黑洞资源笔记
-
- Twitter离职员工哪去了?——过去90天里,超过500名员工在与埃隆•马斯克的官司中离开了Twitter,据LinkedIn的数据显示,其中许多员工跳槽到Google和Meta等大型科技公司,马斯克曾表示,如果完成收购Twitter,将裁员75% | 详情
- 运行时超轻量,高效,移植简单的深度学习模型
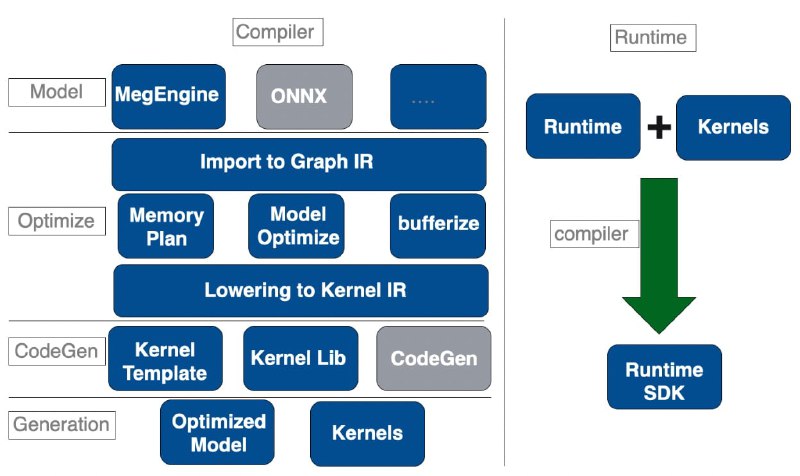
MegCC 是一个面向推理的深度学习模型编译器,具有如下特点:
极其轻量的运行时库 :只编译 mobilenetv1 模型进行推理情况下,strip 符号后,整个运行时二进制大小只有 81KB 。
高性能 :Arm 上的每一个 Kernel 都是经过人工精心调优的,同样的模型,性能比 MegEngine 好 。
方便移植:运行时所有 Code 都是纯 C 代码,可以方便在 Arm,X86,裸板中进行移植。
低内存使用,快启动:模型编译期间会进行内存规划,尽可能的复用内存,并进行静态绑定,减少运行时开销。
MegCC 主要由两部分组成:
编译器:负责将模型进行编译,优化,最终生成新模型和对应的 Kernels
runtime 运行时:运行时需要和生成的 Kernels 结合在一起进行编译,编译完成之后可以加载编译器生成的模型,并计算输出结果
MegCC 模型编译器是基于 MLIR 框架构建起来的,使用 MLIR 的 IR 进行图优化,内存规划以及 Kernel 生成,目前 MegCC 生成的 Kernel 大多数都是 基于人工优化之后写好的模板生成的。MegCC 支持多种场景的模型编译,不仅仅包含静态 shape 编译,而且还支持动态 shape 的编译,多个模型同时编译,以及同一个模型多种 shape 同时编译,另外为了获得极致的最小运行时库,还提供必要的纯 C 形式的 CV 算子生成。
模型编译完成之后,MegCC 会生成两个产物,分别是:
优化之后的新模型: 这个模型里面包含整个计算图的信息,以及每一个 Operator 运行时的内存规划信息,输入输出信息,计算 Kernel 的信息
运行这些模型对应的 Kernel:上面模型运行时候需要的所有高性能 Kernel 的集合。
MegCC runtime 会在运行时会加载生成的模型,并调用生成的高性能 Kernel 进行计算,并输出计算结果,目前测试一个可以高效运行 mobilenetv1 的可执行文件大小仅仅只需要 81KB。
MegCC 现在支持的平台处理器平台有 Arm64/ArmV7/X86/risc-v/单片机, 所有支持的 Operator 列表见:operator lists.
MegCC - 基于TensorFlow PluggableDevice接口的异构、高性能深度学习扩展插件,将英特尔XPU (GPU、 CPU 等)设备带入TensorFlow 开源社区,用于AI工作负载加速
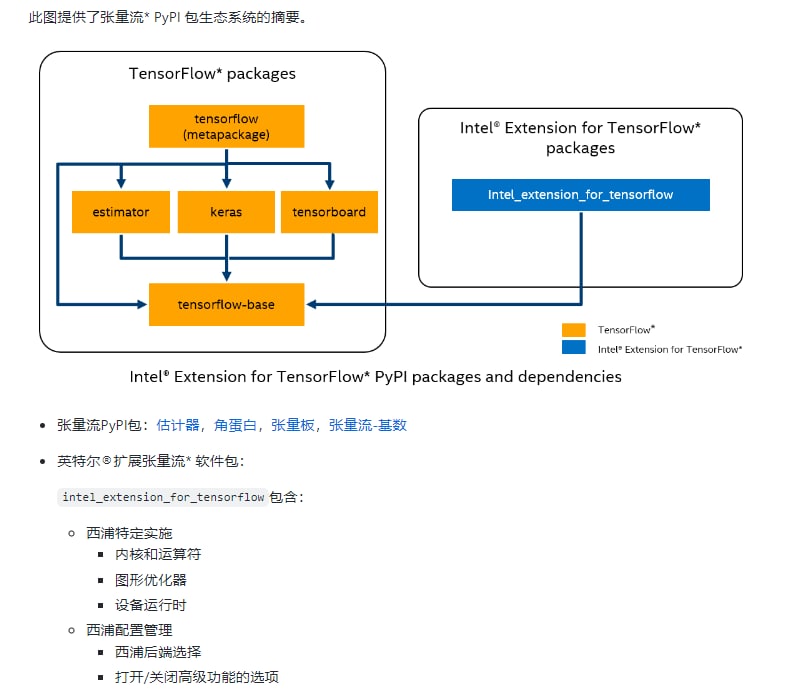
Intel® Extension for TensorFlow* | #插件 - 一种开源工具,可轻松快速构建和部署计算机视觉工作流。你可以将喜欢的框架(如OpenCV,Detectron2,OpenMMLab或YOLO)与来自各个存储库的最佳先进算法混合在一起。
毫不费力,只需选择想要的内容,Ikomia 就会下载,安装需求并在几行代码中运行所有内容。
Ikomia API |Docs | #计算机视觉 #工具 -
-

- 根据刘慈欣原著改编,艺画开天制作的动画版《三体》公开定档预告,12月3日正式播出
- SQLite 官方的 wasm 项目,可以网页调用 SQLite 数据库了 | 详文
- 本书的目的是为大家介绍PyTorch深度学习的基础知识,并以一个实际项目来展示。我们力图介绍深度学习底层的核心思想,并向读者展示PyTorch如何将其实现。

Deep Learning with PyTorch | #机器学习 #电子书 - 这是一个扩展程序,它将跳过 YouTube 视频的赞助片段。赞助商块是一个众包浏览器扩展程序,任何人都可以提交YouTube视频赞助片段的开始和结束时间。一旦一个人提交了此信息,具有此扩展名的其他人将直接跳过赞助细分。
SponsorBlock Server -