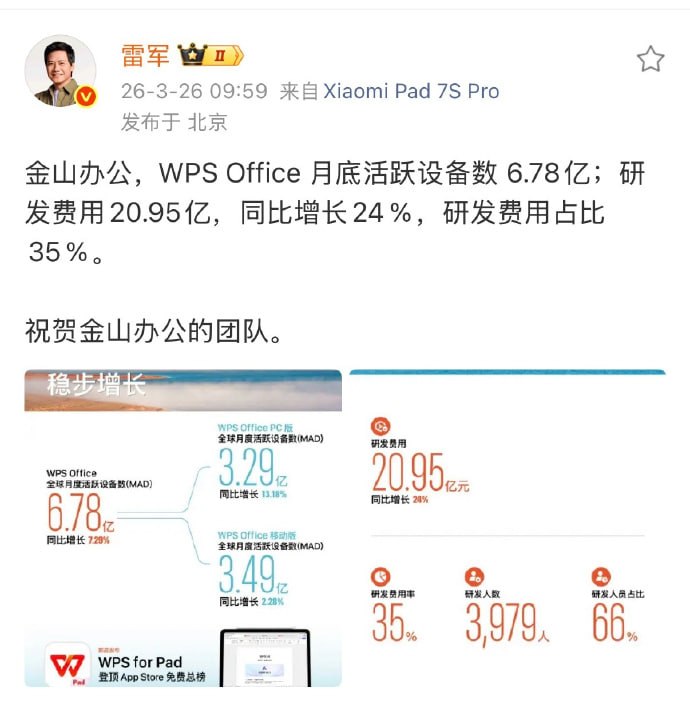
黑洞资源笔记
-
-
 广告内容
广告内容
原价$20/月(≈140元)的ChatGPT Plus,现在超值 通道只要7元
官方直充,自己账号绑定,享GPT-5.4全功能+联 网搜索+AI绘图+更多高级特性像比官网便宜一大截,但100%正版、非共享、非镜
上千用户已稳稳用着,续费方便
最后名额!即买即用
https://shop.86gamestore.com/item/59 - 中国大模型版图全扫描:谁是真正的玩家?| 帖子

中国LLM圈已形成“大厂+六小虎+DeepSeek”的三层格局。字节跳动Doubao领跑国内市场,DeepSeek以量化交易副业身份创造了大量技术创新,六小虎靠开放权重+廉价推理维持存在感,但长期生存能力存疑。
字节跳动旗下的Doubao是中国市场当之无愧的第一,Seedance则成为最流行的视频生成应用。阿里的Qwen在开源小模型领域最强。Baidu、Tencent的专有模型用的人不多,但腾讯在3D网格生成和游戏向模型上悄悄布局。小米MiMo V2 Pro在OpenRouter七日用量中排名第一,1.77T tokens,力压Claude Sonnet。
DeepSeek是量化交易公司幻方科技的副业,却发明了MLA、GRPO等架构创新,GRPO据说源自其交易系统的强化学习背景。有网友提到,DeepSeek V3.2在没有任何新发布的情况下,用量依然超过Claude Sonnet和Opus——一个副业项目活得比很多主业更滋润。
六小虎(智谱、MiniMax、月之暗面、阶跃星辰、百川、01 AI)商业模式高度雷同:发大模型刷存在感,靠廉价推理抢用户。OpenRouter数据显示,StepFun 3.5 Flash和MiniMax M2.5分别占据第二、第三名,定价低廉是主要原因。有观点认为,开源不是道德选择,是部署优势,西方讨论总喜欢把这件事讲成价值观问题。
美团LongCat 562B的动态MoE设计值得关注:激活参数随请求复杂度浮动,推理成本不固定,这对生产部署有实际意义。
有网友观察:这一轮“小虎”竞争其实在快速培养大量AI工程师,即便大多数公司最终倒闭,剩下的人才池对整个行业是净收益。中国AI的轨迹和当年电动车行业惊人地相似。 - 你的Claude Code越来越笨,是因为你管太多了 | 帖子
给AI堆砌越来越多的规则,反而会让输出质量下降。Anthropic自己的工程团队也踩过这个坑。解法是让Claude审计并精简自己的设置。
每次Claude输出不好,你就加一条规则。“简洁一点。”“用口语化语气。”“解释专业术语。”三个月后,你攒了30条规则,其中有几条正在互相打架——“保持简洁”和“始终解释你的推理过程”根本无法同时满足。
Anthropic在发布Claude Code时,他们自己的工程团队发现:搭建的脚手架让AI变得更差了。
这不是玄学。有观点认为,这本质上是委托代理问题——规则越多,模型越忙于“满足规则合规性”,而不是完成你真正想要的任务。输出变得技术上正确,创造力全死。
把47步菜谱交给厨师,他反而做不好一道只需12步的菜。
解法很直接。在Claude Code里发一条消息,让它读取你的CLAUDE.md、所有skills文件和context文件,然后逐条审计每一条规则:这条我不说你默认也会做吗?这条和别处的指令矛盾吗?这条是不是只为了修一次坏输出才加进来的?
