黑洞资源笔记
- 鬼怪屋:一个专门搜集鬼故事的网站。
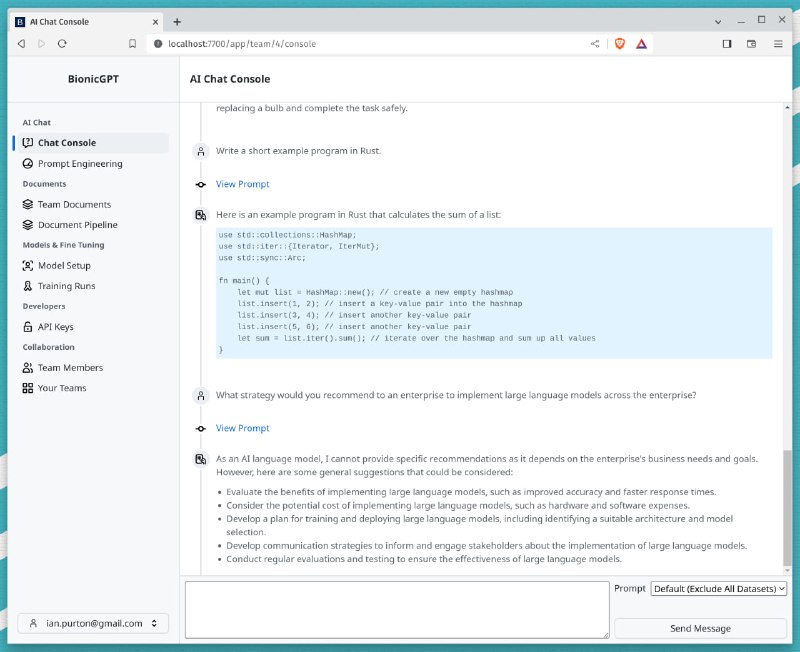
- Class Companion:利用生成式AI为学生提供高质量反馈的AI平台
☀️Class Companion刚刚公开发布并宣布获得了Index Ventures领投的400万美元种子轮融资。
☀️Class Companion从一开始就以教师为关注重点。提供及时反馈对学生学习非常重要,但传统的作业方式很难做到这一点。
☀️Class Companion可以即时评估学生的写作并提供针对性反馈,而不需要学生完成作业后再等待老师批改。
☀️及时的反馈可以帮助学生在最佳的心智状态下理解并改进自己的工作,也可以避免学生在存在困惑时重复错误。
☀️Class Companion将错误视为学习的机会,而不是简单地扣分。学生可以无限次迭代完善作业,在反馈的帮助下不断进步。
☀️Class Companion为教师提供了高度灵活性。教师可以选择现有的作业模板或添加自己的作业,并可以自定义每个学生的反馈侧重点。 - 何律师科普:防火墙是否合法
-
- 面向具有数学或物理背景读者的大语言模型讲座资料 | paper
-
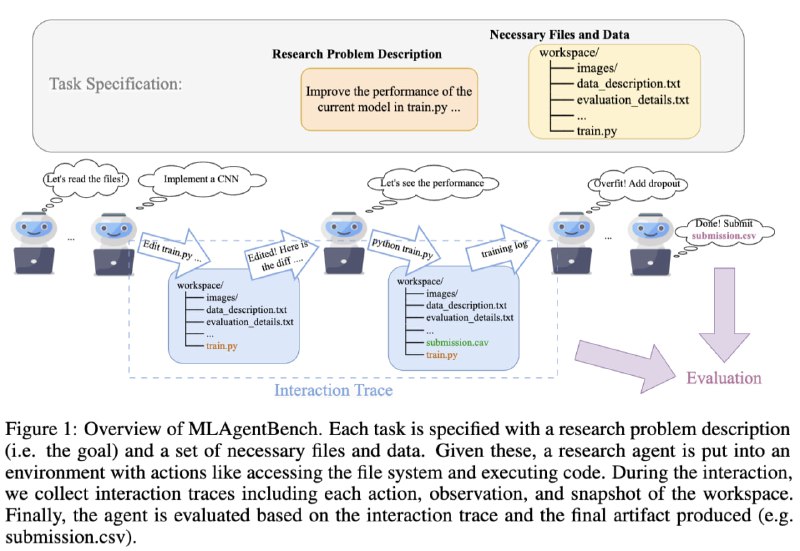
- MLAgentBench:一套端到端机器学习 (ML) 研究任务,用于对 AI 研究agent进行基准测试,其中agent的目标是获取给定的数据集和机器学习任务描述,并自主开发或改进 ML 模型。
-
- FMEngine 是一个用于训练非常大的基础模型的实用程序库。目前,FMEngine 支持两个模型系列:GPT-NeoX和LLama。
