黑洞资源笔记
-
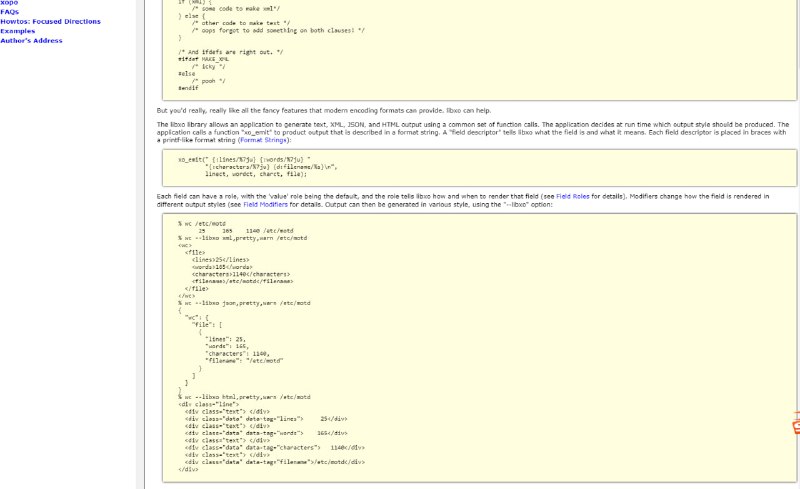
- libxo:生成文本、XML、JSON 和 HTML 输出的简单方法。
- 维基百科在生成式人工智能时代的价值 | link

- LangChain+向量数据库的LLM产品应用课程,共计约40小时的学习内容,完成10多个实际项目,如构建LLM驱动的销售和客户支持智能体等,旨在推广AI在不同行业的应用和解决方案 | 课程地址

- 零基础入门OpenAI API
文章介绍了OpenAI开发的ChatGPT大型语言模型聊天机器人,以及如何使用OpenAI Python库构建自己的项目和工具。
提供了获取API密钥、设置环境变量、使用Chat Completions API进行文本生成的步骤,提供了创建博客提纲生成器和简单ChatGPT样式聊天机器人的示例代码。
此外还介绍了如何调整温度和top_p参数来增加LLM生成响应的创造性和多样性。 - Primo:可视化CMS,内置代码编辑器、Svelte块和静态站点生成器

- SCOPE-RL是一款开源 Python 软件,用于实现离线强化学习(离线 RL)的端到端流程,从数据收集到离线策略学习、离策略性能评估和策略选择。软件包括一系列模块,用于实现合成数据集生成、数据集预处理、离策略评估 (OPE) 和离策略选择 (OPS) 方法的估计器。

