黑洞资源笔记
-
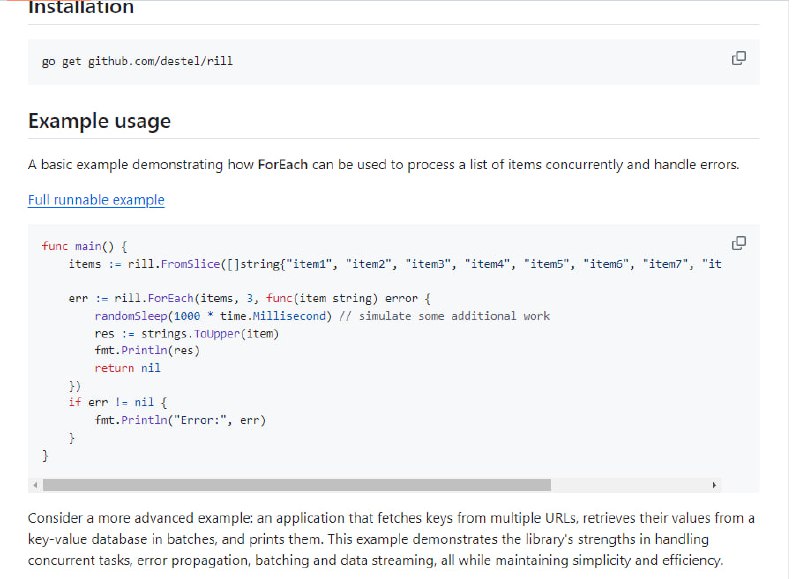
- Rill:Go语言的并发流处理工具包,简化并发编程中的样板代码,提供类型安全、批处理和错误处理功能
主要特征
轻量级:快速且模块化,可以轻松集成到现有项目中
易于使用:管理 goroutine、等待组和错误处理的复杂性被抽象出来
并发:控制所有操作的并发级别
批处理:提供一种简单的方法来批量组织和处理数据
错误处理:提供一种结构化的方法来处理并发应用程序中的错误
流式传输:以最小的内存占用处理实时数据流或大型数据集
顺序保存:提供保存数据原始顺序的功能,同时仍允许并发处理
高效利用资源:goroutine 和分配的数量与数据大小无关
通用:所有操作都是类型安全的,可以与任何数据类型一起使用
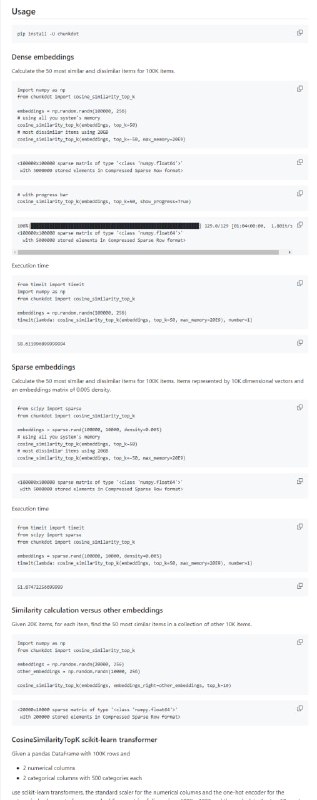
函数式编程:基于函数式编程概念,使 map、filter、flatMap 等操作可用于基于通道的工作流程 - ChunkDot - 矩阵计算库:多线程矩阵乘法和余弦相似度计算工具,适用于密集和稀疏矩阵,通过分块项目矩阵表示(嵌入)和使用Numba加速计算,快速计算大量项目中最相似的K个项目
