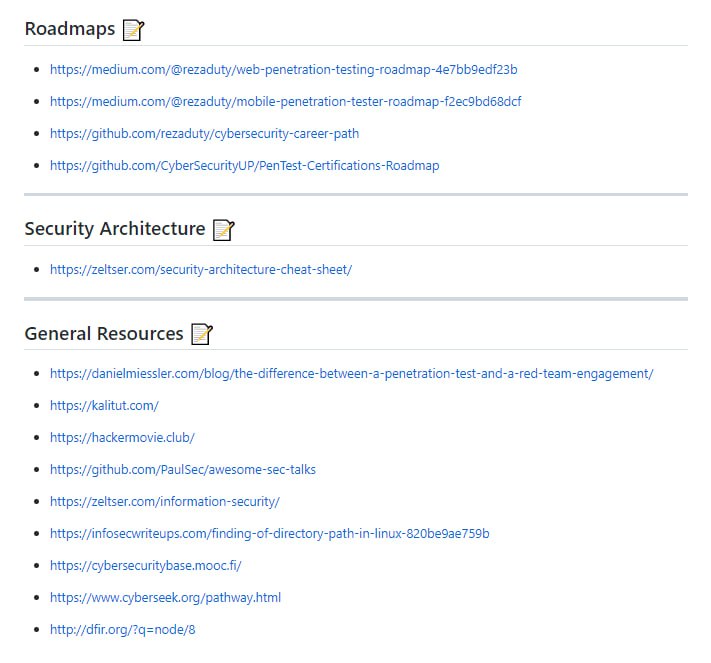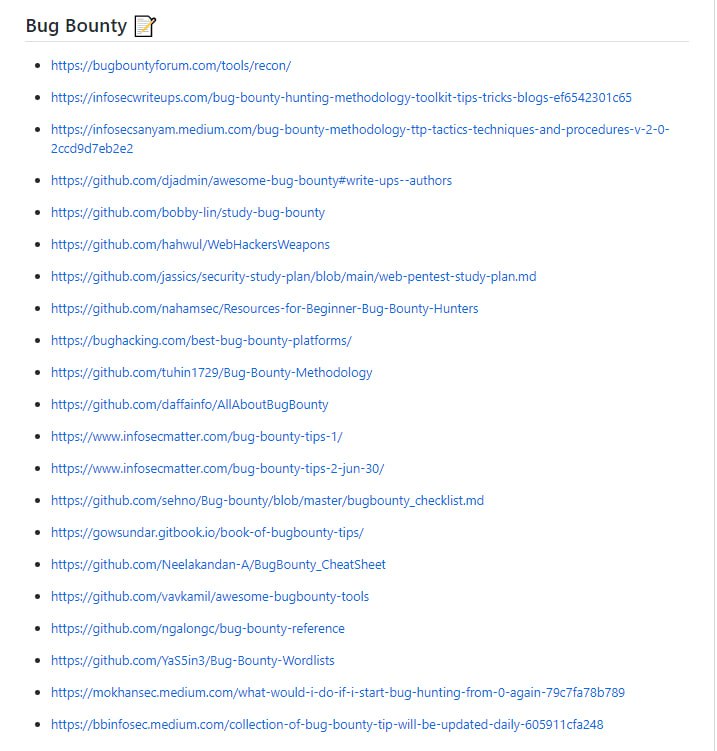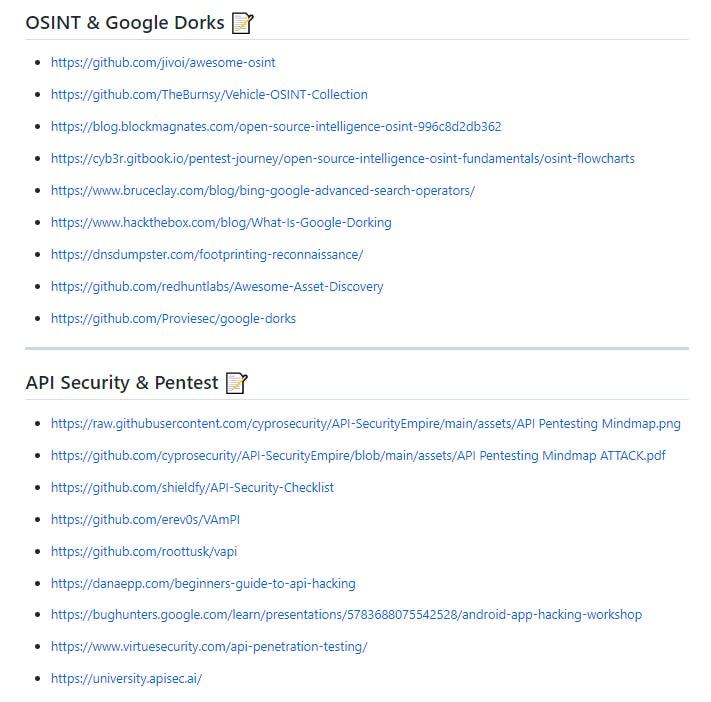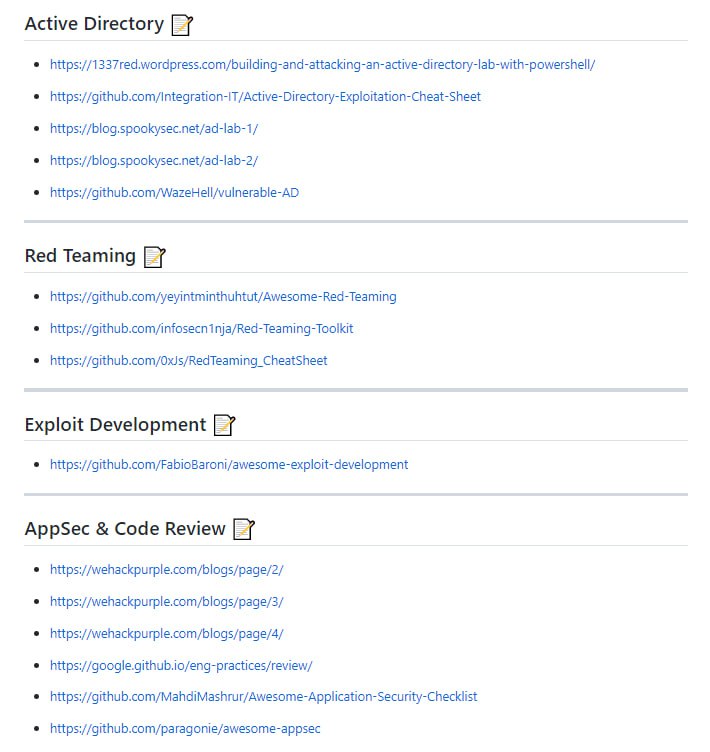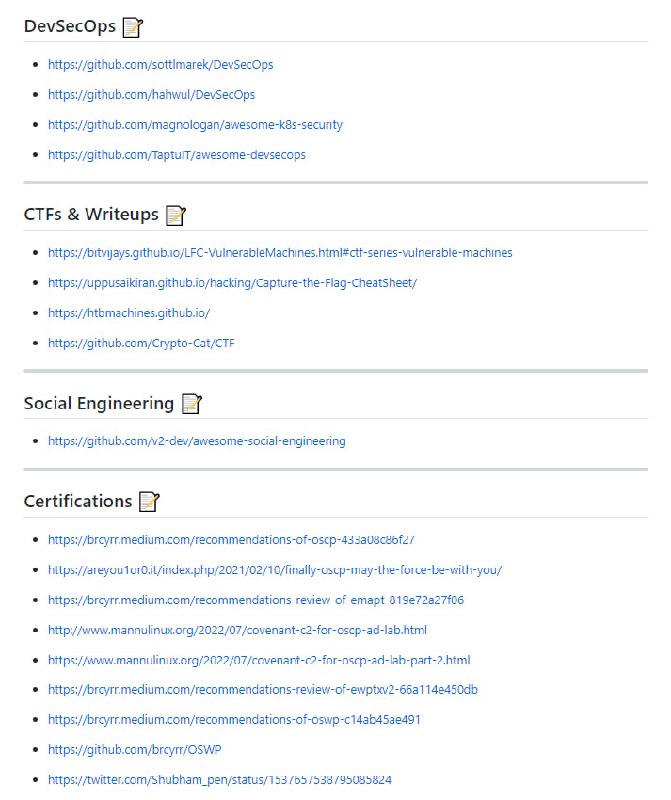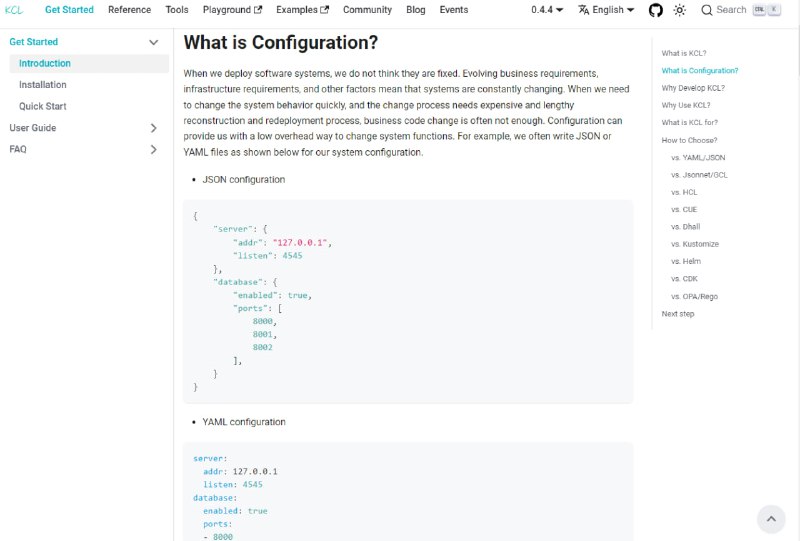
Kusion 配置语言(KCL)是一个开源的基于约束的记录及函数语言。KCL 通过成熟的编程语言技术和实践来改进对大量繁杂配置比如云原生场景的编写,致力于构建围绕配置的更好的模块化、扩展性和稳定性,更简单的逻辑编写,以及更快的自动化集成和良好的生态延展性。
