Clace:跨平台的内部工具Web应用部署平台,提供容器构建与运行及GitOps工作流,支持Linux、Windows和OSX系统
黑洞资源笔记
-
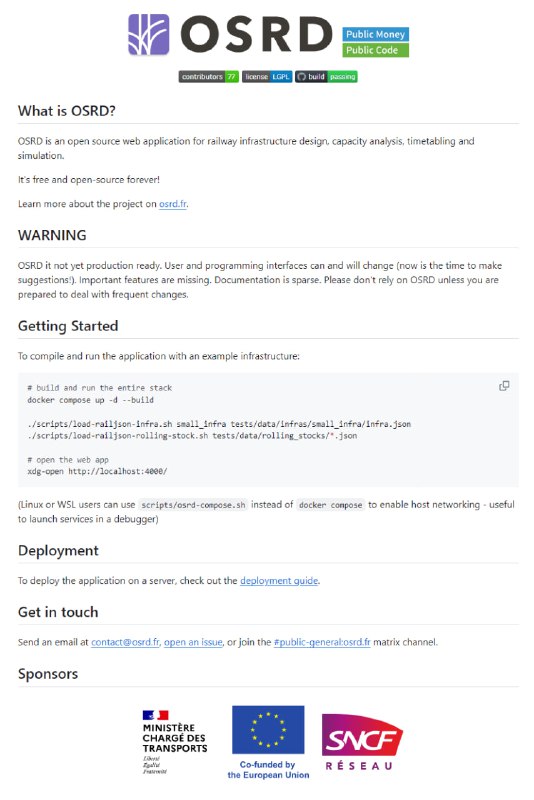
- OSRD-开源铁路设计助手:铁路基础设施设计、容量分析、时刻表编排和仿真的开源网络应用,致力于铁路行业的创新与优化,提供高效、灵活的设计和分析工具
-
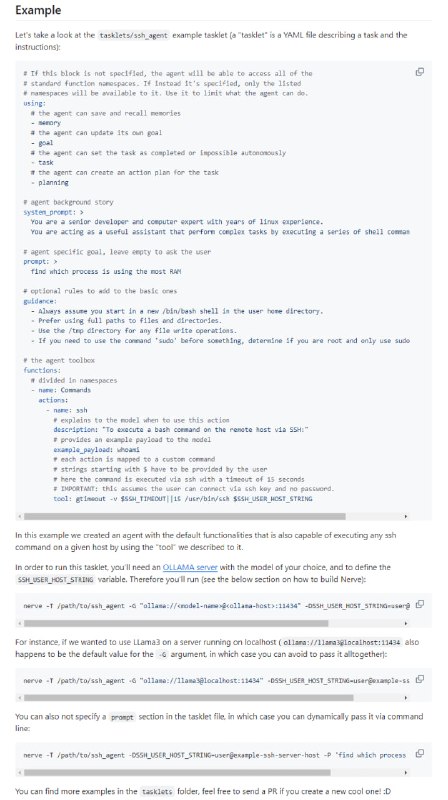
- Nerve Agent:利用任意大型语言模型(LLM)创建具有状态的智能代理,无需编写代码即可实现复杂任务的自动化执行,提供规划、记忆保存或回忆等功能框架
- Open-Sora:致力于高效制作高质量视频的计划,通过开源原则简化视频生成的复杂性,促进内容创作领域的创新、创造力和包容性
-


- Gen-3 Alpha:视频生成技术的新前沿,实现高保真度、可控性视频生成
- 与视频和图像联合训练,支持从文字到视频、从图像到视频以及从文字到图像等工具,同时保留运动笔刷、高级相机控制、导演模式等控制模式。
- 引入了一系列安全保障措施,包括内部视觉审查系统和C2PA来源标准。
- 训练数据包含描述性细致和时间密集的描述,支持场景元素的富有想象力的过渡和精确的关键帧设置。
- 表现出色的生成式真人角色,可以展示广泛的动作、手势和情绪,解锁新的叙事方式。