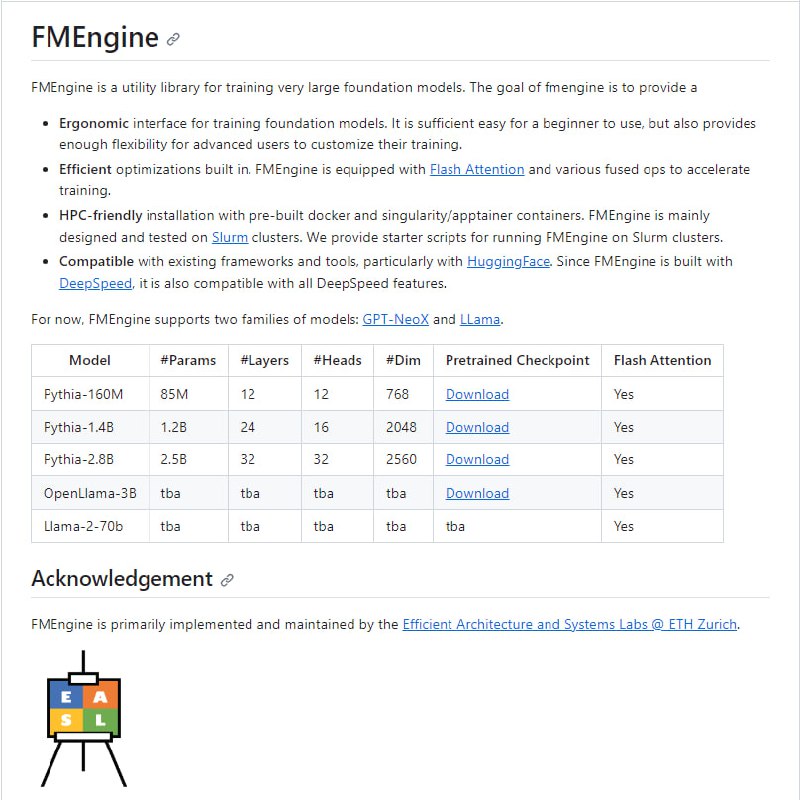
fmengine 的目标是提供一个:
●用于训练基础模型的人体工程学界面。它对于初学者来说足够容易使用,而且还为高级用户提供足够的灵活性来定制他们的培训。
●内置高效优化。FMEngine 配备Flash Attention和各种融合操作来加速训练。
●使用预构建的 docker 和奇异性/apptainer 容器进行HPC 友好安装。FMEngine主要是在Slurm集群上设计和测试的,提供了在 Slurm 集群上运行 FMEngine 的入门脚本。
●与现有框架和工具兼容,特别是HuggingFace。由于 FMEngine 是使用DeepSpeed构建的,因此它也兼容所有 DeepSpeed 功能。 - Runtime Speech Recognizer:适用于虚幻引擎(Unreal Engine)的跨平台、实时、离线语音识别插件,基于OpenAI 的 Whisper 语音识别引擎。
主要特征
识别速度快
提供纯英文和多语言模型,多语言支持100种语言
提供不同型号大小(从 75 Mb 到 2.9 Gb)
在编辑器中自动下载语言模型
任选将已识别的语音翻译成英语
可定制的属性
在设置中轻松选择模型尺寸和语言
没有静态库或外部依赖项
跨平台兼容性 - Prediction-powered inference (PPI) 是使用机器学习进行统计严谨的科学发现的框架。

给定少量带有黄金标准标签的数据和大量未标记的数据,预测驱动的推理可以估计总体参数,例如平均结果、中值结果、线性和逻辑回归系数。