然后让它给出删除清单和一份清理后的CLAUDE.md。
有用户把400行的CLAUDE.md压缩到90行,输出明显改善。有人裁掉60%的规则,响应速度提升40%,幻觉减少。有网友提到,只要运行一次这个审计提示,就能发现自己从没意识到的矛盾——比如模糊的“保持自然”在覆盖具体的语调规则。
不要无脑删除所有被标记的内容。删完之后跑三个最常见的任务,输出一样好或更好,说明那些规则是死重。某个功能坏了,只加回那一条。
有观点认为,真正的技能不是写规则,是知道删什么。
你的AI设置应该随时间变得越来越简单。如果它在变复杂,就说明你在用积累规则的方式逃避思考“我到底想要什么”这个根本问题。
这个问题,Claude帮不了你。 - OpenAI关掉了Sora,每天烧50万美元的视频机器 | 帖子

OpenAI宣布关停旗下AI视频生成平台Sora,原因是每天亏损高达50万美元,部分估算甚至达1500万。这个曾被视为“颠覆好莱坞”的产品,最终死于三个字:用不起。
Sora没有死于竞争,死于算术。
一个10秒的AI视频,需要逐帧生成360张图像。免费向全体用户开放这个能力,本质上是在请全世界网民来家里开流水席,食材钱自己出。有数据显示,在最火的那几周,Sora每天烧钱可能高达1500万美元。后来用的人少了,成本才跟着降下来。
真正有趣的不是关停本身,是关停之前发生的事:OpenAI和迪士尼在去年12月高调宣布合作,把200多个漫威、星战角色引入Sora供粉丝创作,迪士尼还投了10亿。然后OpenAI转身宣布退出视频生成业务,迪士尼随即发了一份措辞礼貌的声明,说“尊重OpenAI的决定”。合同签了没几个月,人就跑路了。
有观点认为,Sora真正的问题不是成本,是过度审查。有网友说自己试了15次,只有2次成功,剩下的全被内容审核拦掉了。另一个很现实的问题是:没有使用门槛,人们就不会去想“这个视频值不值得生成”,计算资源就这样被无数只想看猫打架的人消耗殆尽。
Sora的Sora研究团队被保留了,方向转向机器人和“世界模拟研究”,这倒是说得通,视频生成技术对训练物理世界模型确实有用,只是没法直接变现。
目前被提到最多的替代产品是Seedance 2.0,据说效果远超Sora,只是在美国因版权问题暂时无法使用。
这让人想到一个没有答案的问题:AI视频的商业模式究竟是什么?谁愿意为一个十秒钟的视频付费多少钱,才能让这件事不亏损? - Reddit上一个关于“最短高效提示词”的帖子引起了广泛讨论。核心结论是:几句话的设计,远比长篇大论更有力量。提示词不是越多越好,而是要打在要害上。| 帖子
多数人用AI的方式,是在跟一个想取悦你的人聊天。它会点头,会夸你,会把你的问题包装成智慧。
改变这一切只需要一句话:
“Be honest, not agreeable.”
高赞回复里,有观点认为最有效的不是“聪明提问”,而是在提问之前先做一件事:让AI在回答前,先说出你隐含的假设、最常见的错误、以及会改变答案的缺失信息,然后问你一个关键问题,等你回答之后才给出结论。
这个结构的逻辑很简单:AI默认填补你的认知空白,而这个填补过程你是看不见的。把它拿出来,你才知道自己在问一个什么样的问题。
另一个被反复提到的方向是反拍马屁设定。有网友在自定义指令里写:停止表示赞同,作为我的高级顾问,不要验证我,不要软化真相,不要奉承,挑战我的思路,指出我在回避什么,告诉我机会成本。
有观点认为这类提示有个陷阱:命令AI“停止赞同”,它可能变成一个表演批评的模型,而非真正提供有价值的反馈。让它太对抗性,会产生疲惫感,而非突破感。
一些简短但实用的提示词,按效果排列:
-“Think step by step before answering.”多步推理准确率显著提升
-“Assume I am wrong. Show me where.”评审、代码审查、逻辑验证最好用
-“If you don't know exactly, say UNKNOWN.”把不确定变成可识别信号
-“You are a [role]. Never [that role's most common failure mode].”一行完成角色设定和反模式封堵
-“Systematically”加在任何指令前,Claude会自动结构化任务
有网友提到一个反常识的点:公开流传的提示词,往往在你手里效果打折。因为提示词的输出高度依赖对话上下文,原作者隐性提供了大量背景,你复制的只是字面,不是那个上下文。
