黑洞资源笔记
-
- Consol3:完全在CPU上执行的图形引擎
- Watermarking Makes Language Models Radioactive | paper
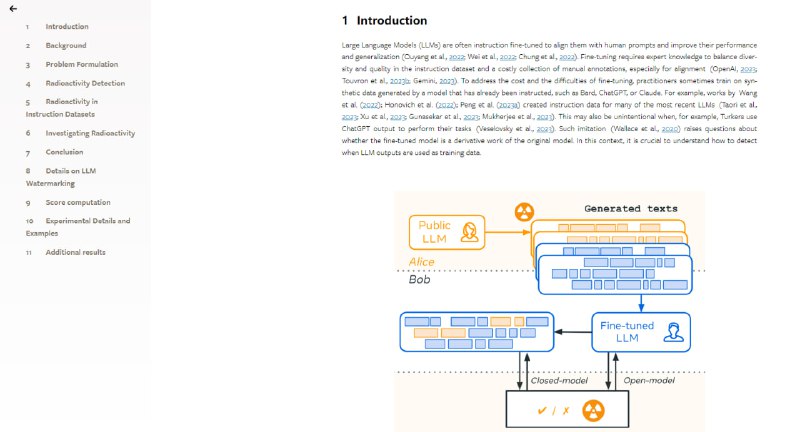
通过引入水印技术,有效提高了检测大型语言模型(LLM)生成文本被用作训练数据的能力,并且即使在微调数据中仅有少量水印文本存在时,也能以极高的置信度进行检测,这发现为数据版权和隐私保护提供了新的视角和工具。 -


- R2R:产品级RAG系统,提供半自主化的RAG框架,旨在弥合实验性RAG模型与鲁棒、产品级系统之间的差距

-


- 一个包含大约100万个AI偏好的数据集,从teknium/OpenHermes-2.5中提取而来。

它结合了来自源数据集和另外两个模型Mixtral-8x7B-Instruct-v0.1和Nous-Hermes-2-Yi-34B的回答,并使用PairRM作为偏好模型对生成结果进行评分和排名。
该数据集可用于训练偏好模型或通过直接偏好优化等技术对齐语言模型。
OpenHermesPreferences | #数据集 - Refined-Anime-Text:包含超过一百万条、约4400万个 GPT-4/3.5 token的、全新合成的文本数据集的动漫主题子集

