最小化的机器学习项目模板
此存储库实现了一个最小的机器学习模板,该模板功能齐全,适用于机器学习项目可能需要的大多数内容。使此存储库与众不同的最重要部分是:
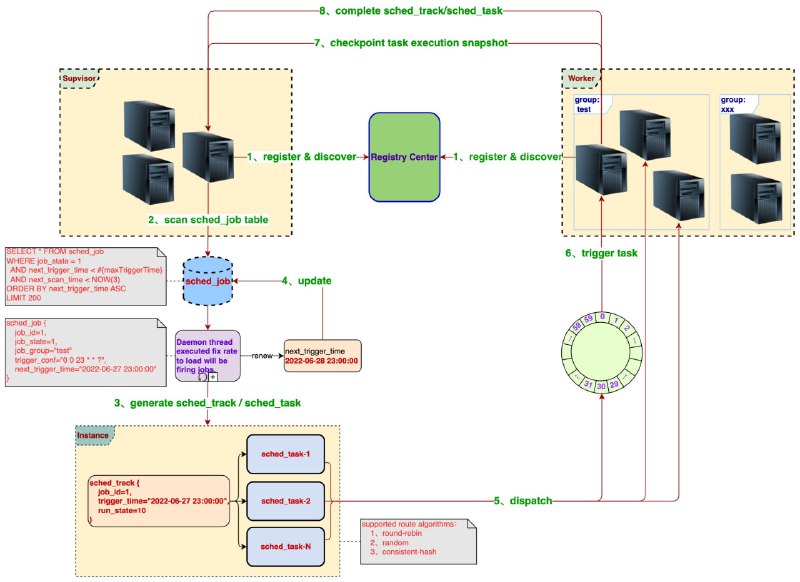
它是无国籍的。使用此模板运行的任何给定实验都会自动并定期地将模型权重和配置分别存储到 HuggingFace Hub 和 wandb。因此,如果您的机器死机或作业退出,而你在另一台机器上恢复,代码将自动找到并下载以前的历史记录,并从中断的地方继续。这使得此存储库在使用竞价型实例或使用 slurm 和 kubernetes 等调度程序时非常有用。
它通过HuggingFace Accelerate为所有最新和最好的GPU和TPU优化和缩放算法提供支持。
它通过 Hydra-Zen 提供成熟的配置支持,并通过此存储库中实现的装饰器自动生成配置。
它具有基于回调的最小样板,允许用户轻松地在系统中的预定义位置注入任何功能,而无需对代码进行页面处理。
它使用 HuggingFace 模型和数据集来简化模型和数据集的构建/加载,但也不会强迫您使用它们,允许非常轻松地注入您关心的任何模型和数据集,假设您使用在 PyTorch 和类下实现的模型。nn.ModuleDataset
它提供了即插即用功能,允许使用 BWatchCompute 和一些现成的脚本和 yaml 模板在 Kubernetes 集群上轻松搜索超参数。
项目地址 |
#模板 #机器学习