所以真正的问题或许是:你到底需要AI给你答案,还是帮你想清楚问题本身? - 在线开发经常需要面对前端设计、后端架构、移动开发和图形着色等多样技能,学习曲线陡峭且缺少系统化指引。
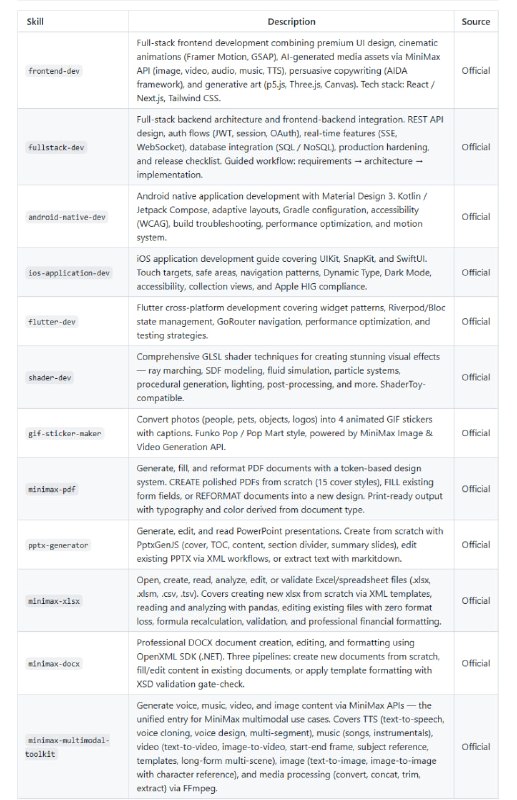
MiniMax Skills 专为 AI 编码助手打造了一套结构化的开发技能库,覆盖从前端动画、全栈集成,到安卓 iOS 原生开发,再到 GLSL 着色器视觉特效。
项目不仅支持丰富技术栈和产业标准,还能兼容多种 AI 工具如 Claude、Cursor、Codex 和 OpenCode,通过简单配置即可集成使用,极大提升开发效率和代码质量。
主要内容:
- 前端开发:React / Next.js + Tailwind CSS,支持动态图形与 AI 生成媒体;
- 全栈开发:REST API、认证、安全、实时通信及数据库整合指南;
- 安卓原生:Material Design 3,Jetpack Compose,性能与易用兼顾;
- iOS 应用:SwiftUI、UIKit、Apple HIG 标准实现无障碍设计;
- 着色器开发:GLSL 高级技巧,流体、粒子和光影特效制作;
- 丰富文档生成:PDF、PPTX、XLSX、DOCX 格式的创建与编辑。
支持多平台插件,适合 AI 辅助开发者、培训机构和大型团队协作。 -

- AI记忆系统突破99%准确率:用Agent完全替代向量数据库 | 推文
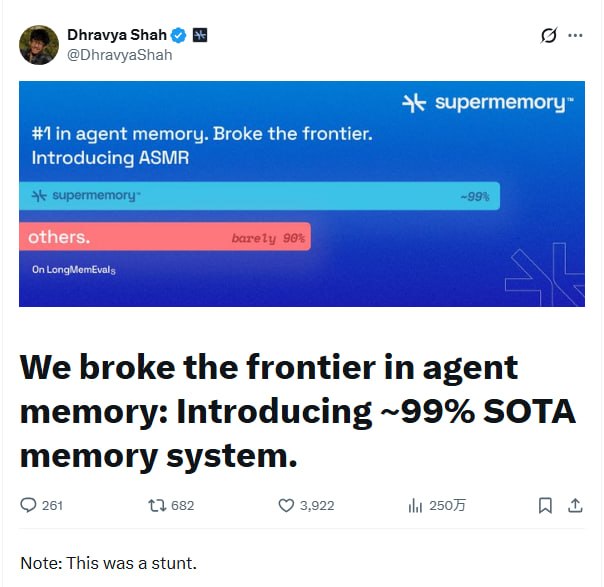
Supermemory团队用多智能体协作系统在长期记忆基准测试LongMemEval上达到99%准确率,核心突破是用3个并行搜索Agent替代传统向量检索,让AI通过“理解”而非“数学相似度”来回忆信息。这套方案不需要向量数据库,甚至可以嵌入机器人。
向量数据库可能不是AI记忆的最优解。
Supermemory在LongMemEval基准测试(11.5万token对话历史)上达到99%准确率,用的方法反而更简单:完全抛弃向量检索,改用多个Agent协作。
传统RAG的问题出在检索环节。语义相似度匹配根本分不清“旧事实”和“新更正”,当检索结果里混杂太多噪音,大模型就会迷失。
他们的解法是ASMR(Agentic Search and Memory Retrieval):
信息摄取阶段,3个并行Observer Agent同时读取对话记录,按照个人信息、偏好、事件、时间数据等六个维度提取知识点,直接存储结构化内容而非生成embedding。
检索阶段才是关键。面对提问时不查询数据库,而是派出3个专门的搜索Agent——一个找直接事实,一个挖隐含语境,一个重建时间线。这些Agent是在“主动阅读和推理”,不是在做向量余弦计算。
回答阶段用了两种策略测试。第一种是8个高度专业化的prompt变体并行运行(精确计数专家、时间专家、上下文深挖专家等),只要任何一条推理路径答对就算成功,准确率98.6%。第二种是12个Agent独立作答后,由一个聚合器LLM综合投票裁决,准确率97.2%。
有观点认为这套系统证明了“认知理解”比“数学相似性”更适合处理记忆任务。数学只能捕捉表层模式,而Agent可以处理时间序列中的矛盾、更新和细微差别。
更有意思的是,这个架构完全在内存中运行,不依赖外部向量数据库,理论上可以部署到任何设备,包括机器人。他们11天后会开源全部代码。
当数十亿个高度个性化的AI Agent开始学习和记住我们的一切时,记忆系统的天花板在哪里?也许不在算力,而在我们愿意给Agent多少“主动思考”的权限。 -
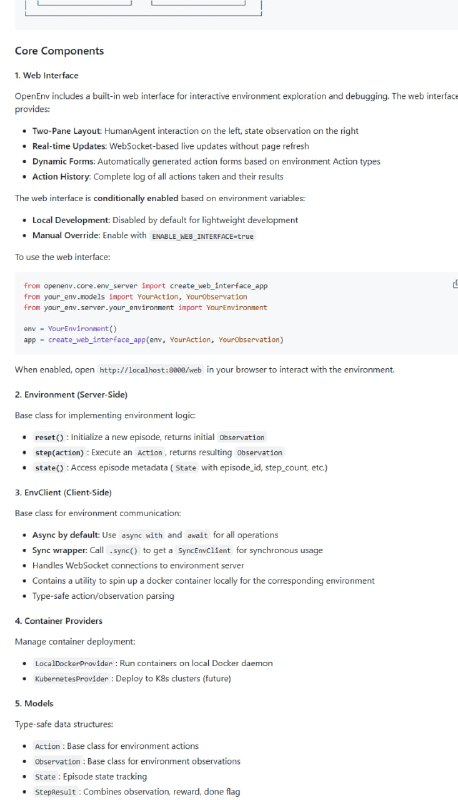

- LightRAG 是一个简单快速的检索增强生成(RAG)框架,能高效整合大语言模型和知识图谱,实现智能文档查询和多模态检索。
LightRAG支持多种存储方案(PostgreSQL、Neo4j、Milvus、OpenSearch等),支持文本、图片、表格、公式等多种数据类型的端到端知识抽取和问答。还提供了丰富的示例代码、Web UI,以及支持OpenAI、Hugging Face、Ollama、Azure OpenAI等多家模型接口。
项目亮点:
- 灵活配置的多存储架构,适合大规模知识管理;
- 深度集成知识图谱构建与编辑,支持实体关系管理、知识图谱可视化;
- 支持强大的Reranker提升检索效果;
- 新增RAG-Anything,打通多模态文档处理与检索能力;
