黑洞资源笔记
-
- RAG Arena:基于 Next.js 和 LangChain 的开源聊天机器人项目,提供了一种接受多个响应的查询体验。

用户对这些响应进行投票,然后将其清晰地显示所使用的检索器,通过数据 RAG 方法来区分聊天机器人。该项目利用 Supabase 进行数据库操作,并具有显示数据库数据的实时排行榜。 - 玲珑安全第一期SRC培训班 | 团购价 195

-
-
- Al Comic Factory:漫画工厂 | github | 线上体验
自动生成有情感、有故事性的漫画内容。它使用大语言模型和如SDXL来自动创建漫画面板。
你只需提供一个简单的文本提示,AI Comic Factory就能根据这个提示生成包含人物对话和场景描述的漫画。支持批量生成不同语言的漫画。
主要功能:
1. 生成漫画面板:利用大型语言模型(LLM)和SDXL技术,根据用户提供的提示自动生成漫画面板,创作出有情感、有故事性的漫画内容。
2. 支持多种配置:项目可以根据用户的技术偏好或需求,选择不同的语言模型引擎(如OpenAI、Hugging Face等)和渲染引擎(如Replicate、VideoChain等),提供高度的自定义能力。
3. 用户交互:用户通过提供创作提示(如漫画的主题、人物对话等)来启动生成过程。项目的前端界面通常负责收集用户输入,并显示生成的漫画结果。
4. 支持多语言内容创建:项目能够生成不同语言的漫画,使得内容创作不受语言限制,更容易触及全球受众。
5. 批量生成漫画变体:通过灵活的配置和技术集成,AI Comic Factory能够快速生成多个漫画变体,为用户提供丰富的选择和测试不同创意的可能性。 - 使用 Google Search API 优雅地搜索互联网 | blog

- AI21发布世界首个Mamba的生产级模型:Jamba

开创性的SSM - Transformer架构
🧠 52B 参数,12B 在生成时处于活动状态
👨🏫 16 位专家,生成过程中仅2个专家处于活跃状态
🆕 结合了Joint Attention和Mamba技术
⚡️ 支持 256K 上下文长度
💻 单个 A100 80GB 最多可容纳 140K 上下文
🚀 与 Mixtral 8x7B 相比,长上下文的吞吐量提高了 3 倍
Jamba结合了Mamba结构化状态空间(SSM)技术和传统的Transformer架构的元素,弥补了纯SSM模型固有的局限。
背景知识
Jamba代表了在模型设计上的一大创新。这里的"Mamba"指的是一种结构化状态空间模型(Structured State Space Model, SSM),这是一种用于捕捉和处理数据随时间变化的模型,特别适合处理序列数据,如文本或时间序列数据。SSM模型的一个关键优势是其能够高效地处理长序列数据,但它在处理复杂模式和依赖时可能不如其他模型强大。
而"Transformer"架构是近年来人工智能领域最为成功的模型之一,特别是在自然语言处理(NLP)任务中。它能够非常有效地处理和理解语言数据,捕捉长距离的依赖关系,但处理长序列数据时会遇到计算效率和内存消耗的问题。
Jamba模型将Mamba的SSM技术和Transformer架构的元素结合起来,旨在发挥两者的优势,同时克服它们各自的局限。通过这种结合,Jamba不仅能够高效处理长序列数据(这是Mamba的强项),还能保持对复杂语言模式和依赖关系的高度理解(这是Transformer的优势)。这意味着Jamba模型在处理需要理解大量文本和复杂依赖关系的任务时,既能保持高效率,又不会牺牲性能或精度。
官网 | 详情 | 模型 -
- OpenAI公布其语音生成模型:Voice Engine
根据文本输入和一个15秒的音频样本,就能生成接近原始说话者声音的自然听起来的语音。
Voice Engine最初于2022年底开发,并已经提供给包括Heygen在内的少数公司进行测试性使用。
主要功能
1、自然听起来的语音生成:利用单个15秒的音频样本,Voice Engine能够创造出既情感丰富又真实的语音,显著提升合成语音的自然度和真实感。
2、支持多种用途:从教育援助、内容翻译、提高偏远地区服务质量,到支持非语言人士和帮助患者恢复声音,Voice Engine的应用场景广泛,跨越多个行业。
3、语言和口音的保留:在内容翻译时,Voice Engine能够保留原始发言者的本地口音,使得翻译后的语音不仅流利还能保持原声音的特色。
4、多语种支持:能够生成多种语言的语音输出,适应全球化需求,特别是对于需要将内容本地化到不同语言市场的企业和内容创作者来说,这一特点尤为重要。 - 开源自部署托管移动应用和 macOS 应用的分发平台 Zealot。
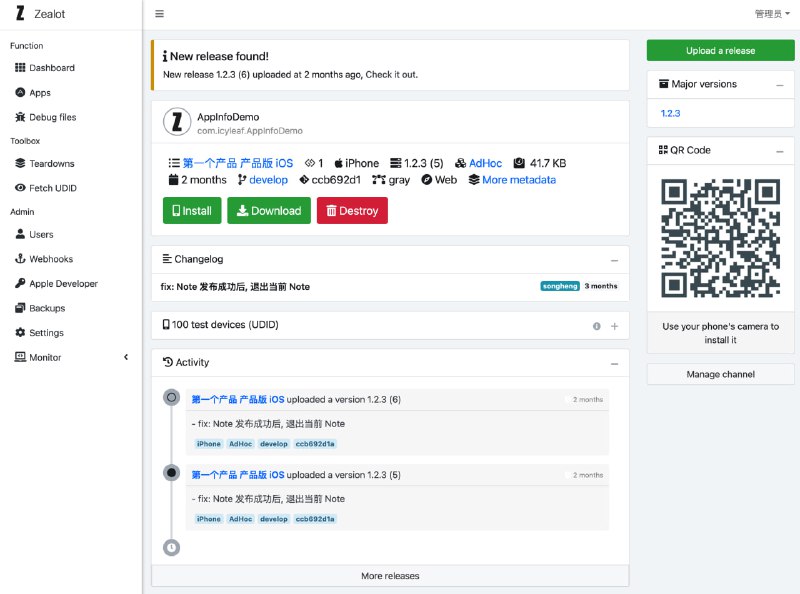
提供 iOS、Android SDK、fastlane 等丰富组件库,以及企业打包分发流程、上传应用全套流程方案。
并且可接入任意 CI 系统,实现一切自动化处理。
具有如下特性:
🌏 多平台应用托管: macOS、iOS、Android(apk/aab)、Windows、Linux 泛平台。
📱 测试设备一网打进: 自动同步 iOS 测试设备信息,允许一键注册新设备到苹果开发者。
🧑💻 丰富开发者套件: 提供 REST API、iOS、Android SDK 以及 fastlane 自动化构建插件。
💥 剖析应用内部的秘密: 解读 iOS、Android 应用或 iOS 描述文件的元信息。
🚨 内置多种事件通知: 数据可自定义 Income WebHook 到任意通知服务。
🗄 多渠道分类管理: 自由划分不同场景不同产品形态的应用渠道管理。
🎳 多架构部署: amd86/arm64/armv7 及各种部署方案应有尽有。
🔑 第三方登录: 飞书、Gitlab、Google、LDAP 和 OIDC 一键授权。
🌑 黑暗模式: 黑夜白昼自由切换。 -


-