黑洞资源笔记
- nm-vllm:高吞吐量和内存高效的LLM推理和服务引擎,针对LLM模型的推理引擎,具有优化的性能,支持量化和稀疏化等最新优化技术。通过nm-vllm,用户可以快速部署和推理LLM模型,并获得高效的推理性能
-
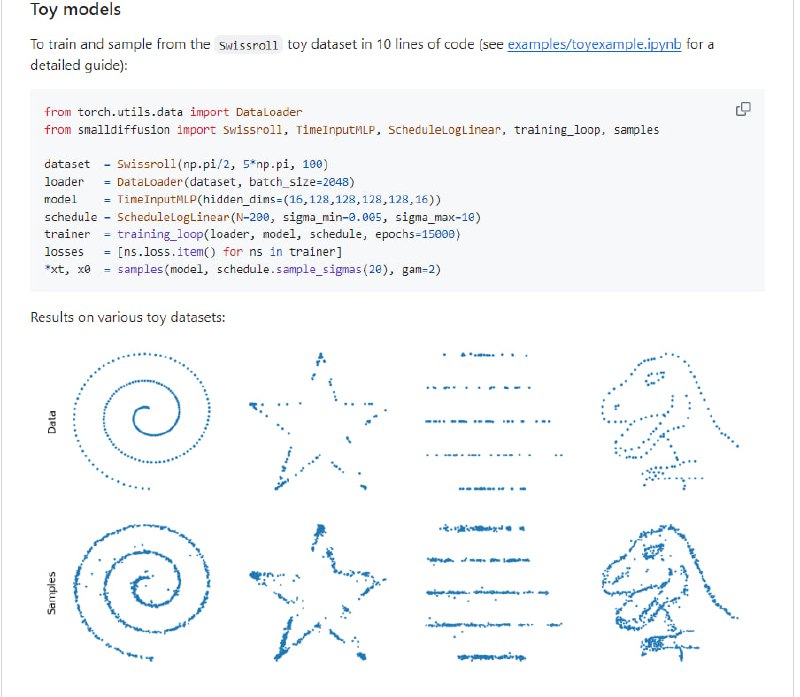
- smalldiffusion:用于训练和采样扩散模型的简单易读的代码库,支持从最简单的玩具模型到最先进的预训练模型的实验,核心代码只有不到100行非常易读的pytorch代码
- Awesome Bio-Foundation Models:生物基础模型大列表,涵盖了蛋白质、RNA、DNA、基因、单细胞等多个领域

- Command-R:多语言、高性能、可定制:350亿参数的开源语言模型

- C4AI Command-R是一个350亿参数的高性能生成式模型,由Cohere和Cohere For AI联合开发。
- Command-R是一个大型语言模型,其开放权重针对多种用例进行了优化,包括推理、摘要和问答。
- Command-R具有多语言生成能力,在10种语言上进行了评估,并具有高性能的RAG(Retrieval-Augmented Generation)能力。
- 该模型的许可证为CC-BY-NC,使用时还需遵守C4AI的可接受使用政策。
- Command-R的上下文长度为128K,可以使用Hugging Face的Transformers库进行调用和使用。
- C4AI Command-R的发布展示了Cohere在开发大型语言模型方面的实力。350亿参数的模型规模处于业界领先水平,有望在多个应用领域取得突破。
- Command-R的开放权重和对多种用例的优化,为开发者和研究者提供了灵活性和可定制性。这有助于促进模型的应用和创新。
- 多语言生成能力和高性能RAG能力的结合,使Command-R在跨语言任务和知识密集型任务上具有独特优势。这可能推动自然语言处理技术在全球范围内的普及和应用。
- CC-BY-NC许可证和C4AI的可接受使用政策体现了Cohere对于负责任AI开发的重视。在开放模型的同时,设置合理的使用边界,有助于防范潜在的滥用风险。
- 基于Hugging Face生态系统发布模型,降低了用户的使用门槛。这种与主流开源社区的融合,有利于Command-R的推广和迭代。
- 尽管Command-R的开放权重提供了灵活性,但对于缺乏计算资源的中小型开发者而言,350亿参数的模型规模可能难以承受。这可能加剧AI开发的门槛和不平等。
