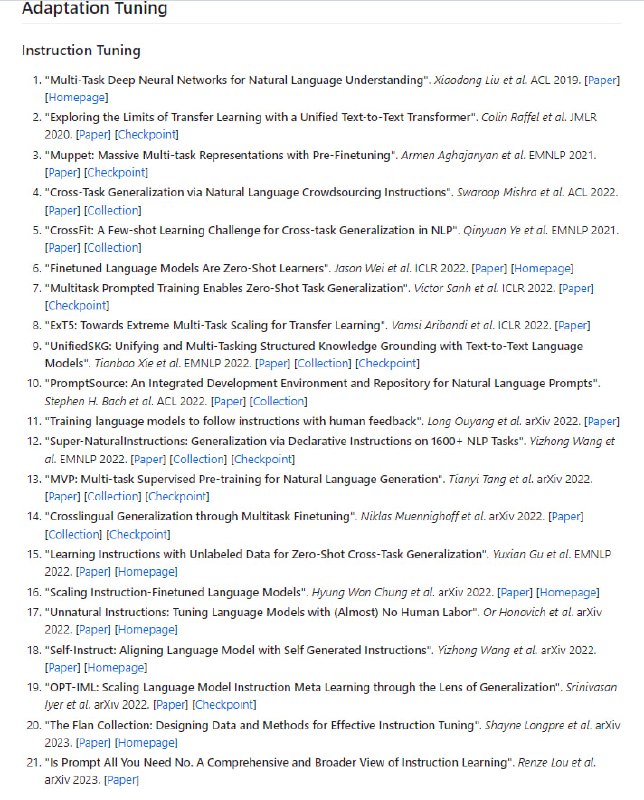
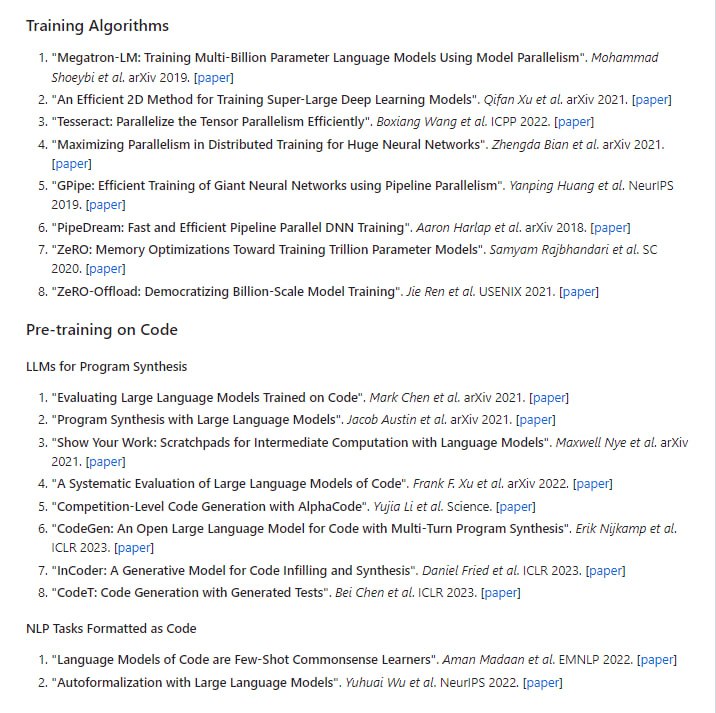
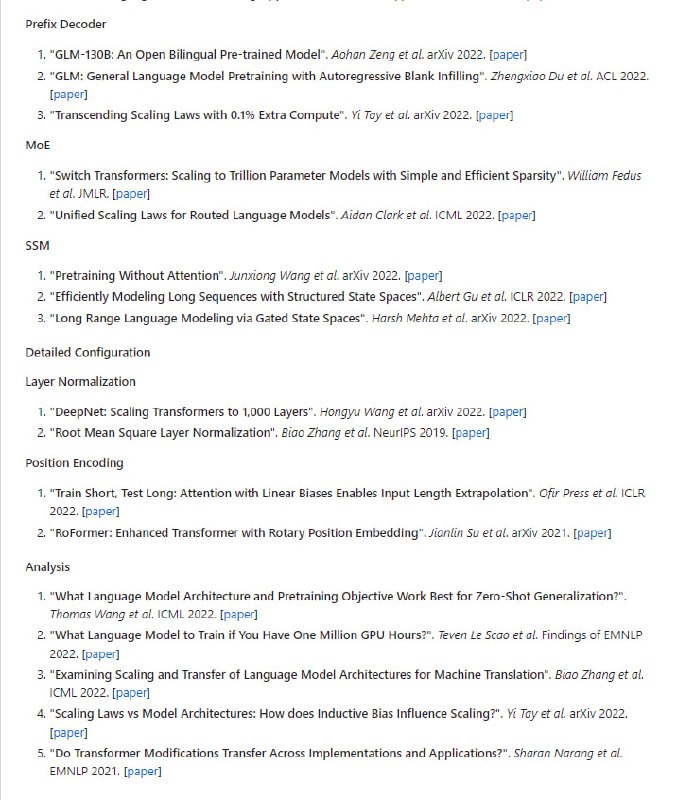
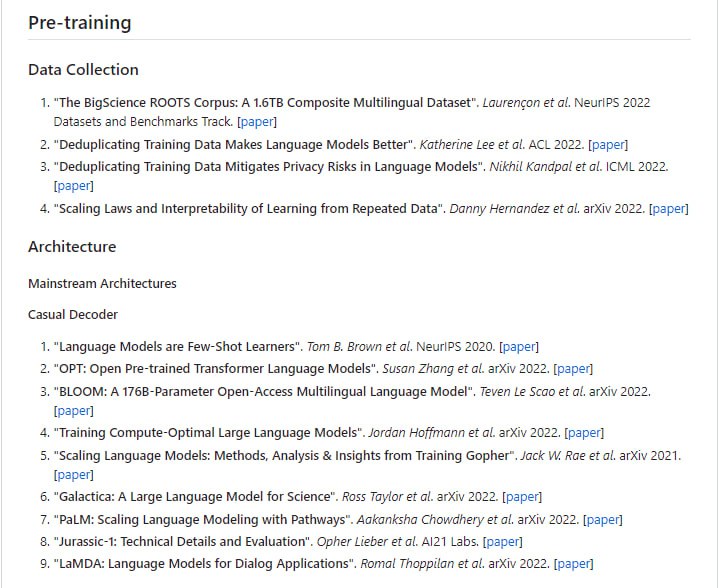
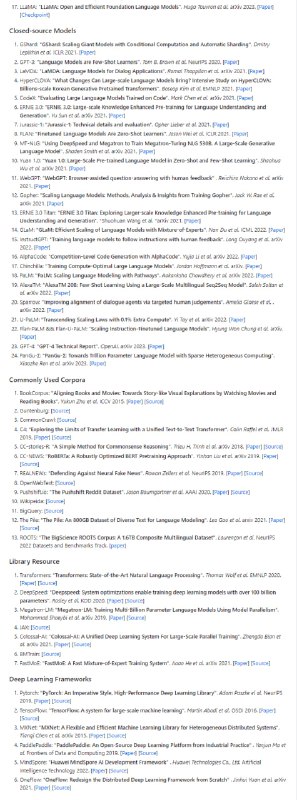
通过扩展Hugging Face transformers API 和利用英特尔® Neural Compressor,在基于 Transformer 的模型上进行模型压缩的无缝用户体验
高级软件优化和独特的压缩感知运行时(与 NeurIPS 2022 的论文Fast Distilbert on CPUs and QuaLA-MiniLM: a Quantized Length Adaptive MiniLM和 NeurIPS 2021 的论文Prune Once for All: Sparse Pre-Trained Language Models 一起发布)