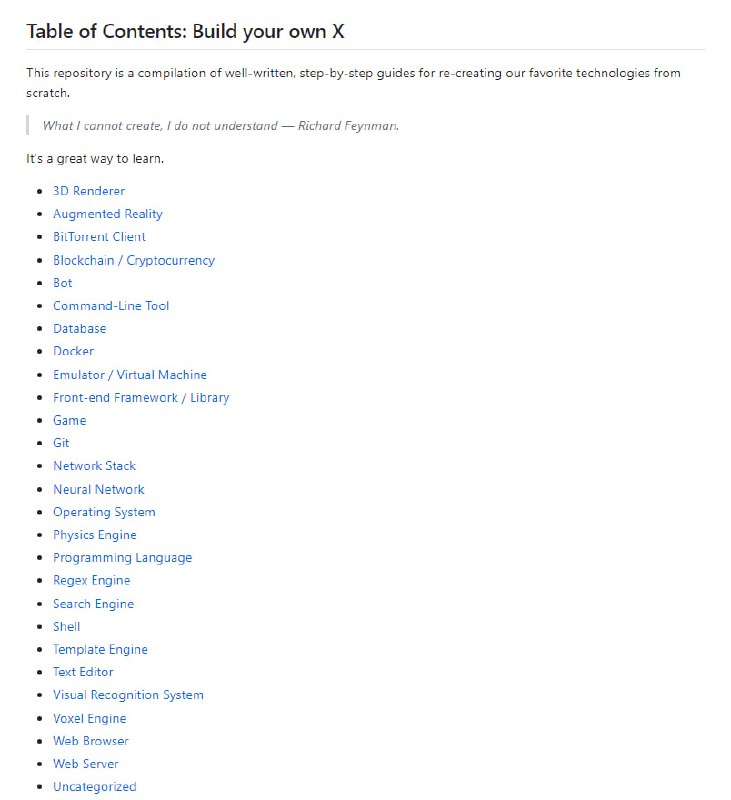
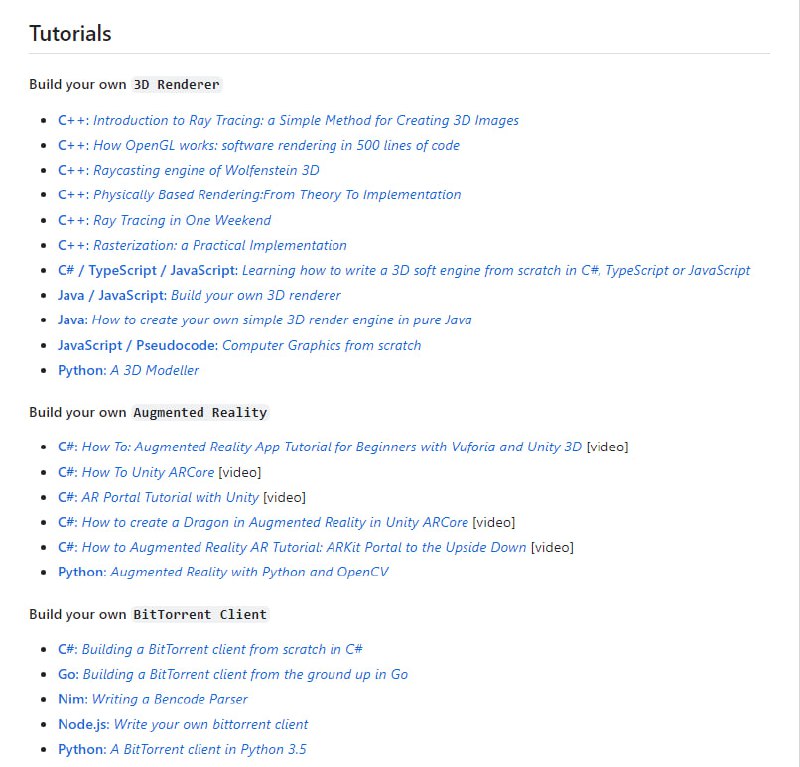
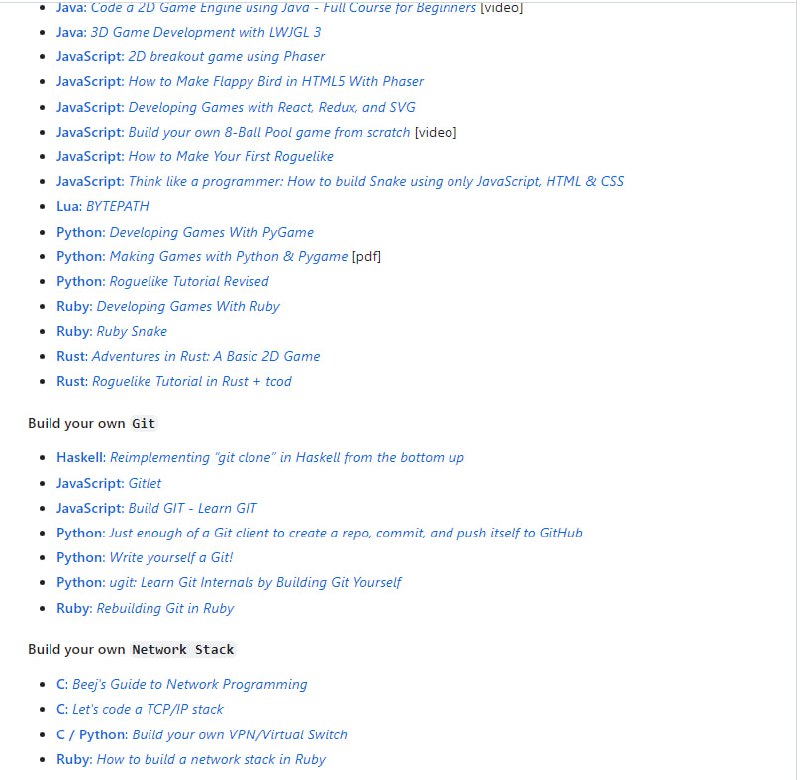
黑洞资源笔记
-
- Bloom Filters and Beyond: An Illustrated Introduction and Implementation

本文详细介绍了Bloom过滤器及其实际应用和Python实现。我们还讨论了计数Bloom过滤器,该过滤器允许删除项目。那些正在开发高性能和大数据系统的人将会发现这是一个有用的工具。 -

- SpaceX 星舰着陆视频
-


- 可以搜索2亿科学研究论文ChatGPT插件
用户可以直接在聊天界面内搜索其庞大的科学研究论文数据库(超过2亿篇同行评审的论文),以找到基于科学研究的答案和内容。
你只需输入一个问题或关键词,就可以得到一系列与之相关的科学研究和答案。
无论你是学生、研究人员还是对科学有兴趣的普通人,只需输入一个问题或关键词,就能快速找到相关的科学证据和答案。这避免了在多个平台和数据库中进行繁琐搜索的需要。
同时它也可以避免ChatGPT给出一些错误答案,你可以使用该插件对ChatGPT给出的答案进行科学核实。