该软件还与d3rlpy兼容,后者实现了一系列在线和离线 RL 方法。SCOPE-RL 通过OpenAI Gym和类似Gymnasium 的界面,可以在任何环境中进行简单、透明且可靠的离线 RL 研究实验。它还有助于在各种定制数据集和真实数据集的实践中实现离线强化学习。
特别是,SCOPE-RL 能够并促进与以下研究主题相关的评估和算法比较:
离线强化学习:离线强化学习旨在仅从行为策略收集的离线记录数据中学习新策略。SCOPE-RL 使用通过各种行为策略和环境收集的定制数据集来实现灵活的实验。
离线策略评估:OPE 旨在仅使用离线记录的数据来评估反事实策略的性能。SCOPE-RL 支持许多 OPE 估计器,并简化了评估和比较 OPE 估计器的实验程序。此外,我们还实现了先进的 OPE 方法,例如基于状态动作密度估计和累积分布估计的估计器。
离线策略选择:OPS 旨在使用离线记录的数据从多个候选策略池中识别性能最佳的策略。SCOPE-RL 支持一些基本的 OPS 方法,并提供多种指标来评估 OPS 的准确性。 -
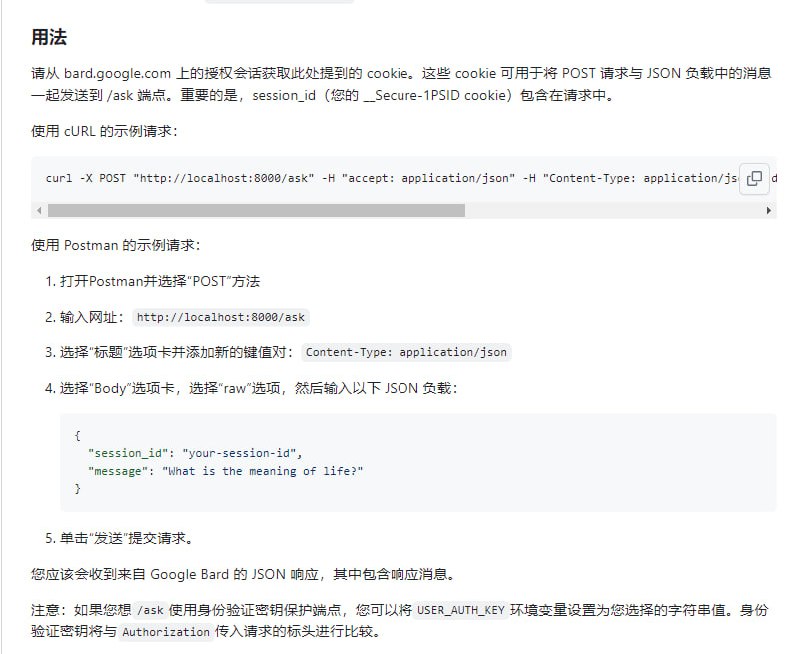
- Google Bard API:用于与Google Bard进行交互的FastAPI封装,允许用户通过一个简单的API发送消息给Google Bard,并接收响应
-
- Secondbrain:跨平台桌面应用程序,可在本机下载和运行大型语言模型(LLM),允许在本地使用AI对话,无需联网,保护隐私,可自由表达想法
- Code Interpreter API ,一个ChatGPT 代码解释器的开源(LangChain )实现。
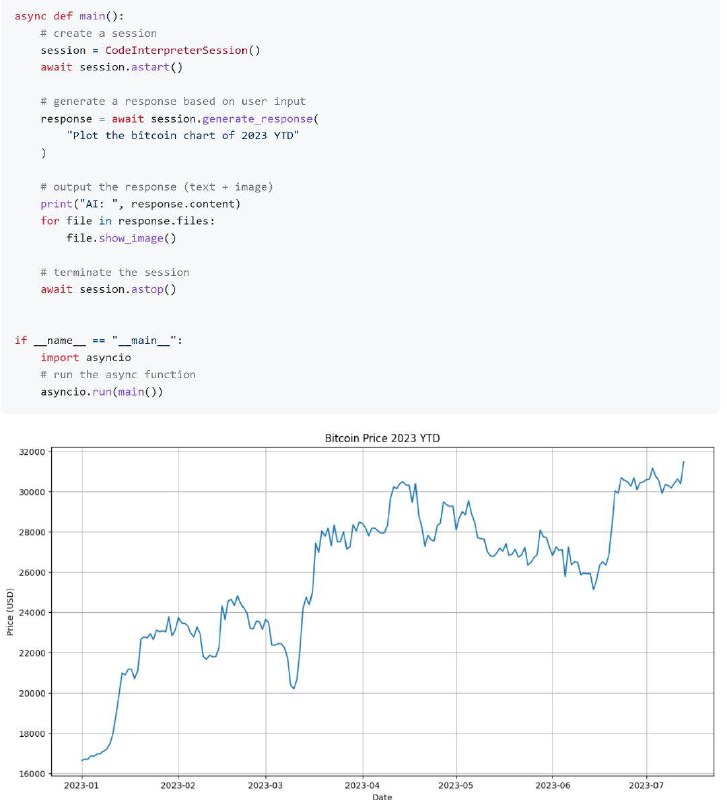
使用 CodeBoxes 作为沙盒 Python 代码执行的后端,可以使用自己的 OpenAI API 密钥在本地运行除 LLM 之外的所有内容。 - 如何用Rust重写一个JVM | link
- 打击共享初显成效,Netflix 新增 590 万订阅用户