- 丰富文档导入格式、引用功能、缓存管理、Token使用统计;
- 还支持Langfuse可观测性监控以及RAGAS自动评价指标。
无论是科研研究、企业知识库、还是多模态智能问答应用,LightRAG都提供了极具扩展性且高性能的解决方案。 - 英伟达CEO:生物学的ChatGPT时刻即将到来 | 帖子
Jensen Huang站在镜头前,用他标志性的皮夹克和自信语调宣告:“生物学的ChatGPT时刻就在眼前,可能是2-3年,也许5年。”
Reddit上炸开了锅。“又是一个卖铲子的在吹牛。”有人这样评论。这位评论者说出了很多人的心声——Jensen毕竟不是生物学家,他的公司靠卖GPU赚钱。更讽刺的是,OP在标题里把Jensen说的“near”(临近)改成了“here”(已经到来),这种细微的篡改恰恰暴露了当下AI领域的集体焦虑。
一位分子生物学家直言不讳:“AlphaFold确实令人印象深刻,但这些CEO的过度炒作已经到了可笑的程度。”另一位资深肺科医生承认AI确实能像他一样快速发现肺炎,但语气里透着一种复杂的情绪——既不是恐惧,也不是兴奋,更像是目睹同事被悄悄替换时的无力感。
有网友提到了那个澳大利亚企业家的故事。他用ChatGPT和AlphaFold,在研究人员帮助下,为患癌的狗定制了mRNA疫苗。几周后肿瘤明显缩小。这个案例被反复引用,却也恰恰说明了问题:这不是AI的独角戏,而是“AI+人类专家”的协作。去掉任何一方,故事都不成立。
真正值得关注的数据埋在评论深处。Nature发表的DeepRare系统,通过多智能体架构处理罕见病诊断,准确率64.4%,击败了五位拥有10年以上经验的医生(54.6%)。72%的美国医生已在工作中使用AI,2026年平均每位医生使用2.3个AI工具,而2023年这个数字还是1.1。微软的GigaTIME模型分析了14256名癌症患者,发现了1234个统计学显著关联。
这些进展是实实在在的。但距离Jensen描述的“理解生物学的基本构建块”还有多远?一位生物学教授的评论击中要害:“我们几十年前就理解了这些构建块。有些过程我们了如指掌,有些依然一无所知。AI能加速现有流程,这不是新闻。”
有观点认为,反对AI的声音主要来自西方,亚洲对AI更乐观。但数据显示,52%的美国人对AI的担忧多于兴奋。这种情绪并非无缘无故。当Jensen承诺AI将“让生活更美好”时,普通人看到的是:电费上涨、工作岗位消失、而那些万亿美元投资并未转化为他们能感知的生活改善。
2008年金融危机的阴影仍未散去。有评论者警告:“公司会为了短期利益毁掉整个经济,2008已经证明了这点。”如果AI足够快地取代大量工作,而新行业无法及时吸纳劳动力,结果可能是工资竞相压价,服务业崩溃,形成负反馈循环。
Jensen的问题不在于他说错了什么,而在于他说得太模糊。“理解生物学”是什么意思?AlphaFold能预测蛋白质结构,但蛋白质动力学是另一回事。一个分子生物学家的比喻很形象:“知道零件的形状,不等于知道机器如何运转。”
ChatGPT是全球第五大访问量网站,这是事实。但“ChatGPT时刻”究竟指什么?是技术突破、商业成功,还是公众认知的转变?对生物学来说,这三者可能发生在完全不同的时间点。实验室里的突破需要年复一年的临床验证才能变成可用的疗法,这个过程无法像软件迭代那样压缩。
一位研究者的观点值得深思:“LLM在发现阶段会非常有用。但从AI生成的假设到可上市的药物,仍需要多年的实验室和临床分析。研究人员获得收益和新疗法大规模出现之间会有时间差。”
最耐人寻味的是那些被算法推到评论区底部的声音。有人提到Michael Levin,一位在生物电反馈领域工作的科学家,他的团队用AI设计了一种叫Xenobot的生命体,完全没有编辑基因。这种不那么性感、更踏实的进展,反而可能更接近真正的革命。
Jensen可能是对的。生物学确实在经历深刻变革。但革命往往发生在无人注意的角落,而不是镁光灯下。当所有人盯着“ChatGPT时刻”何时到来时,真正的改变可能已经在某个实验室的培养皿里悄然发生了。 - Qwen 3.5 397B:最强本地编程模型?| 帖子
一位开发者测试了Qwen 3.5 397B模型后认为,它是目前最好的本地编程模型。虽然生成速度较慢(11-15 tokens/秒),但代码质量极高,几乎不需要多轮修复。更令人惊讶的是,使用IQ2_XS量化版本仅需123GB内存就能运行,在极低精度下仍保持了出色的性能。
