一个动画图解、能运行、可提问的数据结构与算法快速入门教程
主要内容包括:
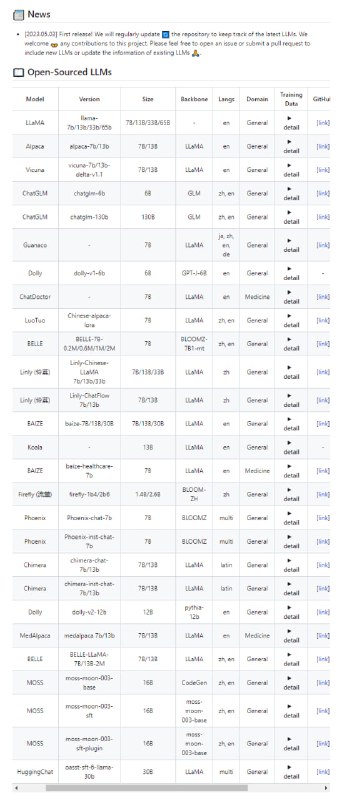
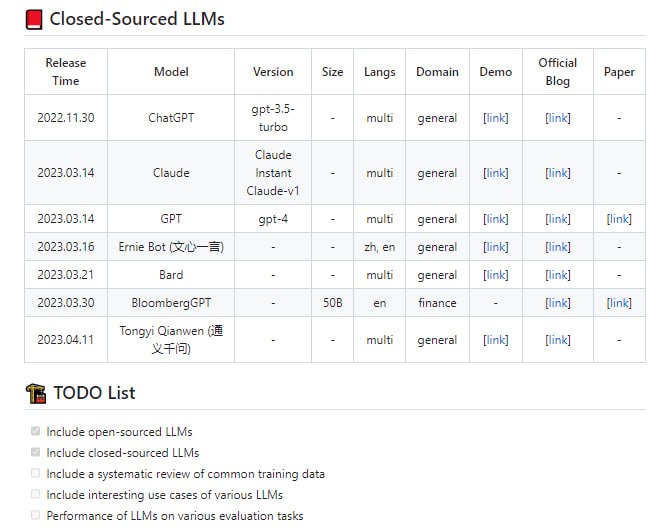
复杂度分析:数据结构与算法的评价维度、算法效率的评估方法。时间复杂度、空间复杂度,包括推算方法、常见类型、示例等。
数据结构:常见基本数据类型,数据在内存中的存储形式、数据结构的分类方法。涉及数组、链表、栈、队列、散列表、树、堆、图等数据结构,内容包括定义、优缺点、常用操作、常见类型、典型应用、实现方法等。
算法:查找算法、排序算法、搜索与回溯、动态规划、分治算法等,内容涵盖定义、应用场景、优缺点、时空效率、实现方法、示例题目等。
本项目旨在打造一本开源免费、新手友好的数据结构与算法入门教程。
全书采用动画图解,内容清晰易懂、学习曲线平滑,引导初学者探索数据结构与算法的“知识地图”;
源代码可一键运行,帮助读者在实践练习中提升编程技能,了解算法工作原理和数据结构底层实现;
鼓励读者互助学习,提问与评论通常可在两日内得到回复;
Hello算法 |
github |
PDF下载 |
#电子书