Consensus Search | 安装指南 | #插件 #工具 - Klein Design System:微盟B端设计系统 | 详细介绍
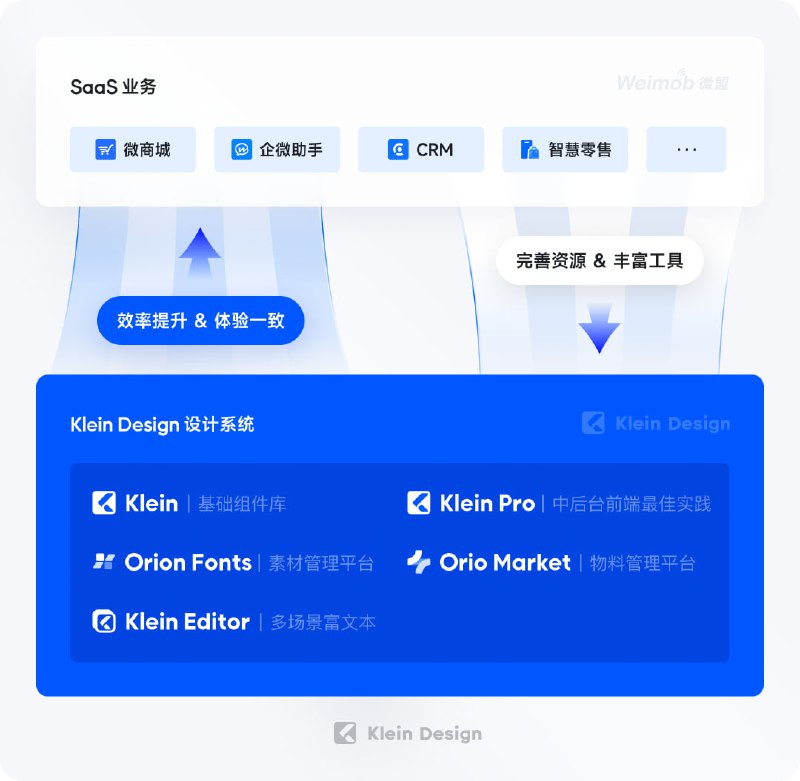
KleinDesign 是微盟用户体验团队&前端团队在服务业务过程中沉淀的一套服务于 SaaS 行业的企业级 WEB 端设计系统。包含设计指南、组件库、图标库、素材和物料管理工具、富文本编辑器等。 - 一个Chrome 浏览器扩展,能把外语视频里的语音替换成中文语音(不是字幕翻译)。目前不需要填写 OpenAI 的 API Key 来开启使用权限,需要邮箱注册。可以从四个预置的语音声线里选择一个你听着舒服的。
特性:
中文优化:更好的断句、更好的专业名词翻译,让翻译结果更贴近中文用户的习惯
多语种支持:支持英语、德语、日语、法语、西班牙语等多种常见语种的互相转换
更自然的声音:优化发音,让转换后的中文配音更人性化
多种语音风格:支持男声、女声,不同风格的配音
多平台支持(优化中):PC端、移动端等多平台的支持
视频下载(开发中):支持下载配音转化之后的视频
Youtube Dubbing | Chrome插件 | #插件 -
-
-
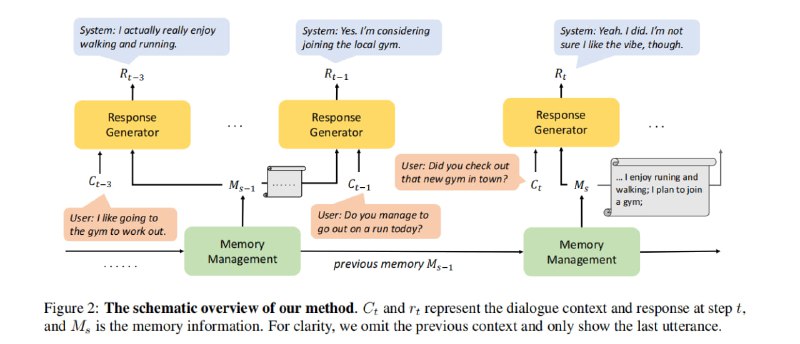
