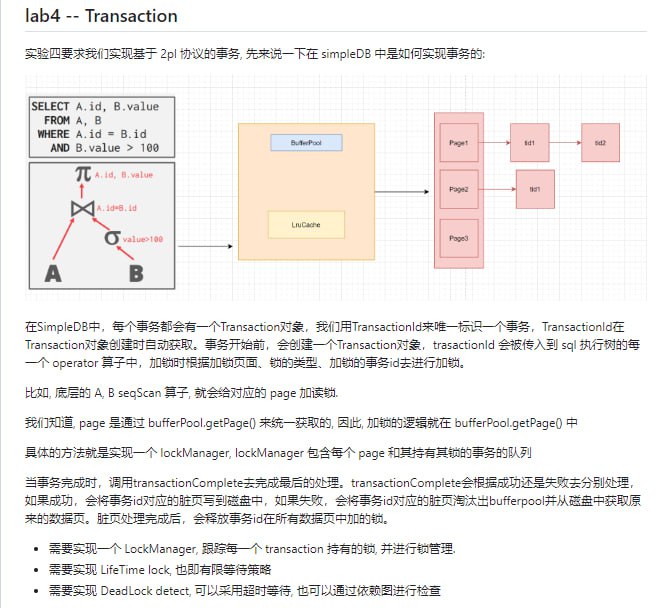
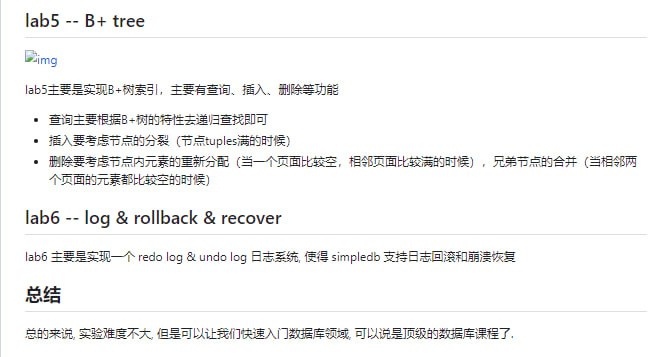
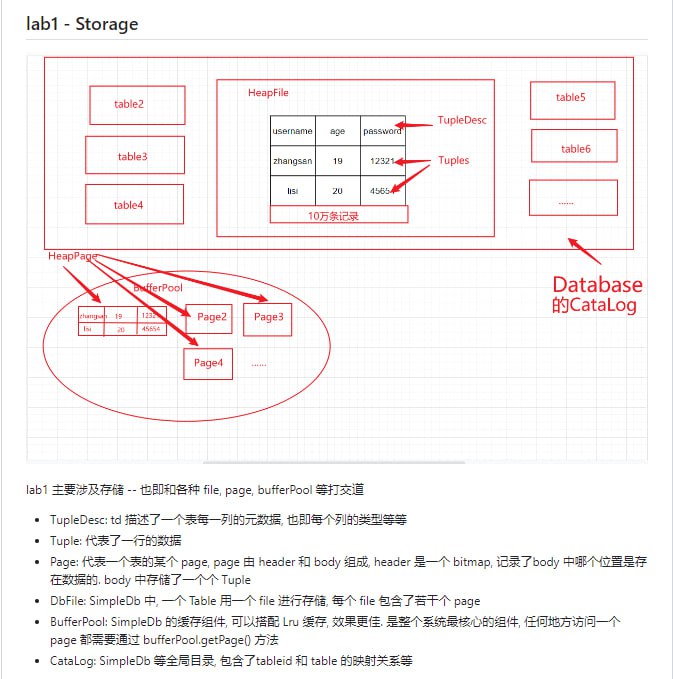
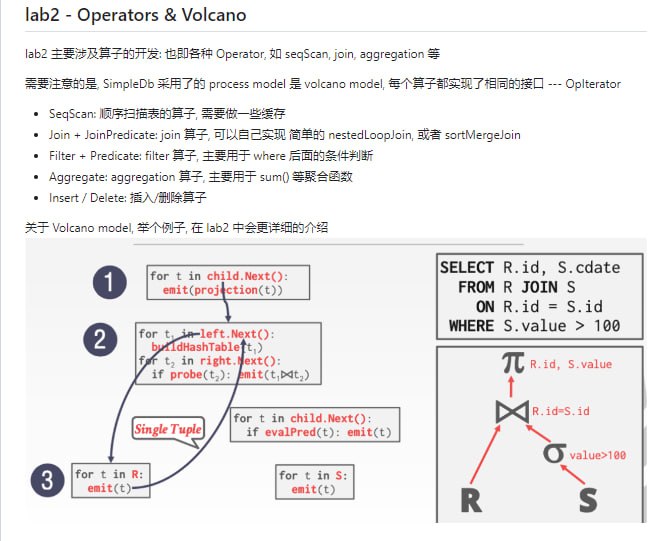
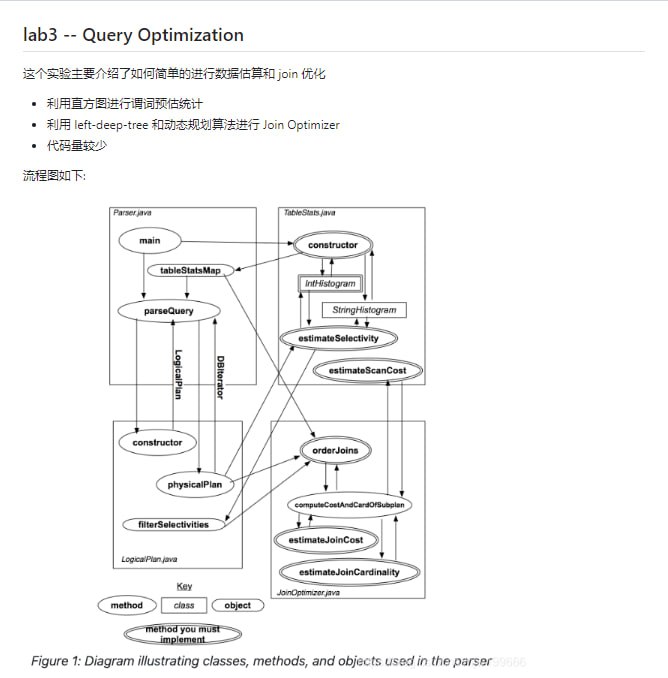
黑洞资源笔记
-
-
- 复旦大学发布了一个引发轰动的大语言模型:MOSS
这是一个支持中英双语和多种插件的开源对话语言模型,moss-moon系列模型具有160亿参数,在FP16精度下可在单张A100/A800或两张3090显卡运行,在INT4/8精度下可在单张3090显卡运行。MOSS基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。 -
- Whisper JAX:这是一个对OpenAI开源的Whisper模型网页链接 的优化版本,它针对GPU和TPU做了优化,性能提升了70倍,最快1小时的音频15秒能完成转录!
提速的关键:
1. 批量处理
Transformers 实现了一种批处理算法,其中单个音频样本被分成 30 秒的片段,然后分批转录这些块。这种批处理算法比 OpenAI(按顺序转录块)提供高达 7 倍的增益
2. JAX优于PyTorch
JAX 是一个用于高性能机器学习研究的自动微分库,通过即时 (JIT) 编译 Whisper,比PyTorch在 GPU 上获得了 2 倍的速度提升
3. TPUs 优于 GPUs
张量处理单元 (TPU) 是由 Google 设计的 ML 加速器, TPU 专为矩阵乘法而构建,与更通用的 GPU 相比具有显着优势。在 TPU v4-8 上运行 Whisper JAX 比在 NVIDIA A100 上快 5 倍!
全部加在一起:批处理 7 倍 JAX 2 倍 TPU 5 倍速度增益 => 整体速度提升 70 倍
paper | demo | repo - Proton 推出密码管理器
知名加密邮件服务商 Proton Mail 在近日正式推出了名为 Proton Pass 的密码管理工具。