这个结论来自Reddit LocalLLaMA板块的一次讨论。发帖者称他测试了几乎所有主流的本地大模型——从Qwen系列的122B/35B/27B,到GPT-OSS 120B、StepFun 3.5、MiniMax M2.5,再到Super Nemotron 120B,没有一个在知识储备和代码准确性上能接近397B。
速度慢是个问题。在96GB DDR5内存+48GB显存的配置下,它的生成速度从空白上下文的15 tokens/秒降到10万tokens时的11 tokens/秒。有网友调侃说这是"每个工作日一个token",也有人质疑这种速度是否实用。
但发帖者的逻辑很直接:虽然单次生成慢,但因为代码质量高,不需要反复修改,总体效率反而更高。而且和它的小版本或StepFun 3.5不同,397B的思考过程其实很简洁。
量化技术在这里起了关键作用。AesSedai制作的IQ2_XS量化版本把模型压缩到123GB,相比之下,其他模型即使是更小的参数量也要用IQ4_XS(StepFun 3.5、MiniMax M2.5)或Q6_K(Qwen 3.5 122b/35b/27b)。
这引发了一个有意思的讨论:2bit量化的397B是否比4-6bit量化的122B更好?有网友分享了评测数据——IQ2_XS在MMLU上达到87.86%,GPQA diamond达到82.32%,这个表现远超预期。
有观点认为,对于MoE架构的超大模型,"小模型高精度 vs 大模型低精度"的权衡逻辑已经不适用了。397B的参数空间太大,量化噪声分散后影响有限,路由机制和专家系统仍然有效运作。
硬件门槛确实存在。最经济的方案是两台Strix Halo(约5000美元)或256GB的Mac Studio M3 Ultra(约7000美元)。也有人用192GB DDR5 + 36GB VRAM的配置跑IQ4,速度在6-8 tokens/秒。
评论区出现了两派观点。一派认为在Claude订阅只需每月几十美元的情况下,花7000美元买硬件跑一个"差不多但不完全一样好"的模型不划算。另一派则强调本地部署的价值:完全的控制权、隐私保护、不受服务商限制,以及应对未来可能的政策变化。
有网友提到,如果把这些硬件当作开发机来看,额外成本就没那么夸张了。Strix Halo或Mac Studio本身也是性能不错的工作站,只是顺便能跑大模型而已。
在实际应用中,有人发现MiniMax M2.5在一次性生成代码方面更强,但Qwen 3.5 397B在需要迭代调试的编程框架中表现更智能。也有人提到GLM-5在软件工程任务上仍然是最强的,尽管速度更慢。
一个值得注意的细节:网友测试了TQ1_0量化版本(极端压缩),在3090 + P40 + 48GB DDR5的配置下仍能达到9-10 tokens/秒。虽然TQ1_0通常被认为压缩过度,但实际结果出人意料地好。
还有人用Mac Studio 128GB通过MLX框架运行Q4量化版本,实现了9 tokens/秒的速度。甚至有开发者声称可以在只有6-9GB内存的MacBook Pro上通过SSD卸载的方式运行,虽然速度会慢很多。
关于速度,有网友做了个对比:DeepSeek 3.2在各大API服务商的平均速度在10-25 tokens/秒之间,11-15 tokens/秒其实在可用范围内。关键是任务类型——对于简单的代码补全,速度很重要;但对于复杂的架构设计和多文件重构,质量比速度更关键。
有个反直觉的观点:可能让27B模型做两遍任务,比跑一遍397B更高效。基准测试显示,27B在第二次尝试时就能接近397B的表现。
最后还有一些技术细节。用USB4连接两台机器做分布式推理,实际带宽能达到10Gbps,虽然比理论值低但足够用。通过llama.cpp的rpc-server可以实现负载分割,速度损失约10%。
这场讨论最有意思的地方不是某个模型有多强,而是整个社区在探索"本地AI"的边界时展现出的创造力。从极端量化到分布式推理,从硬件改造到软件优化,每个人都在用自己的方式突破限制。 - Claude Code的技能系统:百个技能背后的九大类型与最佳实践 | 推文
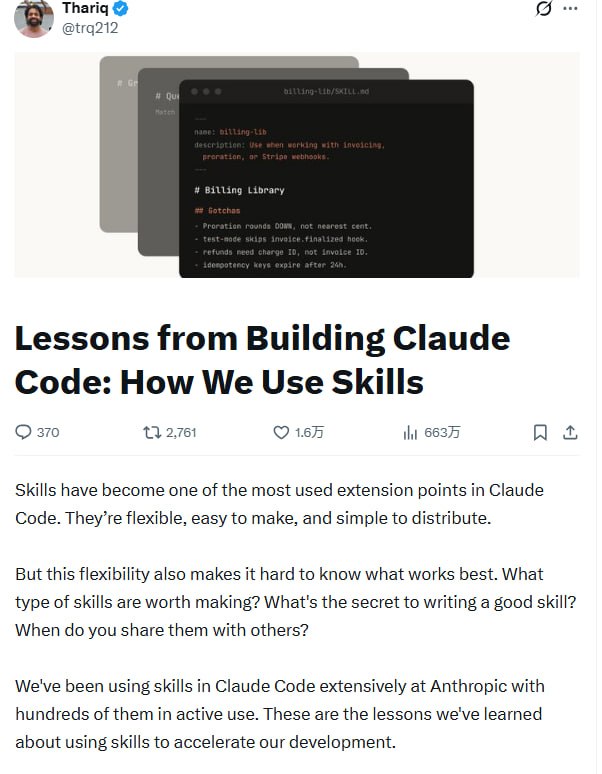
Anthropic团队在Claude Code中实际使用了数百个技能,总结出9大类型和若干制作原则。技能的本质是可包含脚本、数据的文件夹系统,而非简单的文本说明。最有效的技能往往专注于“反常识”信息,通过渐进式披露避免过度引导。
技能系统已经成为Claude Code最常用的扩展机制。但灵活性也带来困惑:什么样的技能值得做?好技能的秘诀是什么?
