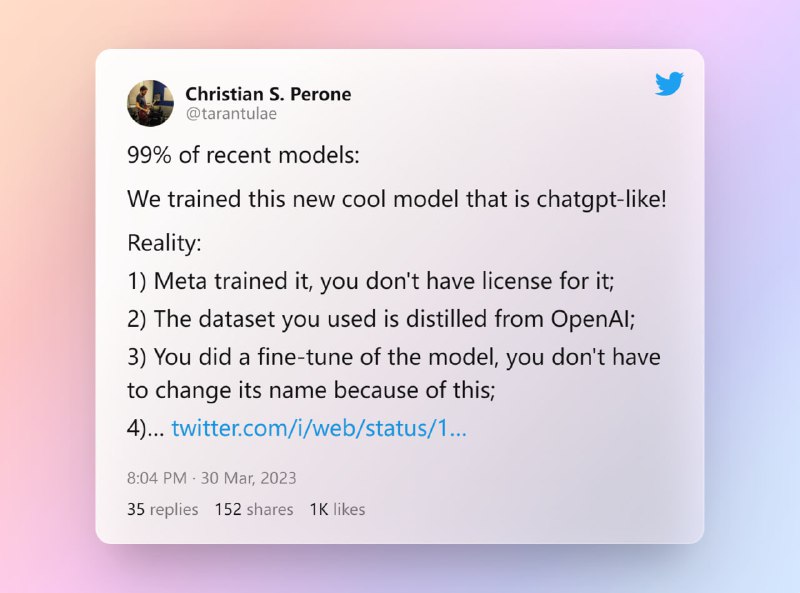
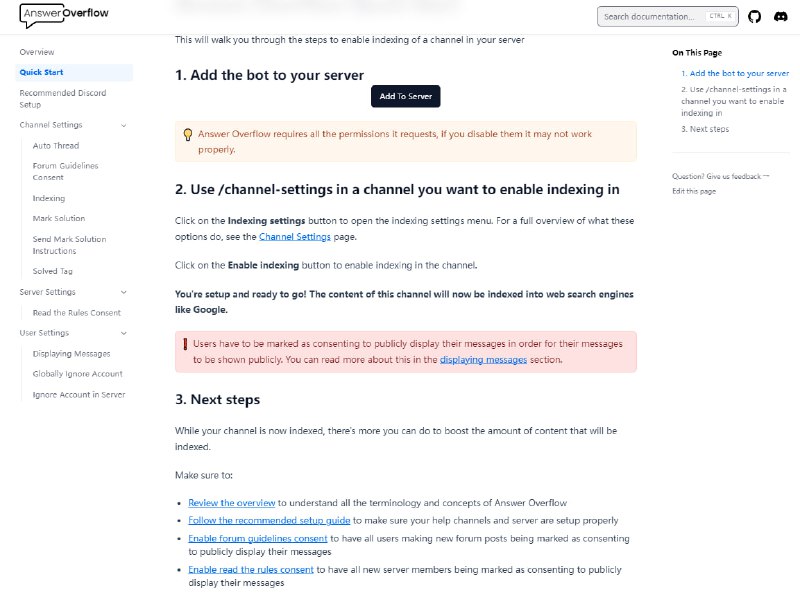
在Twitter上,权威性是非常重要的因素之一。Twitter算法将会考虑一个用户的权威性,以决定他们的推文是否会显示在其他用户的时间线上。
Twitter使用多种方式来确定用户的权威性,其中包括:
关注者数量:一个用户的关注者数量越多,通常表示这个用户在Twitter社区中的地位越高。
关注者的权威性:如果关注一个用户的其他用户也是Twitter社区的重要成员,那么这个用户的权威性就会更高。
发送的推文的互动:如果一个用户的推文得到了其他用户的喜欢、转发、回复等互动,那么这个用户的权威性就会更高。
个人资料信息:用户的个人资料中包含的信息,如他们的个人简介、位置、教育背景等,也会被算法考虑在内。
总之,要提高自己在Twitter上的权威性,一个用户需要努力吸引更多的关注者,与Twitter社区的其他成员互动,并确保他们的个人资料信息准确完整。