Proton Pass 由 SimpleLogin 与 Proton 团队合作共同开发,旨在提高密码管理服务商业的安全标准的同时为用户带来更安全、更私密也更易于使用的密码管理方案。
目前 Proton Pass 尚处于测试阶段,并将于下周邀请购买 Proton Mail 长期许可的用户体验。 - Meta最新的开源项目DINOv2:具有自我监督学习功能的最先进的计算机视觉模型
这款全新的自监督视觉Transformer模型可以作为几乎所有计算机视觉任务的主干模型。无需微调。
• 无需大量标注数据,即可训练计算机视觉模型。
• 多功能主干:图像分类、分割、图像检索和深度估计。
• 直接从图像中学习特征,而无需依赖文本描述,这有助于更好地理解局部信息。
• 可以从任何图像集合中学习。
• DINOv2 的预训练版本已经上线,并在众多任务中与 CLIP 和 OpenCLIP 竞争。
Meta继SAM(Segment Anything) 网页链接 之后又一计算机视觉领域的重量级开源项目。
demo | 主页 | 源码 | Paper - LLaV:一个拥有类似 GPT-4 的大语言+视觉模型
“使用机器生成的指令跟踪数据对大型语言模型 (LLM) 进行指令调优提高了新任务的零样本能力,但这一想法在多模式领域的探索较少。
所以,我们开始尝试使用纯语言 GPT-4 生成多模态语言图像指令跟踪数据。通过对此类生成的数据进行指令调整,并推出了 LLaVA:大型语言和视觉助手。
这是一种端到端训练的大型多模态模型,连接视觉编码器和 LLM 以实现通用视觉和语言理解。
早期实验表明,LLaVA 展示了令人印象深刻的多模型聊天能力,有时在看不见的图像 / 指令上表现出多模态 GPT-4 的行为,并且与合成多模态指令跟随数据集上的 GPT-4 相比,相对分数达到了 85.1%。
当在 Science QA 上进行微调时,LLaVA 和 GPT-4 的协同作用达到了 92.53%,这个准确率颇高。
因此,我们在 GitHub 正式开放 GPT-4 生成的视觉指令调整数据、模型和代码库。”
demo | Project Page | Paper | 数据集 | 模型 | repo - 15 英寸 MacBook Air 将搭载 M2 芯片

上周,一款尚未发布的 15 英寸 MacBook Air 在 App Store 开发者日志中被发现,其处理器性能与 M2 芯片相当。这款 MacBook Air 配置了 8 核心 CPU 和 10 核心 GPU,与 M2 芯片相同,还有 8GB 内存。
