Apple Silicon 上跑大语言模型,MLX 框架速度总觉得不够快,speculative decoding 方案又非无损,精度和加速两难。
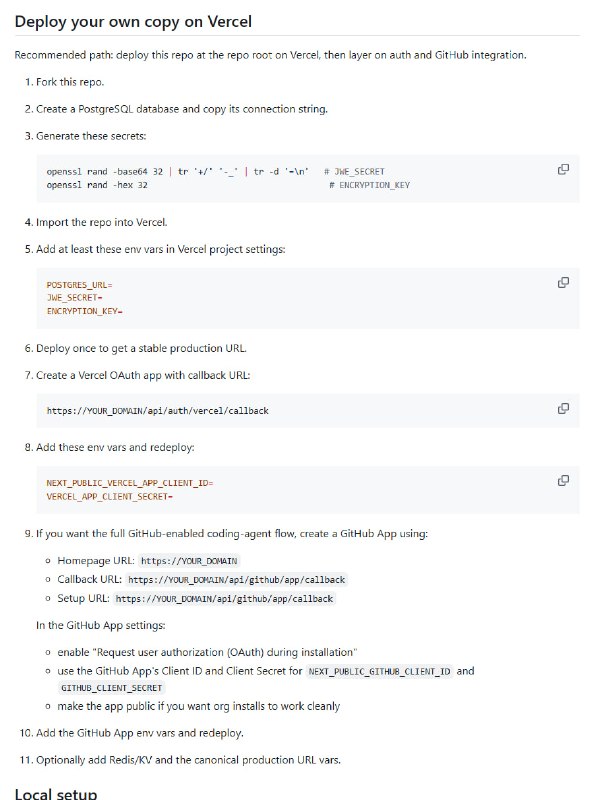
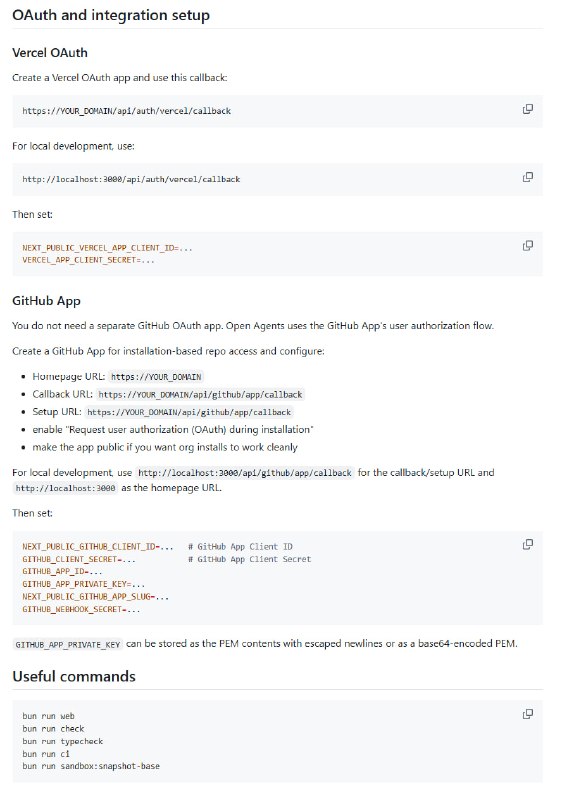
dflash-mlx 带来 DFlash 无损推测解码,为 MLX 优化专属解决方案。
基于 Block Diffusion 论文,一次生成 16 个 token 验证,结合自定义 Metal 内核实现 tape-replay rollback 和长上下文 JIT SDPA,Qwen3.5-9B 最高 4.1x 加速,接受率 89%+。
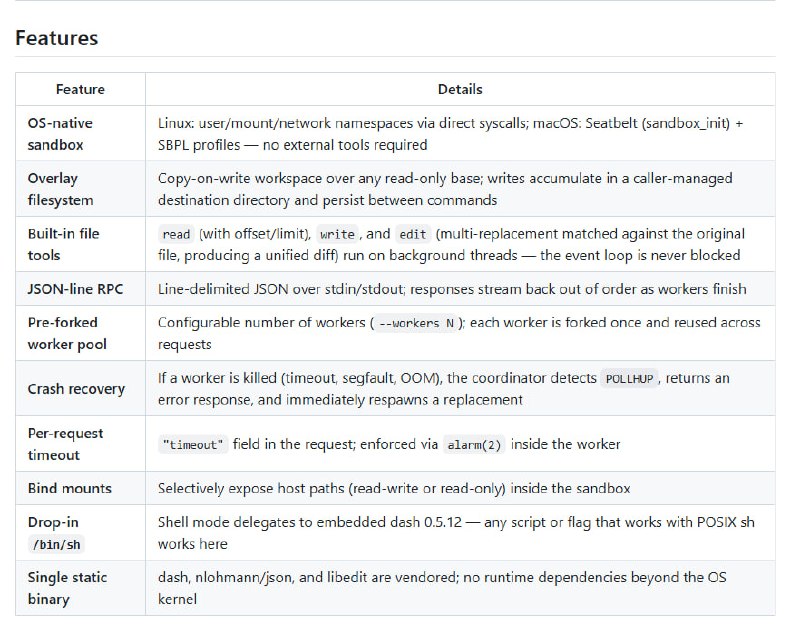
主要功能:
- 无损 DFlash 推测解码,支持 Qwen3.5 系列(4B/9B/27B/35B);
- 自动 draft 模型解析,无需手动指定;
- 高精度 tape-replay rollback,保持长序列一致性;
- 长上下文优化(N>=1024),自定义 Metal 注意力内核;
- 流式输出,支持 CLI/Server 和 OpenAI 兼容客户端;
- 基准测试工具,一键对比 baseline vs DFlash 加速比。
pip install dflash-mlx 即装即用,完美适配 M 系列芯片,开发者/AI 爱好者必备。