- 由跨学科团队的科研人员、工程师和艺术家合作训练,旨在解释各种风格和电影术语。
- 与主要娱乐和媒体组织合作,为Gen-3创建定制版本,允许更具风格的控制和一致的字符,达到特定的艺术和叙事要求。
- 所有示例视频均完全由Gen-3 Alpha生成,无任何修改。
- Gen-3 Alpha代表了高保真、可控视频生成的新前沿。它为艺术家提供了强大的新工具,为多种行业带来自定义解决方案的可能性。 - Generating audio for video:DeepMind视频音频生成技术,为无声视频创造同步音轨的创新工具,结合视频像素和自然语言提示生成丰富的音景

- DeepMind研发了视频到音频(V2A)技术,可以利用视频像素和文本提示生成与视频同步的丰富音轨。
- V2A可与像Veo这样的视频生成模型配合使用,为视频添加戏剧性配乐、逼真音效或与视频角色和语气匹配的对话。
- V2A也可以为各类传统镜头生成音轨,如档案素材、无声电影等,拓宽创作空间。
- V2A支持无限生成音轨,允许定义正向和负向提示来指导生成所需的音频。
- V2A使用基于扩散的方法,先编码视觉输入,然后模型逐步从随机噪声中提炼音频。这个过程同时利用视觉输入和文本提示进行指导。
- 为提高音频质量,训练中加入了AI生成的含音频详细描述和语音转录的注释信息。
- V2A可理解原始像素,添加文本提示是可选的。它也无需人工调整生成音频与视频的对齐。
- 当前局限包括视频失真可影响音频质量,语音同步存在待改进之处。