使用场景:
你可以将 KCL 用于:生成静态配置数据如 JSON, YAML 等,或者与已有的数据进行集成;使用 schema 对配置数据进行建模并减少配置数据中的样板文件;为配置数据定义带有规则约束的 schema 并对数据进行自动验证;通过梯度自动化方案无副作用地组织、简化、统一和管理庞大的配置;通过分块编写配置数据可扩展地管理庞大的配置;与 Kusion Stack 一起,用作平台工程语言来交付现代应用程序
特性
简单易用:源于 Python、Golang 等高级语言,采纳函数式编程语言特性,低副作用
设计良好:独立的 Spec 驱动的语法、语义、运行时和系统库设计
快速建模:以 Schema 为中心的配置类型及模块化抽象
功能完备:基于 Config、Schema、Lambda、Rule 的配置及其模型、逻辑和策略编写
可靠稳定:依赖静态类型系统、约束和自定义规则的配置稳定性
强可扩展:通过独立配置块自动合并机制保证配置编写的高可扩展性
易自动化:CRUD APIs,多语言 SDK,语言插件 构成的梯度自动化方案
极致性能:使用 Rust & C,LLVM 实现,支持编译到本地代码和 WASM 的高性能编译时和运行时
API 亲和:原生支持 OpenAPI、 Kubernetes CRD, Kubernetes YAML 等 API 生态规范
开发友好:语言工具 (Format,Lint,Test,Vet,Doc 等)、 IDE 插件 构建良好的研发体验
安全可控:面向领域,不原生提供线程、IO 等系统级功能,低噪音,低安全风险,易维护,易治理
生产可用:广泛应用在蚂蚁集团平台工程及自动化的生产环境实践中
KCL网站 | 项目地址