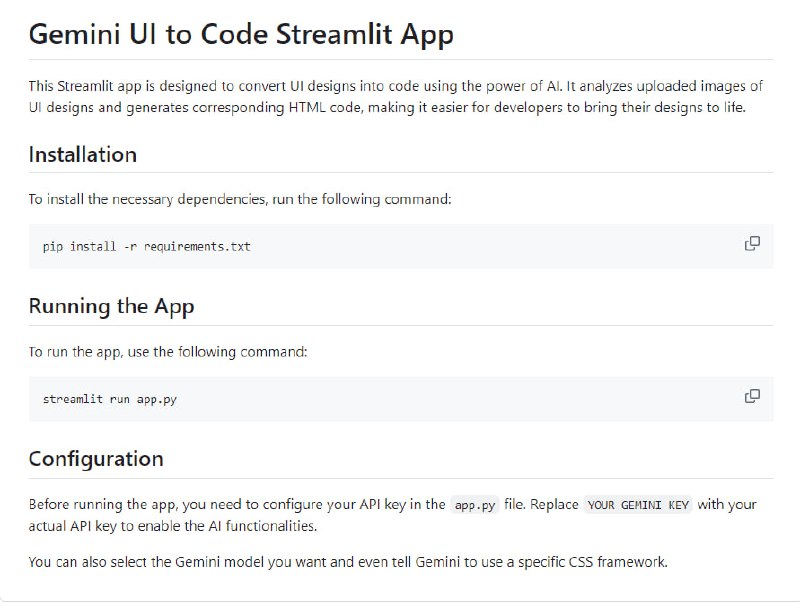
- Gemini UI to Code Streamlit App:利用AI技术将UI设计图转换为代码,帮助开发者轻松实现设计到代码的转换过程,提高开发效率
-
- 通过整合多开源数据集并进行深度处理,构建了迄今最大的开源NLP预训练语料Zyda,质量接近商业语料,为开源语言模型研究奠定数据基础。

Zyda: A 1.3T Dataset for Open Language Modeling -
-
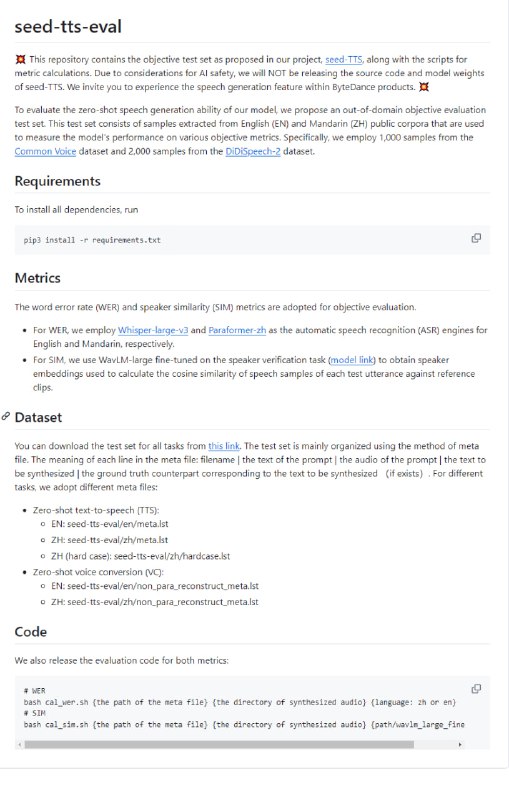
- 字节跳动语音合成seed-tts评估工具:用于评估零样本语音生成模型的跨域客观测试集,通过英语和普通话公共语料库的样本来衡量模型性能,包含英语和普通话的公共语料库样本,采用词错误率和说话人相似度作为客观评价指标
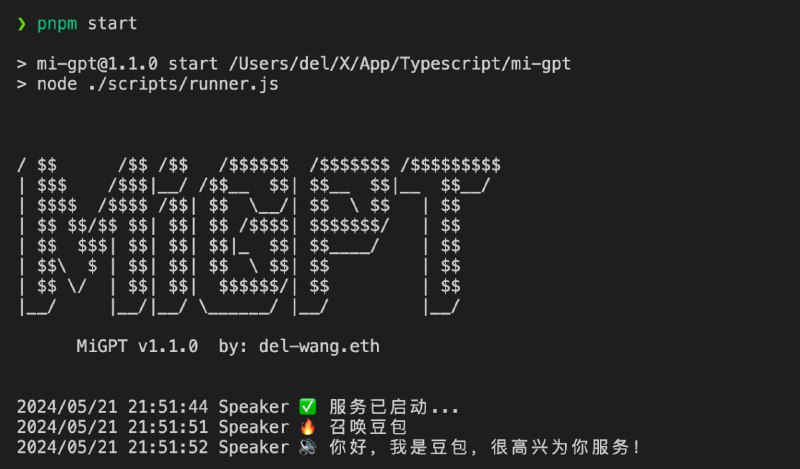