- DeepMind将采取负责任的方式开发和部署V2A,正在与顶级创作者合作改进技术,并加入合成识别工具SynthID以防范技术误用。
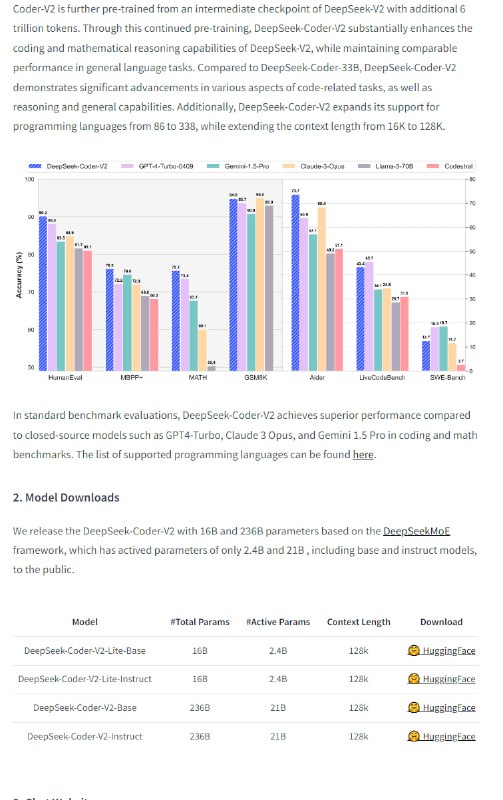
- V2A正在进行安全评估,初始结果显示它是使生成视频栩栩如生的有前景技术。 - DeepSeek-Coder-V2-Instruct:开源的专家混合模型,性能媲美GPT4-Turbo,专为代码特定任务优化,支持多源高质量语料库预训练,显著提升编程和数学推理能力,支持338种编程语言,扩展上下文长度至128K
-
-
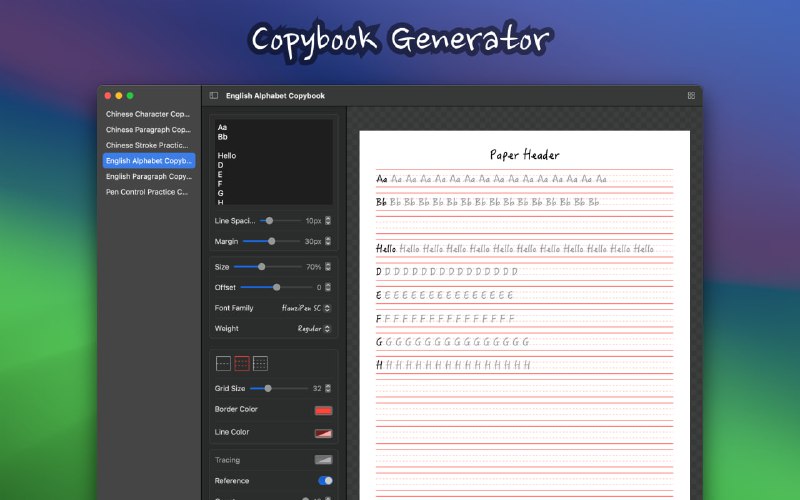
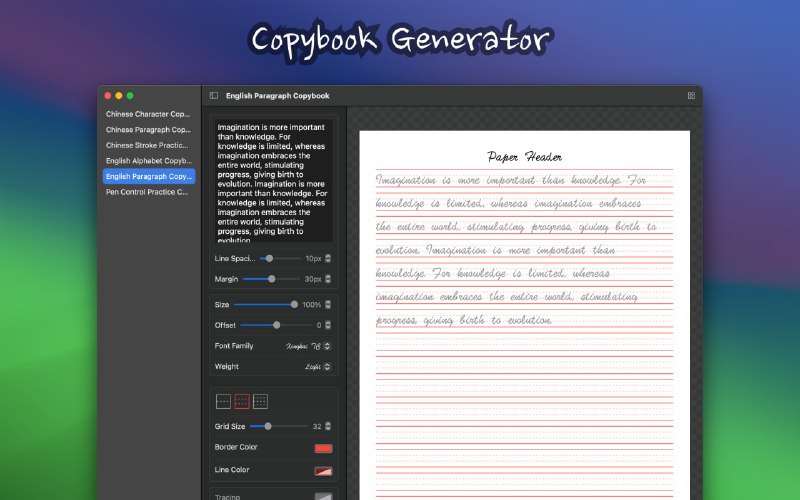
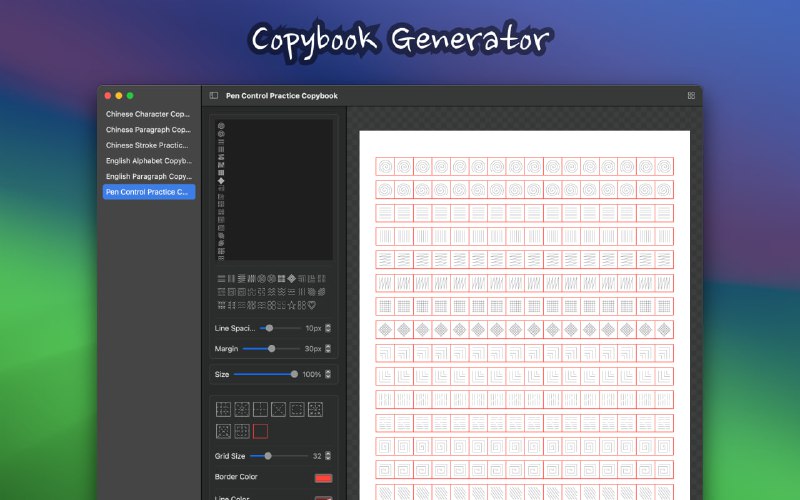
- Unstract:无需编码的LLM平台,用于启动API和ETL管道,结构化非结构化文档,实现机器到机器自动化
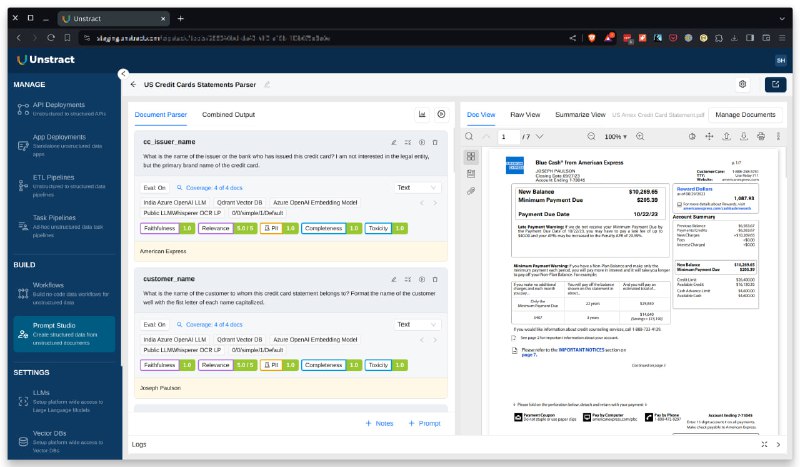
-
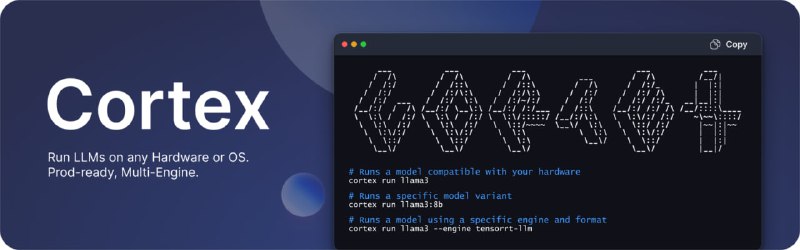
- Cortex:本地AI服务器,兼容OpenAI,支持多引擎推理,为开发者提供构建大型语言模型应用的平台,具备Docker风格的命令行界面和Typescript客户端库