越复杂越容易崩:AI创业者用25个项目学到的教训 |
帖子构建过25个以上AI Agent的开发者发现,真正稳定挣钱的项目几乎都是“一个API调用+一个好Prompt”的极简结构。复杂的多Agent系统看起来很厉害,实际上每增加一个Agent就多一个崩溃点,每次Agent之间的交接就是一次信息损耗。
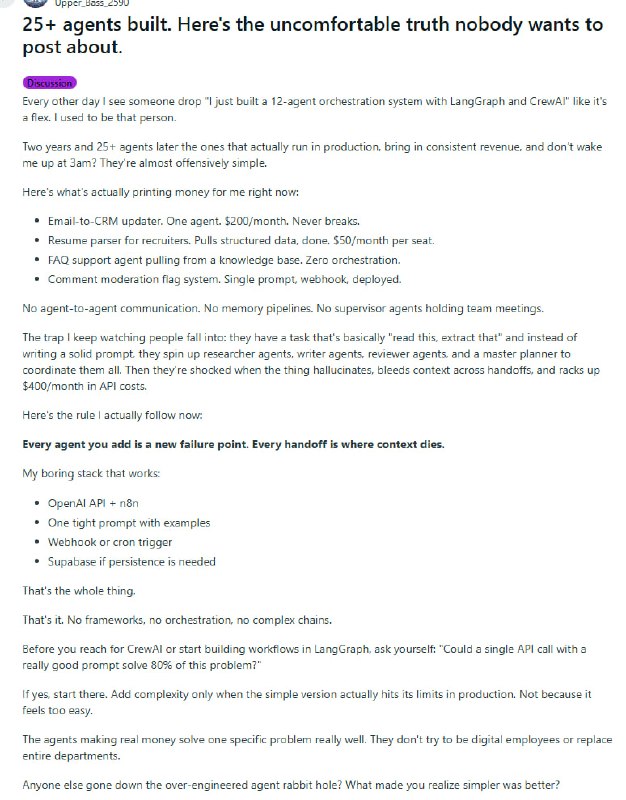
有人在Reddit发帖引发广泛讨论:做了25个以上AI Agent,最后发现最能稳定挣钱的几个,简单到说出来都嫌丢人。
邮件自动写入CRM,一个Agent,每月$200,从不报错。招聘简历解析,每个席位$50,一个Prompt搞定。FAQ支持机器人,零编排。全是这种东西。
没有Agent之间互相开会,没有主管Agent统筹协调,没有什么记忆管道。
他总结了一条核心规则:每增加一个Agent,就多一个故障点;每次交接,就是上下文死亡一次。
这个判断有网友补充得更精确:Agent A知道自己为什么做这个决定,Agent B只拿到输出,不知道原因。到了Agent C,你在玩传话游戏。五个Agent串成链,原始信息里的细节和语境,基本已经被“电话游戏”掉了。
有人做过一个具体实验:三个图像识别Agent并联跑,比单Agent准确率高了2%,但token消耗是三倍。串联跑,每次交接误差叠加,最后准确率反而掉了30%。
也有网友指出,把它叫做“Agent”还是“自动化流水线”,其实是个概念问题。有人认为,没有真正自主决策的系统,只是“带LLM节点的工作流”,算不上Agent。帖子作者的回应相当直接:叫什么不重要,客户付钱是因为问题被解决了,不是因为架构名词好听。
反驳者说,用户完全可以自己用Claude搭同样的东西。作者说,这个逻辑适用于所有服务行业,YouTube上有水管教程,水管工照样存在。他的客户是运营经理、招聘专员、物流协调员,不是技术创始人。技术上可行和商业上可靠运行之间的那段距离,才是服务的价值所在。
有观点认为,Prompt本身是商品,关系和可靠性才是人们真正付钱的东西。有人见过别人用一个他两小时能复刻的工作流收$500/月,原因只是那个人拥有细分市场、完善的新用户引导和用户信任。
有一条留言的锐度让人印象深刻:那些在演示视频里看起来很厉害的复杂多Agent系统,通常在60天内就被替换掉了。而那些无聊的单Agent,挣着钱,没人关注。
“一个Agent,一个任务,可衡量的输出。”
这个判断其实也有边界。真正需要并行处理、子任务彼此独立的场景,多Agent的设计是合理的。但问题在于,大部分人在还没验证简单版本能不能用的时候,就已经开始搭复杂系统了。
最后有人补了一句:多Agent系统最吸引人的地方,恰恰是它会让你感觉自己在做严肃的工程。这通常只是严肃的过度工程。