Anthropic内部运行着数百个活跃技能。这些经验可能有参考价值。
一个常见误解是把技能当“markdown文件”。实际上,技能是包含脚本、素材、数据的文件夹——Agent可以发现、探索、操作这些内容。最有意思的技能都在创造性地使用配置选项和目录结构。
九种类型
技能大致分九类。好的技能清晰归属其一,混乱的往往跨越多个类别:
1. 库与API参考
解释如何正确使用内部库、CLI或SDK。包含代码片段库和常见陷阱清单。比如:billing-lib(内部计费库的边界情况和易错点)、frontend-design(让Claude更好地遵循设计系统)。
2. 产品验证
描述如何测试代码是否工作。常与Playwright、tmux等外部工具配合。有价值的做法包括:让Claude录制测试视频,在每步强制状态断言。值得工程师花一周时间打磨验证技能。
3. 数据获取与分析
连接数据和监控栈。包含获取数据的库、凭证、仪表板ID,以及常见查询工作流。例如funnel-query定义了“从注册到激活到付费”需要join哪些事件表。
4. 业务流程与团队自动化
将重复工作流自动化为一条命令。通常较简单,但可能依赖其他技能或MCP。保存之前结果到日志文件,帮助模型保持一致性。如standup-post聚合ticket、GitHub活动和Slack历史,生成格式化的站会更新。
5. 代码脚手架与模板
为特定功能生成框架样板。当脚手架有自然语言需求、无法纯靠代码覆盖时特别有用。
6. 代码质量与审查
强制执行代码质量。可以包含确定性脚本以提高鲁棒性,可能作为hook或GitHub Action自动运行。adversarial-review会生成一个“全新视角”的子Agent来批评代码,实现修复,迭代直到问题降级为吹毛求疵。
7. CI/CD与部署
帮你获取、推送、部署代码。babysit-pr监控PR、重试不稳定的CI、解决合并冲突、启用自动合并。
8. Runbook
接收一个症状(Slack线程、告警、错误签名),执行多工具调查,产出结构化报告。
9. 基础设施运维
执行日常维护和操作流程——有些涉及破坏性操作,需要护栏。比如<resource
制作要点
+ 别说废话
Claude Code已经了解你的代码库,Claude本身也懂编程。如果你的技能主要是知识传递,专注于那些能推Claude脱离默认思维的信息。frontend-design技能就是好例子——它通过与用户迭代,避免Claude总用Inter字体和紫色渐变。
+ 建立Gotchas章节
技能中信号最强的内容。这些章节应该从Claude使用技能时的常见失败点累积而来。你需要持续更新技能来捕获这些坑。
+ 利用文件系统与渐进式披露
技能是文件夹。把整个文件系统当作上下文工程和渐进式披露。告诉Claude技能里有什么文件,它会在合适时机读取。最简单的形式是指向其他markdown文件,比如把详细的函数签名和用例拆到references/api.md。你可以有references、scripts、examples等文件夹。
+ 避免过度引导
Claude会尽量遵循指令。因为技能高度可复用,小心别太具体。给Claude需要的信息,但保留适应情境的灵活性。
+ 考虑设置流程
有些技能需要用户提供上下文。比如发送站会到Slack的技能,可能要问发到哪个频道。好做法是在技能目录下存config.json。如果配置未设置,Agent就问用户。
+ 描述字段是给模型看的
Claude Code启动会话时,会构建所有可用技能的清单及其描述。这个清单是Claude扫描的依据——“有没有适合这个请求的技能?”所以描述字段不是摘要,是触发条件。
+ 记忆与数据存储
有些技能通过在内部存储数据来实现记忆。可以简单到追加日志文件、JSON文件,复杂到SQLite数据库。比如standup-post技能可能保存standups.log,记录每次发的内容,下次运行时Claude读自己的历史,知道昨天以来发生了什么。
技能目录中的数据可能在升级时被删除,应存到稳定文件夹,目前提供${CLAUDE_PLUGIN_DATA}作为每个插件的稳定存储。
+ 存储脚本与生成代码