韩国 Naver 博客一用户「yeux1122」透露,这款 MacBook Air 将搭载 M2 芯片,而非苹果原计划的 M3 芯片,让这传言显得更真了。
早前一份韩国的新闻报道称,今年初由于全球对 MacBook 需求明显下滑,苹果曾暂停 M2 芯片的生产长达两个月时间,即便后来 M2 芯片恢复了生产,但产量仅为去年的一半水平。
目前尚不清楚 15 英寸 MacBook Air 的具体发布时间,但可能会在 6 月 5 日开始的 WWDC 上公布。 - Reddit 推出付费 API 服务,授权给第三方训练 AI
美国著名论坛网站 Reddit 准备有偿提供其庞大的文字数据给Google 和 OpenAI等第三方人工智能公司,帮助他们训练 AI 模型。
Reddit 希望利用这一数据富矿实现商业收益,并为不同规模的公司提供分级服务。Reddit 上的对话数据更有助于赋予聊天机器人「人性」。
Reddit 创始人兼 CEO Steve Huffman 表示,Reddit 的数据极具价值。为了避免被滥用,Reddit 可能会关闭部分现有的 API,转成付费 API。
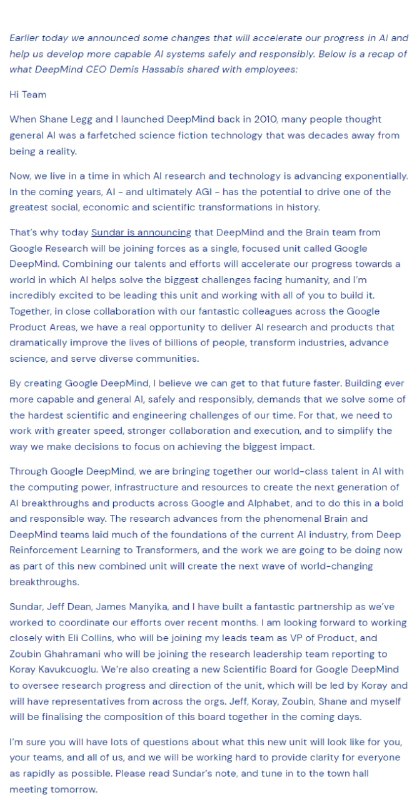
这对于计划年内上市的 Reddit 而言,这部分潜在巨大利润将有助于提高公司估值。 - DeepMind将与 Google Brain 合并成一个新团队,并取名 Google DeepMind。| 官宣
- 一款中文的开源数据标记工具。
目录前工具栏、多边形、标记点、标记线、分类、描述等图像标记标记能力,能够支持容器分组标记、扩展标记例分割、文本转写、转库线检测、关键点检测等计算机视觉任务现场,通过工具的自由组合即可自定义标记任务,支持COCO、MASK格式数据导出。
场景:计算机视觉
检测:车辆/车牌/行人/人脸/工业零件等检测场景。
分类:检测物体分类、目标特征、是非判断等分类场景
语义分割:人体分割、全景分割、可行驶区域分割、车辆分割等。
文本转录:车牌、发票、保险单、标志等的文本检测和识别。
轮廓检测:定位线条场景,如人体轮廓线、车道线等。
关键点检测:定位场景,如人脸关键点、车辆关键点、道路边缘关键点等。
LabelU | #工具 -