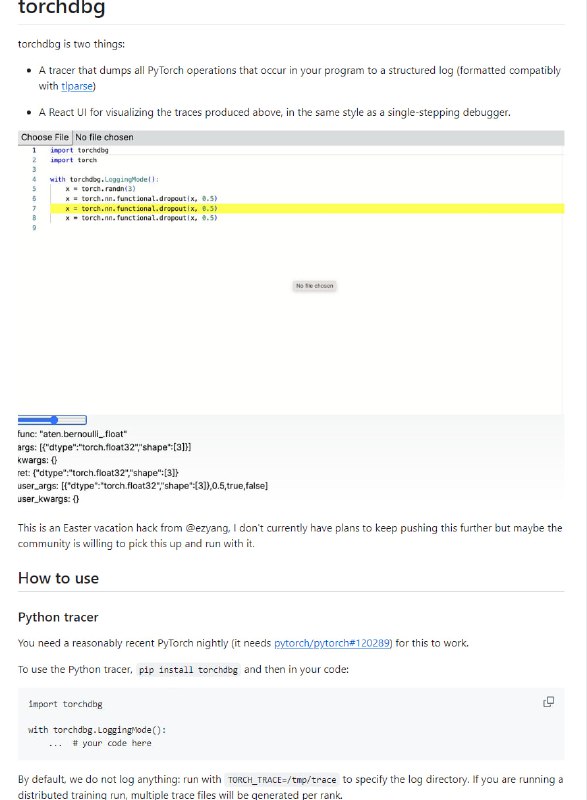
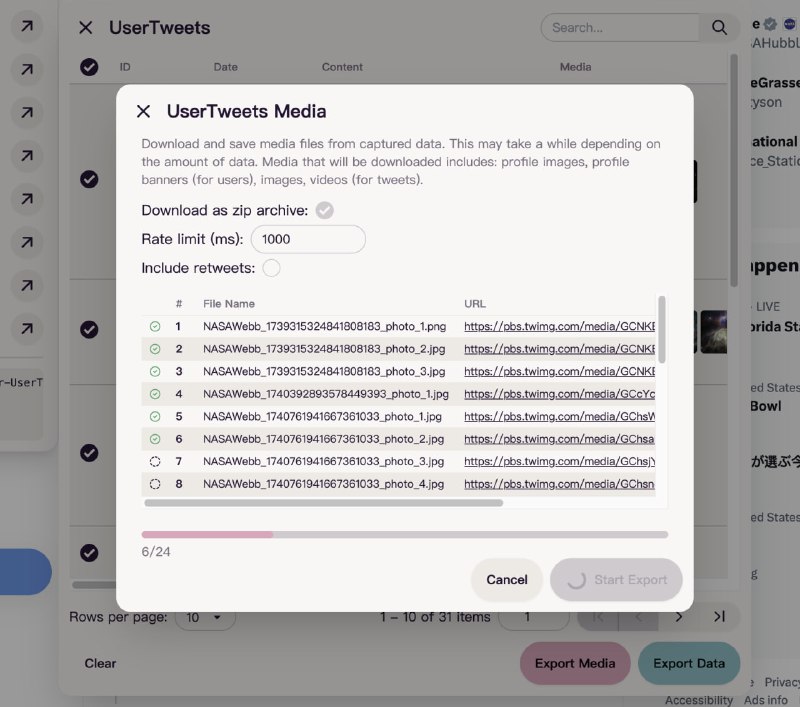
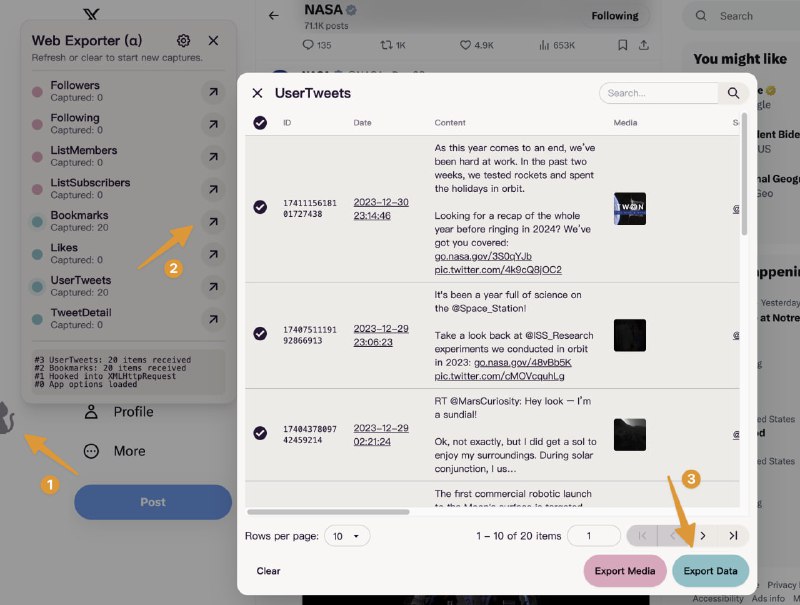
Cohere推出Command R+模型,一个为应对企业级工作负载而构建的最强大、最具可扩展性的大型语言模型(LLM)。
- Command R+首先在Microsoft Azure上推出,旨在加速企业AI的采用。它加入了Cohere的R系列LLM,专注于在高效率和强准确性之间取得平衡,使企业能从概念验证走向生产。
- Command R+具有128k token的上下文窗口,旨在提供同类最佳的性能,包括:
- 先进的检索增强生成(RAG)和引用,以减少幻觉
- 支持10种关键语言的多语言覆盖,以支持全球业务运营
- 工具使用,以实现复杂业务流程的自动化
- Command R+在各方面都优于Command R,在类似模型的基准测试中表现出色。
- 开发人员和企业可以从今天开始在Azure上访问Cohere的最新模型,很快也将在Oracle云基础设施(OCI)以及未来几周内的其他云平台上提供。Command R+也将立即在Cohere的托管API上提供。
- Atomicwork等企业客户可以利用Command R+来改善数字工作场所体验,加速企业生产力。
思考:
- Cohere推出Command R+,进一步丰富了其企业级LLM产品线,展现了其在企业AI市场的雄心和实力。与微软Azure的合作有望加速其企业客户的拓展。
- Command R+在Command R的基础上进行了全面升级,128k token的上下文窗口、多语言支持、工具使用等特性使其能够胜任更加复杂多样的企业应用场景。这表明Cohere对企业需求有着深刻洞察。
- RAG和引用功能有助于提高模型输出的可靠性,减少幻觉,这对于企业级应用至关重要。可以看出Cohere在兼顾性能的同时,也非常重视模型的可控性。
- 与微软、甲骨文等云计算巨头合作,使Command R+能够在多个主流云平台上快速部署,降低了企业的采用门槛。这种开放的生态策略有利于加速其市场渗透。
- Atomicwork等企业客户的支持表明Command R+具有显著的商业价值。将LLM与企业数字化转型相结合,有望催生更多创新性的应用。
- Command R+的推出标志着Cohere在企业级AI市场的发力,其强大的性能和完善的生态有望帮助其在竞争中占据优势地位。不过,企业AI的落地仍面临数据安全、伦理合规等诸多挑战,Cohere还需要在这些方面持续投入。