Netflix 公布了其 Q2 季度的财报,在其禁止多用户共享同一订阅账户后,目前其全球付费订阅用户相对于 Q1 提升了590 万名,总数已达 2.3839 亿。上季度 Netflix 营收近 82 亿美元,利润则超过了 18 亿美元,虽不及分析师 83 亿美元的营收预期,但 Netflix 仍然认为 Q2 季度的收入增长来自针对密码共享行为的打击。 - 暴雪旗下所有正在运营的游戏将陆续登录 Steam 平台,其中的代表作《守望先锋 2》将于 8 月 11 日在 Steam 正式发行,目前游戏已经在 Steam 上架并处于预定阶段。| link

- 微星推出新款显示器,27 寸 IPS/100Hz/699 元

微星今日在电商平台上架了一款高性价比的显示器新品:微星 PRO MP273A。这款新品采用了 27 英寸的 1080P 面板,支持最高 100Hz 的刷新率与 250nits 的亮度。产品包含 DP、HDMI 与 VGA 接口, 显示器底座则可当作显示器支架使用。
除了上述特性,MP273A 还支持可减少画面撕裂的 AMD Free Sync 技术, 并在这个价位罕见的提供了内置的双扬声器。对于桌面空间紧张但又需要听个响的用户来说,算是一个性价比很高的选择。 - BuboGPT:可以理解图像和音频的内容,并将这些理解与文本输入和输出相结合。
BuboGPT是由字节跳动开发的大型语言模型,能够处理多模态输入,包括文本、图像和音频,并具有将其响应与视觉对象相对应的独特能力。
它可以进行细粒度的视觉理解,音频理解,以及对齐的音频-图像理解和任意音频-图像理解。
BuboGPT的架构是通过学习一个共享的语义空间并进一步探索不同视觉对象和不同模态之间的细粒度关系,从而实现了包括图像、音频和文本在内的多模态理解。
它的训练过程包括两个阶段:单模态预训练和多模态指令调整。
在单模态预训练阶段,对应的模态Q-Former和线性投影层在大量的模态-文本配对数据上进行训练。
在多模态指令调整阶段,使用高质量的多模态指令跟踪数据集对线性投影层进行微调。
当你给它一个图像和一段描述图像的文本时,BuboGPT能够理解文本和图像之间的关系,并生成一个与图像内容相对应的响应。这种能力使得BuboGPT可以在对话中提供更丰富、更具上下文的回答。
音频理解能力:当你给它一个音频剪辑时,它可以生成一个详细的描述,涵盖音频中的所有声音部分,甚至包括一些人类可能无法注意到的短暂音频片段。
BuboGPT还可以处理匹配的音频-图像对,进行声音定位。例如,如果你给它一个场景的图片和场景中发生的声音,它可以理解声音和图像之间的关系,并生成一个描述声音来源位置的响应。
即使音频和图像之间没有直接的关系。在这种情况下,BuboGPT可以生成一个高质量的响应,描述音频和图像之间的可能关系。 -
-
- KartivAI: 将webgi 3D渲染和AI结合,高效批量产出广告营销素材
你只需上传素材,如你的标志或产品图片,然后描述想要的创意,Kartiv就会使用你的描述和素材来创建吸引人的视觉效果。这些都是自动化的,实时的,并在浏览器内部运行。KartivAI还实现了多种图形效果,同时还能生成复杂的3D 场景。
Kartiv 的特点包括:
易于使用:不需要任何设计知识或经验。
专业工具:可以编辑和配置创意中的每一个元素。
变体:Kartiv 可以快速生成大量的变体,使得探索和可视化多种想法变得容易。
自动调整大小:Kartiv 会自动调整你的创意的大小,以适应不同的媒介。
AI助手:Kartiv 的AI会学习和适应你的喜好,并在你的创意想法流动时提出建议。
协作:与你的团队分享想法和创意的完美工具,从简报到生产就绪的视觉效果。
测量:你可以使用 Kartiv 测试想法并衡量其影响。
优化:可以帮助你根据创意的表现来改进它们。
KartivAI还实现了多种图形效果,如 SSR(屏幕空间反射)、SSGI(屏幕空间全局照明)、AO(环境光遮蔽)、渐进阴影、去噪等,这些都可以使生成的图片和视频看起来更加真实和专业。
同时KartivAI还利用了最近在 LLMs(低级别模型)和扩散 AI 方面的进步,这使得它能够更好地理解和生成复杂的 3D 场景。