- Command-R在多语言任务上的出色表现,可能促使更多开发者将其应用于跨文化交流和全球化业务。但过度依赖单一模型,可能忽视了不同语言和文化的独特性。
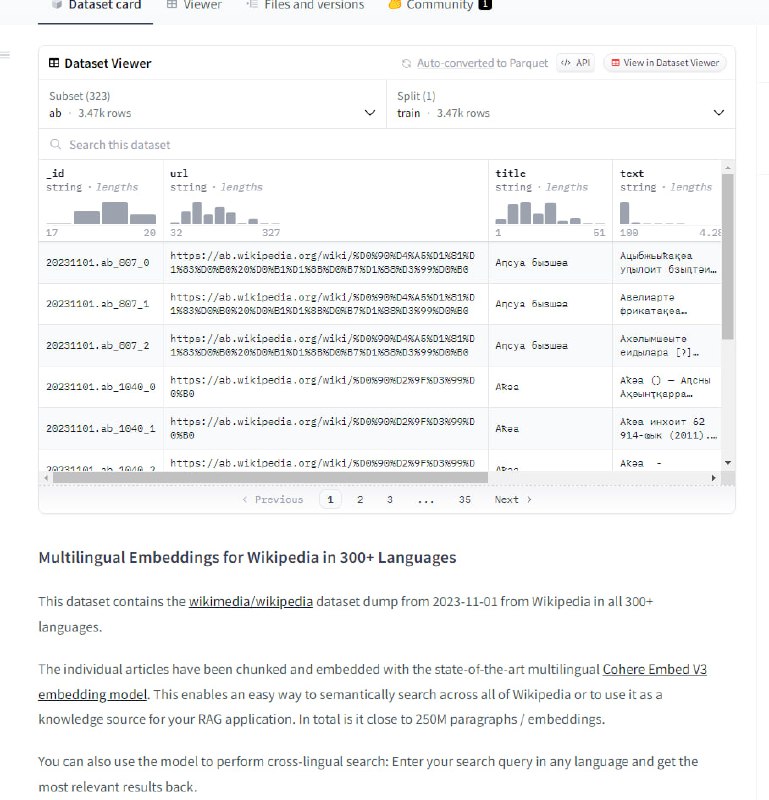
- 开放模型虽然有利于创新,但也可能加剧恶意使用和滥用的风险。即使有使用政策的约束,在实践中难以对每一个应用进行有效监管。这需要技术和制度的双重发力。 - 包含了300多种语言的Wikipedia嵌入表示的数据集 | Cohere
- 明天晚上可能会更新一下频道
- 我因病需要休整一个礼拜,频道视情况更新
- 马哥 OpenStack专题第二期 | 团购价198
- 那个AI俱乐部撤掉了,确实有点垃圾
- AtomoVideo:阿里巴巴开发的高保真图像到视频生成开源模型 可以生成符合真实世界运动状态的视频
主要功能:
1、高保真视频生成:AtomoVideo可以从单一静态图像生成高保真的视频序列,视频中的内容不仅与原始图片保持高度一致,而且动作自然流畅。
2、动作强度和连贯性:AtomoVideo生成的视频具有自然流畅的动作和良好的时间连贯性。视频中的运动看起来既自然又符合逻辑,没有突兀或不自然的过渡。
为了让视频里的动作看起来自然,AtomoVideo引入了时间卷积和时间注意力模块,这些模块专门处理视频帧之间的时间关系,帮助模型预测下一帧画面的变化,从而实现连贯的视频动作。AtomoVideo会特别处理视频的时间信息,让图片中的物体像在真实世界那样随时间移动和变化。
3、个性化适配:AtomoVideo能够与不同的个性化文本到图像(T2I)模型兼容,无需进行特定调整,这让它能够广泛适用于各种场景。AtomoVideo还能结合文字描述来生成视频。比如,你给它一张静态的海边图片,并告诉它“海浪轻轻拍打沙滩”,它就能根据这个描述生成一段海浪真的拍打沙滩的视频。 - MacBook Air M3版首发体验
-
- 洞主,推荐个通过AWS免费使用Claude3的途径,PC戳下方链接,通过 Amazon Bedrock 直达 Claude 3体验通道!
https://lab.amazoncloud.cn/demo/qrcode?trk=liuxin -
- dockerc:将Docker镜像编译成独立的可执行文件,可以将Docker镜像转换为用户可以直接运行的可执行文件,无需进行Docker运行时的安装和配置
-
-
- 数据清洗指南,旨在为机器学习和人工智能项目提供基础清理步骤,包括标准化空值、移除重复记录、删除大部分缺失数据的列、缺失值填充以及使用机器学习算法进行数据插补