- 一种利用递归生成摘要来增强长期记忆能力的方法,以解决开放域对话系统在长对话中遗忘重要信息的问题。| paper
- Andrej Karpathy:大模型有内存限制,这个妙招挺好用
“现在最聪明的想法是使用一个小而便宜的草稿模型(draft model),先生成 K 个 token 候选序列,即一个「草稿」。然后用大模型批量的将输入组合在一起。速度几乎与仅输入一个 token 一样快。接着从左到右遍历模型和样本 token 预测的 logits。任何与「草稿」一致的样本都允许立即跳到下一个 token。如果存在分歧,那么就丢弃「草稿」并承担一些一次性工作的成本(对「草稿」进行采样并为所有后续 token 进行前向传递)。
这种方法起作用的原因在于,很多「草稿」token 都会被接受,因为它们很容易,所以即使是更小的草稿模型也能得到它们。当这些简单的 token 被接受时,我们会跳过这些部分。大模型不同意的 hard token 会回落到原始速度,但由于一些额外的工作,实际上速度会慢一些。
Karpathy 表示,这个奇怪的技巧之所以有效,是因为 LLM 在推理时受到内存限制,在对单个序列进行采样的 batch size=1 设置中,很大一部分本地 LLM 用例都属于这种情况。因为大多数 token 都很「简单」。”