- Supervoice GPT:将文本转换为音素及其持续时间的GPT模型,适用于输入语音合成器

-
-
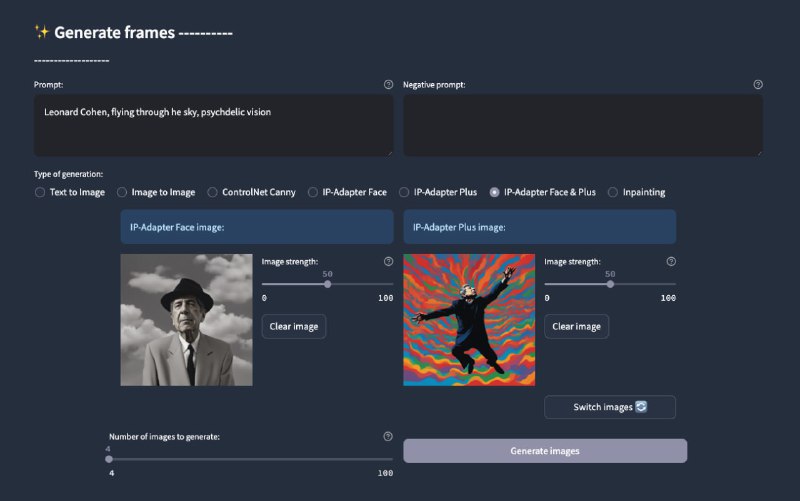
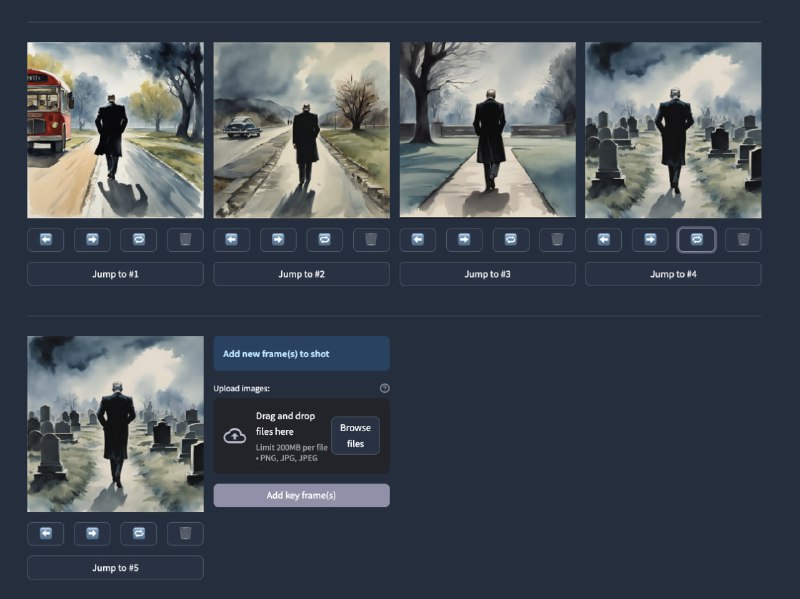
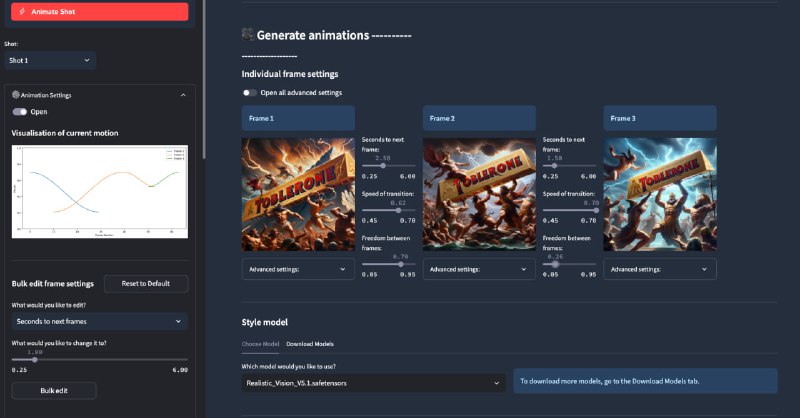
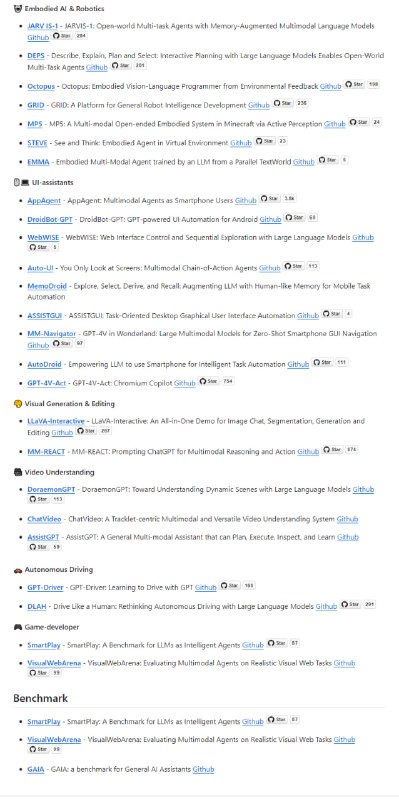
- 本地LLM使用指南 0.2 | #指南
LLMs,即大型语言模型(Large Language Models),是一种基于人工智能和机器学习技术构建的先进模型,旨在理解和生成自然语言文本。这些模型通过分析和学习海量的文本数据,掌握语言的结构、语法、语义和上下文等复杂特性,从而能够执行各种语言相关的任务。LLM的能力包括但不限于文本生成、问答、文本摘要、翻译、情感分析等。
LLMs例如GPT、LLama、Mistral系列等,通过深度学习的技术架构,如Transformer,使得这些模型能够捕捉到文本之间深层次的关联和含义。模型首先在广泛的数据集上进行预训练,学习语言的一般特征和模式,然后可以针对特定的任务或领域进行微调,以提高其在特定应用中的表现。
预训练阶段让LLMs掌握了大量的语言知识和世界知识,而微调阶段则使模型能够在特定任务上达到更高的性能。这种训练方法赋予了LLMs在处理各种语言任务时的灵活性和适应性,能够为用户提供准确、多样化的信息和服务。 - 构建你自己的 AI 辅助编码助手 | repo

介绍如何 DIY 一个端到端(从 IDE 插件、模型选型、数据集构建到模型微调)的 AI 辅助编程工具,类似于 GitHub Copilot、JetBrains AI Assistant、AutoDev 等 -