一个强大的图像标记基础模型:
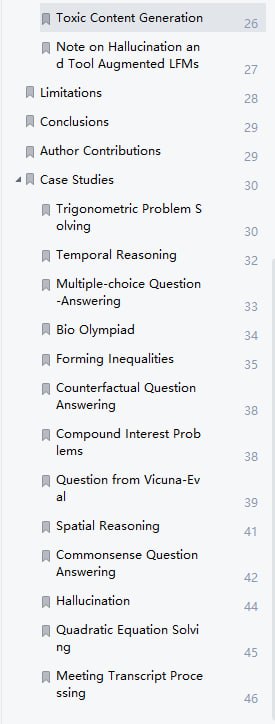
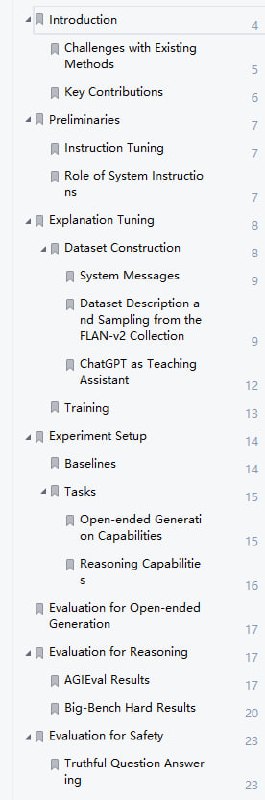
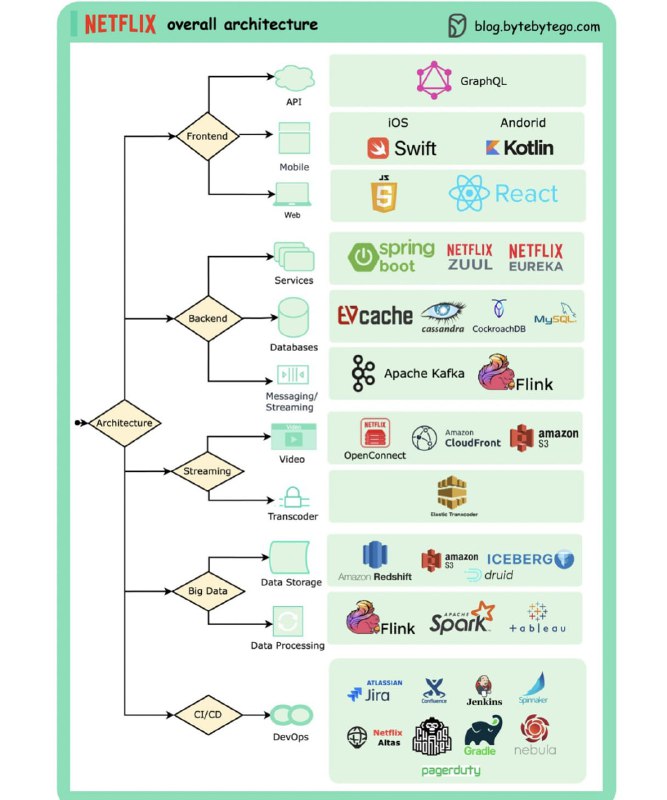
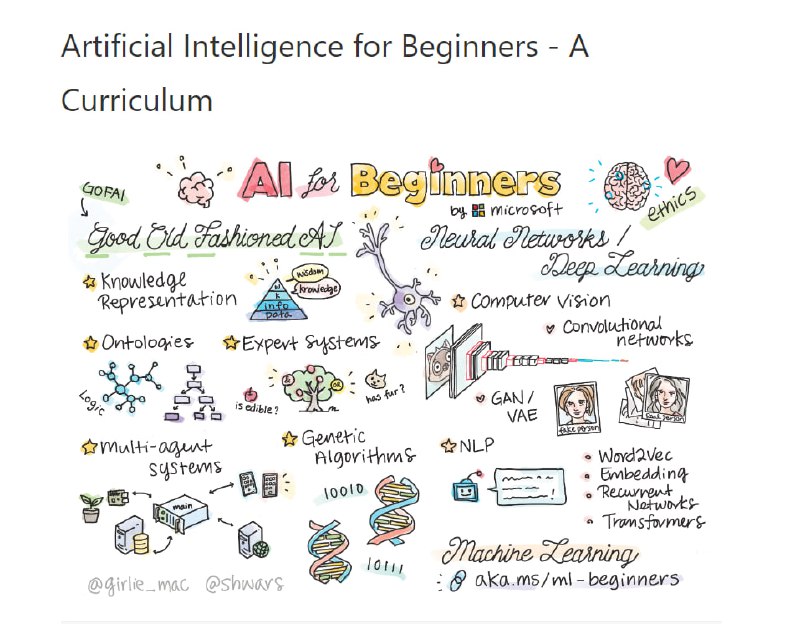
Recognize Anything Model (RAM) RAM 采用一种新的图像标记范例,可高精度地识别任何常见类别,并利用大规模图像文本对进行训练,而不是手动注释。
RAM 的开发包括四个关键步骤:
1. 通过自动文本语义解析大规模获取无注释图像标签;
2. 使用统一标题和标记任务,训练初步模型进行自动注释,分别由原始文本和解析标签监督;
3. 利用数据引擎生成额外注释并清除不正确的注释;
4. 利用处理后的数据对模型进行再训练,并使用更小但质量更高的数据集进行微调。
经过众多基准测试评估,RAM 的标记能力颇为优秀,效果明显优于 CLIP 和 BLIP。值得注意的是,RAM 甚至超越了完全监督的方式,甚至可媲美 Google API。