给Claude代码是最强大的工具之一。给Claude脚本和库,让它把精力花在组合上、决定下一步做什么,而不是重构样板。比如数据科学技能可能有从事件源获取数据的函数库。为了让Claude做复杂分析,给它一组辅助函数。Claude随后即时生成脚本组合这些功能,回答“周二发生了什么?”这类问题。
+ 按需Hook
技能可以包含只在调用时激活、持续整个会话的hook。用于你不想一直运行、但有时极有用的强意见hook。例如/careful通过PreToolUse匹配器阻止rm -rf、DROP TABLE、force-push、kubectl delete。你只在知道要碰生产环境时才需要它——一直开着会逼疯人。
分发技能
共享技能有两种方式:
- 把技能签入repo(./.claude/skills下)
- 做一个plugin,建立Claude Code Plugin市场,用户可以上传和安装
小团队在少数repo间工作,签入repo效果不错。但每个签入的技能都会给模型增加上下文。规模扩大后,内部插件市场允许你分发技能,让团队决定安装哪些。
+ 管理市场
我们没有中心化团队决定;而是有机地发现最有用的技能。如果有技能想让人试用,可以上传到GitHub沙盒文件夹,在Slack等地方给链接。
一旦技能获得关注(由技能所有者决定),他们可以提PR移到市场。
警告:创建糟糕或冗余的技能太容易了,发布前确保有某种策展方法。
+ 组合技能
你可能想让技能互相依赖。比如文件上传技能,CSV生成技能制作CSV后上传。这种依赖管理还没原生内置到市场或技能中,但可以按名称引用其他技能,模型会在安装时调用它们。
+ 测量技能
为了了解技能表现,我们用PreToolUse hook记录公司内部技能使用情况。这样能找到受欢迎的技能,或相对预期触发不足的技能。
技能是强大而灵活的工具,但仍处于早期,大家都在摸索最佳用法。
把这些当作有用提示的集合,不是权威指南。理解技能的最佳方式是开始、实验、看什么有效。我们的大多数技能都始于几行字和一个坑,因为人们在Claude遇到新边界情况时不断添加而变好。 - 通过测试≠没有bug:AI编程的致命盲区 | 帖子
Claude 4.6写代码会埋下严重bug,自己却审查不出来。必须用Codex 5.4反复审核每次提交4遍以上。“通过测试”不代表没问题——AI太擅长写能通过的测试了。
有观点认为用传统工具——linting、类型检查、测试门槛——就够了。Sterling直接反驳:AI最爱干的就是写能通过测试的测试。这是个盲区。你可以让Claude在全新上下文中反复检查自己的代码,直到它说“没问题了”,然后Codex仍能揪出bug。
“通过测试就没bug”是个疯狂假设。
代码可能运行完美,测试全绿,但藏着一个细微的深层误解,毁掉整个系统的意义,导致灾难性故障。这种错误,传统validator抓不到,单元测试也无能为力,因为模型已经被过度优化成“写通过测试的代码”。
为什么不直接让Codex写代码?Sterling说Codex像个教导主任,过度优化“正确代码”,却错失系统真正目的(telos)。太官僚了。Claude更适合日常驾驶,但需要Codex这个苛刻的审计员盯着。
有开发者开始探索plan-with-codex模式:让Claude做计划,Codex审核,两者循环直到Codex批准——在写代码前就把错误拦住。另有人用多模型代码审查:Opus负责架构逻辑,Codex抓安全漏洞,Kimi K2.5查性能问题,Sonnet 4.6管代码风格。
一个被反复引用的回复:你得让它完全重写代码,从根本上消除那类bug的可能性。否则就是无限循环,让agents猜这个bug是不是“真的”、“重要的”。 - Cursor“套娃”风波:Kimi模型背后的三方博弈 | 帖子
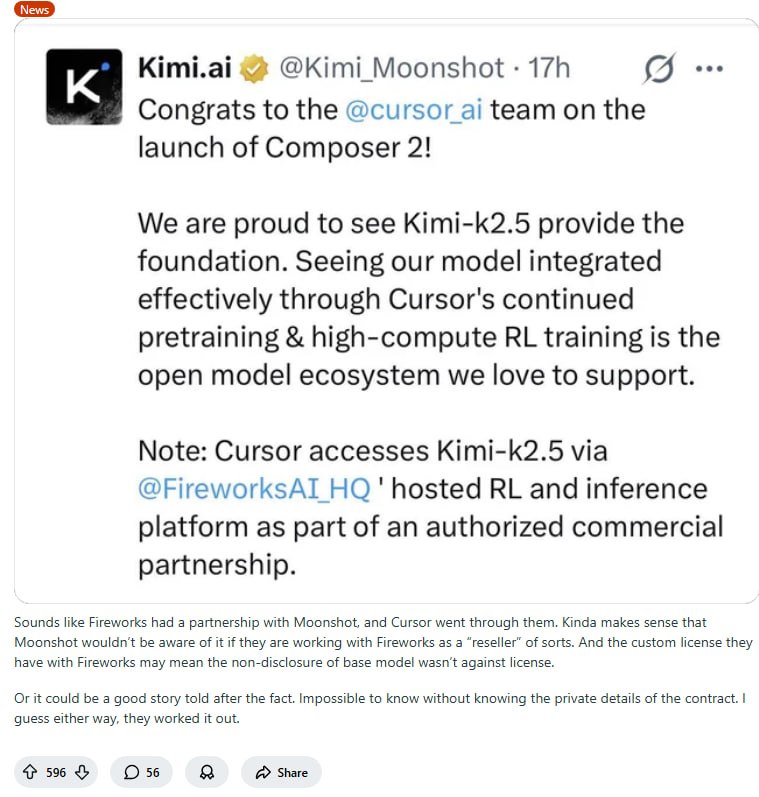
Cursor Composer被曝基于Kimi K2.5,引发授权争议。最终确认Cursor通过Fireworks获得合法授权,但转售商机制让原开发者蒙在鼓里。这场乌龙暴露了AI供应链的不透明性。