预测驱动的推理既可用于对这些量进行更好的点估计,也可用于更严格的置信区间和更强大的 p 值。这些方法既适用于独立同分布设置,也适用于某些类别的分布变化。 - Crumb:一种高级、函数式、解释性、动态类型、通用的编程语言,具有简洁的语法和详细的标准库
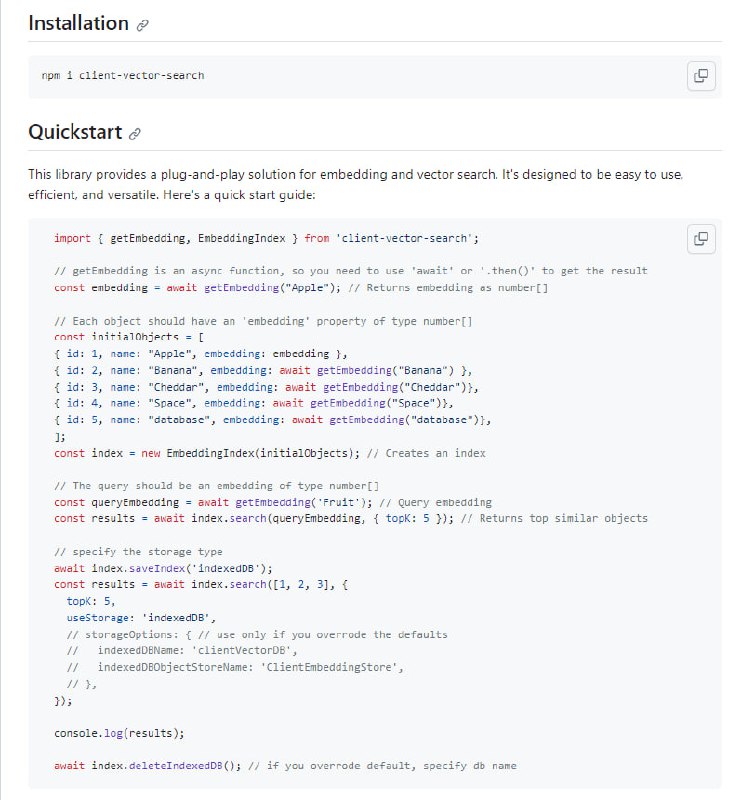
- client-vector-search:嵌入式、可搜索和可缓存的客户端向量搜索库,目标是构建一个超级简单、快速的向量搜索,可处理数百到数千个向量。约 1k 个向量涵盖了 99% 的用例。适用于浏览器和服务器端。
-
- 智能自动化二进制漏洞分析工具
Callisto是一款智能自动化二进制漏洞分析工具。其目的是自动反编译提供的二进制文件并迭代伪代码输出,查找该伪 C 代码中潜在的安全漏洞。Ghidra 的无头反编译器驱动二进制反编译和分析部分。伪代码分析最初由Semgrep SAST 工具执行,然后传输到GPT-3.5-Turbo,以验证 Semgrep 的发现以及潜在的其他漏洞识别。
该工具的预期目的是协助二进制分析和零日漏洞发现。输出旨在帮助研究人员识别二进制文件中潜在的感兴趣区域或易受攻击的组件,然后可以进行动态测试以进行验证和利用。它当然不会捕获所有内容,但使用 Semgrep 对 GPT-3.5 进行双重验证旨在减少误报并允许对程序进行更深入的分析。
对于那些希望将该工具用作快速无头反编译器的人来说,output.c创建的文件将包含从二进制文件中提取的所有伪代码。这可以插入您自己的 SAST 工具或手动分析。
Callisto | #工具 -
-
-