seed-tts-eval | #工具 - MiGPT:将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手
- Haystack Cookbook:使用Haystack进行自然语言处理的示例集合,提供如何结合不同的模型提供者、向量数据库、检索技术等的指导,大多数示例展示特定小型演示

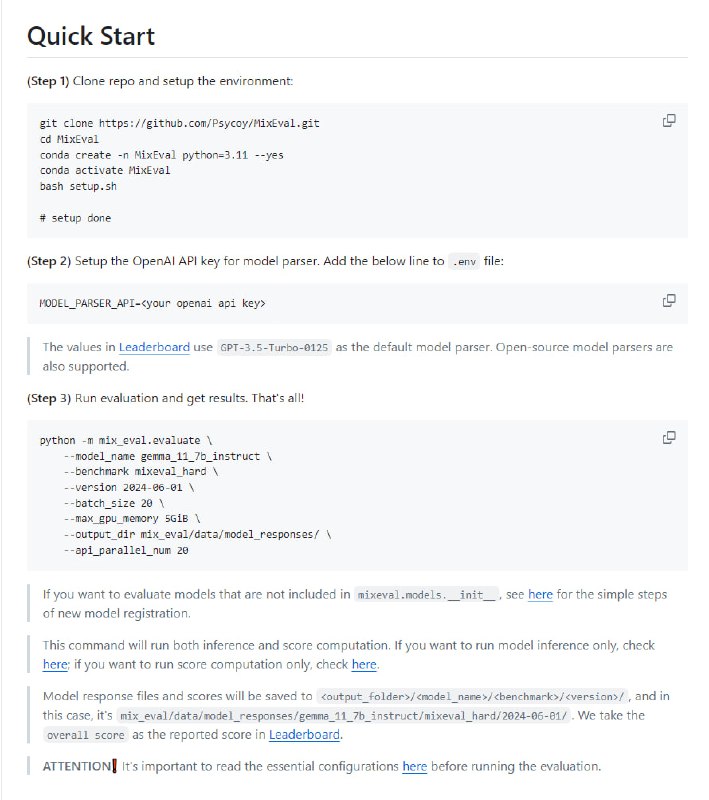
- MixEval:大型语言模型评估套件,提供动态数据和实时更新的基准测试,旨在高效、准确地评估语言模型的性能,同时降低成本和时间消耗
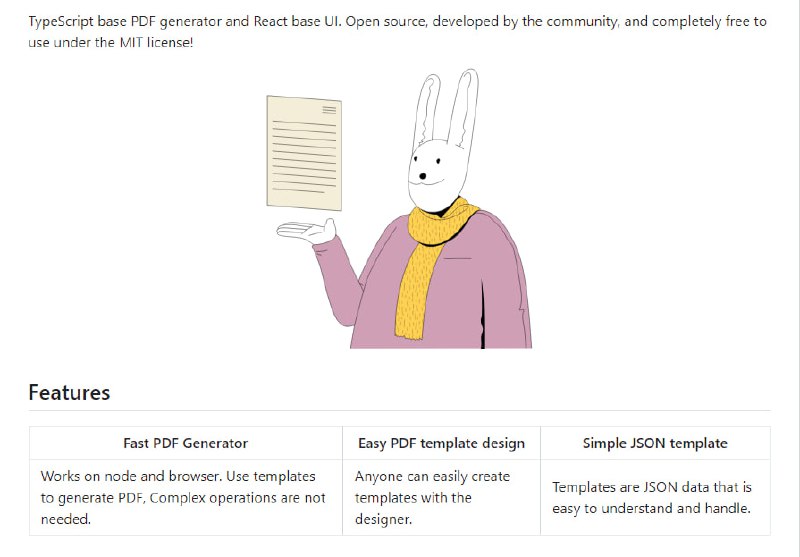
- PDFme:基于TypeScript的PDF生成库,使用React构建,支持在浏览器和Node.js环境中工作
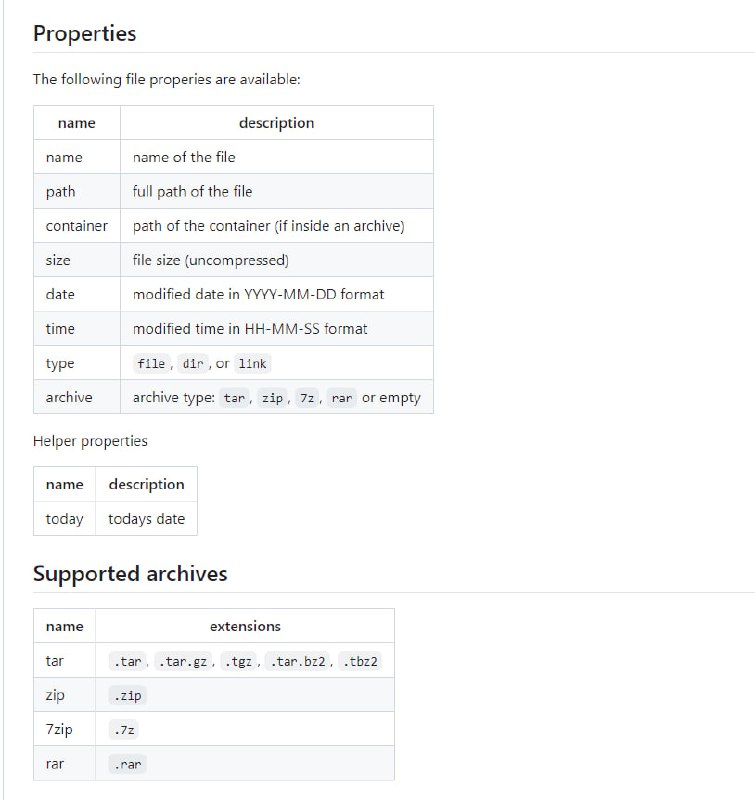
-
-
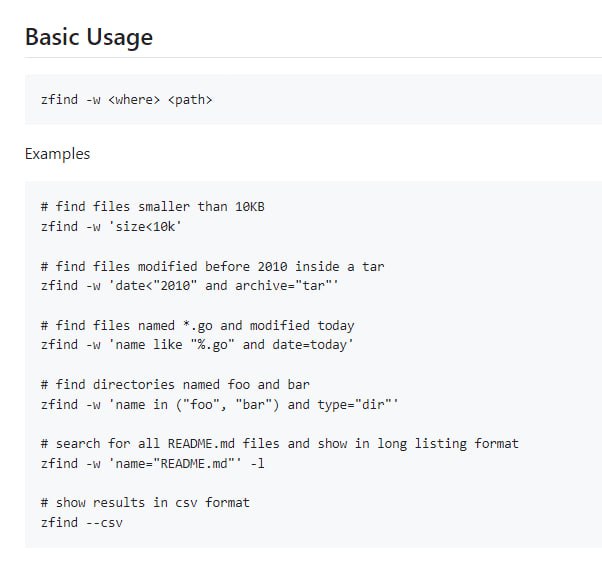
- 新课更新:月神src,rust训练营
- 大规模结构化网络文本提取工具,可大规模提取优质文本数据,由Hugging Face Space提供,支持自动化内容筛选和再利用。