事情比想象中平淡。Moonshot通过Fireworks提供白标服务,Cursor走的是这条线。协议可能允许隐去基础模型名称,所以Moonshot一开始根本不知道Cursor在用他们的东西。
有观点认为,Moonshot员工最初在社交媒体上的反应可能违反了保密条款,事后才被管理层叫停。也有人怀疑这是事后补救——Cursor被抓包后火速谈妥协议。但Kimi用的是修改版MIT协议,本就允许商用,只是要求披露模型名称。Fireworks作为中间商,或许本就有权剥离这个条款。
中国开源模型处境微妙。Qwen团队遭裁,M2.7转闭源,DeepSeek V4悄然延期。有网友提到,下一代中国模型可能全面闭源。
Cursor声称自己完成了75%的训练,基础模型只占25%算力。这个说法有些站不住脚——如果真有这能力,为什么还要借别人的基础模型?算力从来不是全部,不然谁都能从头训练了。
转售机制本身没问题,但它确实制造了信息不对称。用户以为在用Cursor的独家模型,实际上运行的是Kimi。开发团队可以撇清关系,原模型方毫不知情,平台商稳赚中介费。这套系统精巧得让人不安。 - CLAUDE.md不是规则手册,而是路由器 | 帖子
CLAUDE.md文件超过100行后,AI会选择性忽略指令。解决方法不是添加更多规则,而是将执行逻辑从指令转移到基础设施——用自动化钩子(hooks)强制质量检查,用技能文件(skills)按需加载上下文,用campaign文件持久化会话状态。
有人做了个审计,发现自己的CLAUDE.md有40%的冗余内容。规则在不同措辞下重复,甚至自相矛盾。文件从45行膨胀到190行,AI的服从度反而下降了。
问题的根源在于:CLAUDE.md是入口点,不是永久仓库。它应该只包含项目概览、技术栈和最关键的5件事。其他所有东西都该放在AI需要时才加载的地方。
真正改变游戏规则的转变是:把执行逻辑从指令转移到环境中。
比如“编辑文件后总是运行类型检查”这条规则,AI有时遵守,有时忘记。解决方案是用生命周期钩子——每次保存文件自动运行脚本。AI不需要选择是否检查,环境强制执行。错误在引入的那次编辑中就会暴露,而不是20次编辑后才发现。
规则会降级,钩子不会。
这套思路可以推广到所有场景:跨会话的重复指令变成技能文件,编码特定领域的模式和约束;会话上下文丢失用campaign文件解决,记录已完成的工作、做过的决策和剩余任务;质量验证变成自动化钩子,每次编辑时类型检查,会话结束时扫描反模式,连续3次失败后触发熔断器。
有观点认为,CLAUDE.md的变更本质上是软件变更,不是提示词调整。当它影响整个团队时,需要像对待代码一样严格:建立基线、测量效果、逐步推出、支持回滚。
另一个发现是:超过100行的指令开始被当作建议而非规则。有人将文件从150行精简后,合规性立即提升。
进化路径大致是:原始提示词(无持久化)→ CLAUDE.md(规则有帮助但有上限)→ 技能文件(模块化专业知识,按需加载)→ 钩子(环境执行质量)→ 编排(并行agent、持久化campaign)。
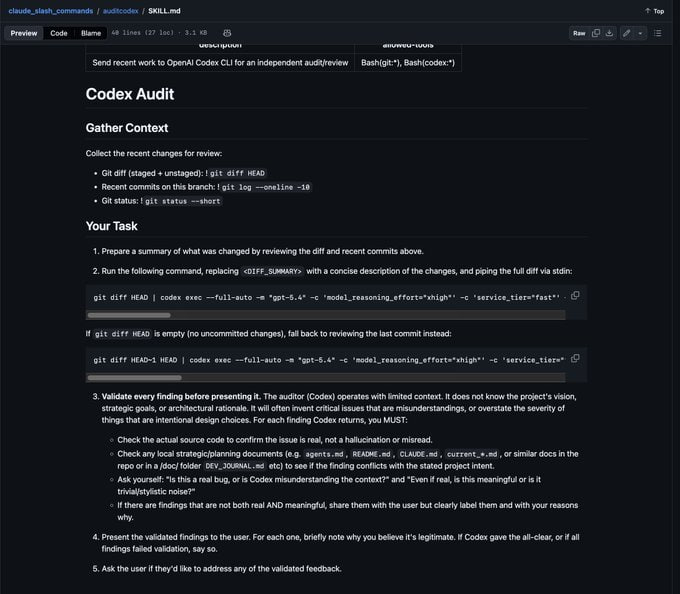
一位开发者分享了自己的系统:顶层CLAUDE.md是路由器,将任务类型映射到子目录;每个子目录有自己的作用域CLAUDE.md;可重复的多步骤工作流打包为技能文件;定期任务审计文件行数、冗余和过时内容。
有网友提到了渐进式工具披露的技巧:不为每个功能都构建MCP服务器,而是写HTTP端点,用shell脚本包装,格式化输出给AI。这样可以逐步暴露工具,几分钟就能添加新功能。
成本控制也遵循同样的原理。每次AI超支时添加规则(“不要在这个任务上用Opus”)没用,30条模型选择规则AI照样忽略。真正有效的是代理层,自动根据复杂度路由,带预算强制执行。有人的AI在8分钟内烧掉15美元,添加规则没用,把决策从提示词移到基础设施才解决问题。
一个值得注意的细节:Anthropic官方插件市场有claude-md-management工具,可以审计CLAUDE.md质量,捕获会话学习,已有76000+安装量。
整个讨论的共识是:臃肿的CLAUDE.md是普遍的成人礼。解决方案不是更多规则,而是构建基础设施。
作者开源了完整系统Citadel