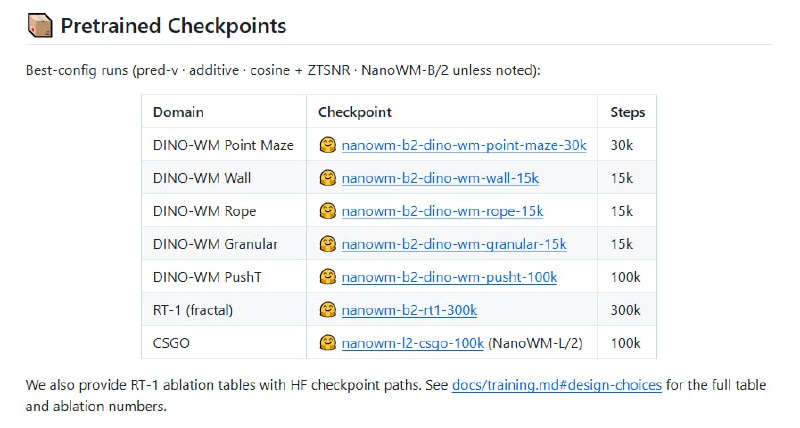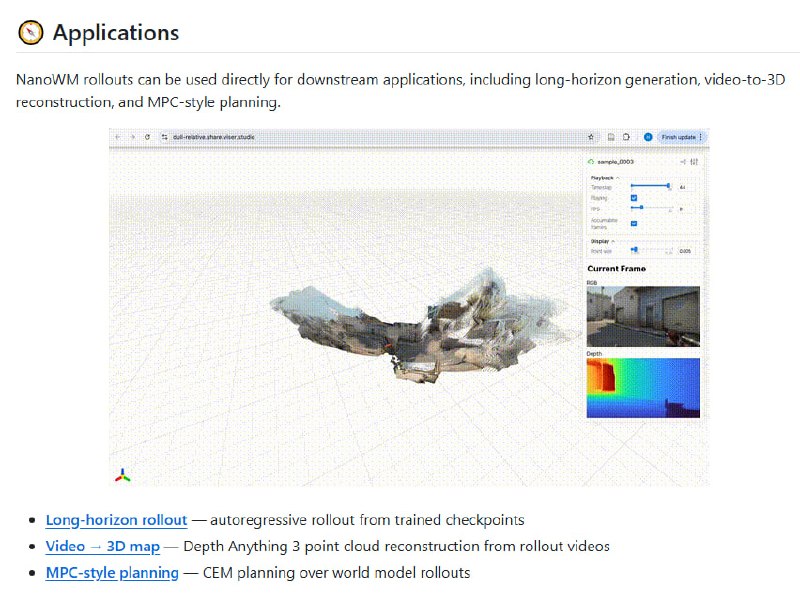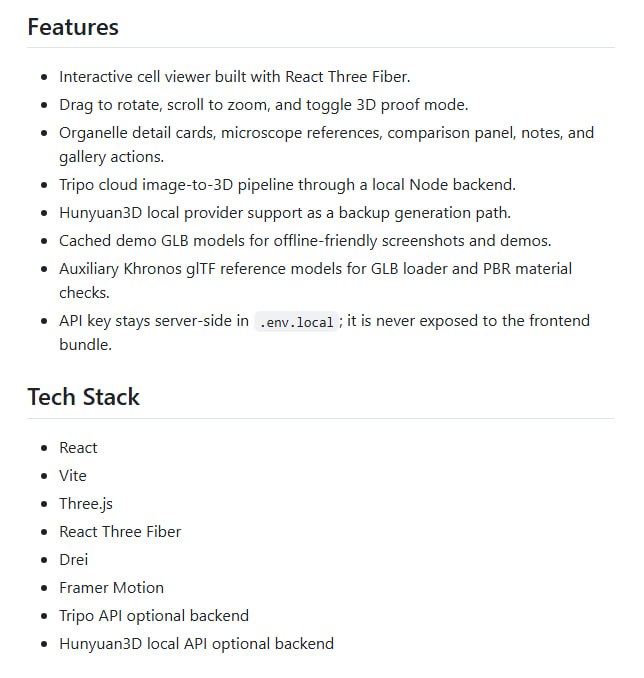
生物细胞3D建模需要切换多个工具,三维渲染软件处理模型展示,AI生成工具创建细胞结构,还要额外的交互面板查看细节,来回切换颇为麻烦。
3DCellForge 把细胞探索所需的功能全部整合到一起,提供了AI驱动的交互式3D细胞生成与探索工作室。
不仅有流畅的WebGL细胞查看器,支持拖拽旋转、缩放和器官细节面板,还能通过图像转3D生成真实细胞模型,支持GLB导出、截图和离线缓存。
主要功能:
- 交互式3D细胞查看器,支持React Three Fiber实时渲染和轨道控制;
- 图像转3D生成,支持Tripo云端、Hunyuan3D本地和浏览器深度图多种模式;
- 器官细节卡片、显微镜视图、比较面板、笔记和图库管理;
- GLB/GLTF模型导入导出、截图功能和本地缓存,支持离线演示;
- 多平台浏览器运行,集成Vite快速开发,无需复杂环境配置;
- 安全API密钥管理,后端Node服务处理生成任务,前端零暴露。
支持 Web 浏览器直接运行,通过 npm install 和 npm run dev 即可本地启动,适合生物研究者和教育工作者使用。
3DCellForge 把细胞探索所需的功能全部整合到一起,提供了AI驱动的交互式3D细胞生成与探索工作室。
不仅有流畅的WebGL细胞查看器,支持拖拽旋转、缩放和器官细节面板,还能通过图像转3D生成真实细胞模型,支持GLB导出、截图和离线缓存。
主要功能:
- 交互式3D细胞查看器,支持React Three Fiber实时渲染和轨道控制;
- 图像转3D生成,支持Tripo云端、Hunyuan3D本地和浏览器深度图多种模式;
- 器官细节卡片、显微镜视图、比较面板、笔记和图库管理;
- GLB/GLTF模型导入导出、截图功能和本地缓存,支持离线演示;
- 多平台浏览器运行,集成Vite快速开发,无需复杂环境配置;
- 安全API密钥管理,后端Node服务处理生成任务,前端零暴露。
支持 Web 浏览器直接运行,通过 npm install 和 npm run dev 即可本地启动,适合生物研究者和教育工作者使用。
Media is too big
VIEW IN TELEGRAM