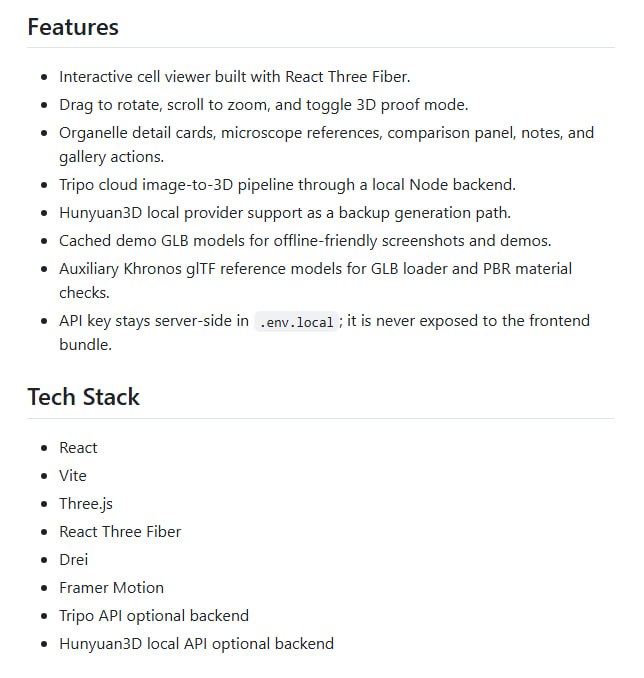
AI 高效工作流:原型实验+倒带压缩,实现试错到认知升级 |
帖子提要:通过 /prototype 进行原型实验,再利用 /rewind 结合 summarize 功能将实验过程压缩为结构化知识,从而在保持上下文精简的同时,实现从“试错”到“认知”的跨越。
很多人用 AI 就像在沙堆上盖房子,一边堆一边塌。
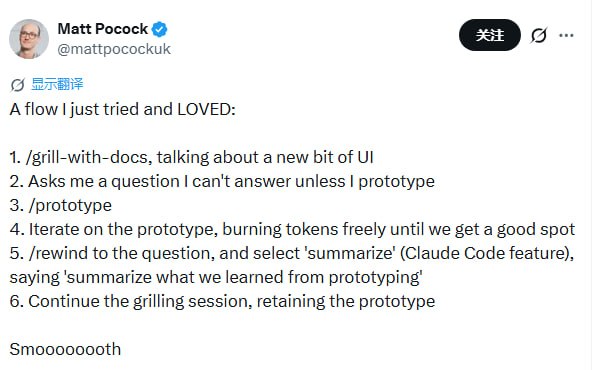
有个很有意思的工作流:先用文档去“拷问”AI,遇到答不上来的问题,直接进入 /prototype 模式,不计成本地消耗 Token 去做一个原型。等原型跑通了,关键动作来了:使用 /rewind 回到问题点,并执行 summarize。
这本质上是在做一种上下文的“垃圾回收”与“知识提取”。
有网友提到,这个组合拳最厉害的地方在于,它把昂贵的 Token 消耗从单纯的“氛围感试错”转化成了可复用的“产品记忆”。如果你只是盲目地在对话框里堆砌指令,你是在浪费算力;但如果你学会了“自由探索→压缩学习成果→带着更优上下文继续”,AI 才真正开始像一个工程协作伙伴。
这让人想起操作系统的内存管理。直接把所有运行日志塞进上下文,迟早会触发 OOM(内存溢出)或者让推理变得极其迟钝。通过 summarize 进行压缩,就像是把频繁访问的热数据提取成索引,把冗长的执行路径变成了一行简洁的函数调用。
有观点认为,这种流程一旦跑通,就可以将其封装成 SKILL.md,让整个团队直接共享这种思维模型,而不是每个人都去重新发明轮子。
不过也有人觉得,这种频繁的“倒带”操作可能会打断心流。这大概取决于你是在做简单的 Prompt,还是在进行深度架构设计。
如果实验本身就是为了寻找答案,那么在看到答案的那一刻,把过程“压缩”掉,只留下结论,或许是目前最高效的交互方式。
下一步该怎么做?或许是把这种经过验证的流程,直接变成 Agent 的内置技能。