FineWeb是一个大规模结构化网络文本的提取和过滤系统,利用Hugging Face的机器学习模型从网页中提取和过滤出高质量的文本内容,可以快速处理大量网页,并根据可配置的过滤规则提取出结构化的数据。用户可以指定主题、语言等参数,FineWeb会返回与这些规则匹配的文本内容。
FineWeb利用DistilBERT模型进行主题分类,利用ToxicBERT模型过滤掉低质量和有毒内容,用户可以微调这些模型来优化提取文本的质量。
FineWeb使得大规模高质量网络文本的获取成为可能,为自然语言处理任务提供了极为宝贵的数据来源,未来工作将提升模型性能,扩充支持语言,并考虑将其作为API服务对外开放。
FineWeb | #工具 - Milvus Lite:开源向量数据库Milvus的轻量版本,为AI应用提供向量嵌入和相似性搜索功能,可轻松集成到Python应用中

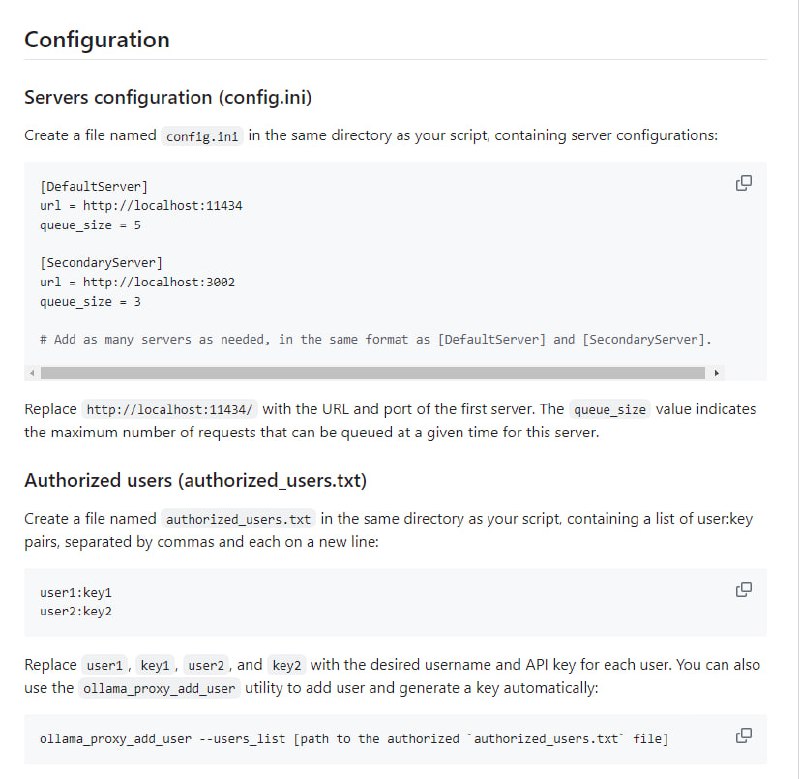
- Ollama Proxy Server:为多个ollama实例设计的轻量反向代理服务器,支持负载均衡和速率限制,具备密钥安全功能