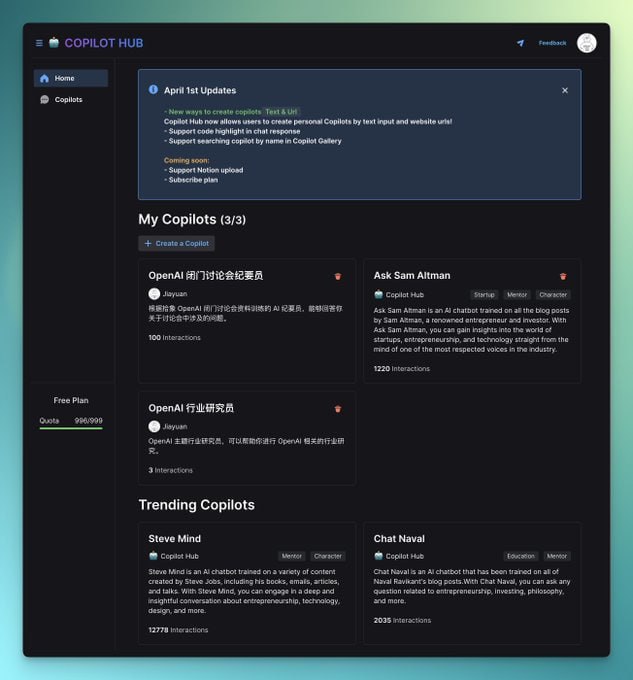
黑洞资源笔记
-
- 这是斯坦福的新课CS324,从另一个视角讲解了大模型的建模、理论、伦理和系统方面的基础知识 | 地址
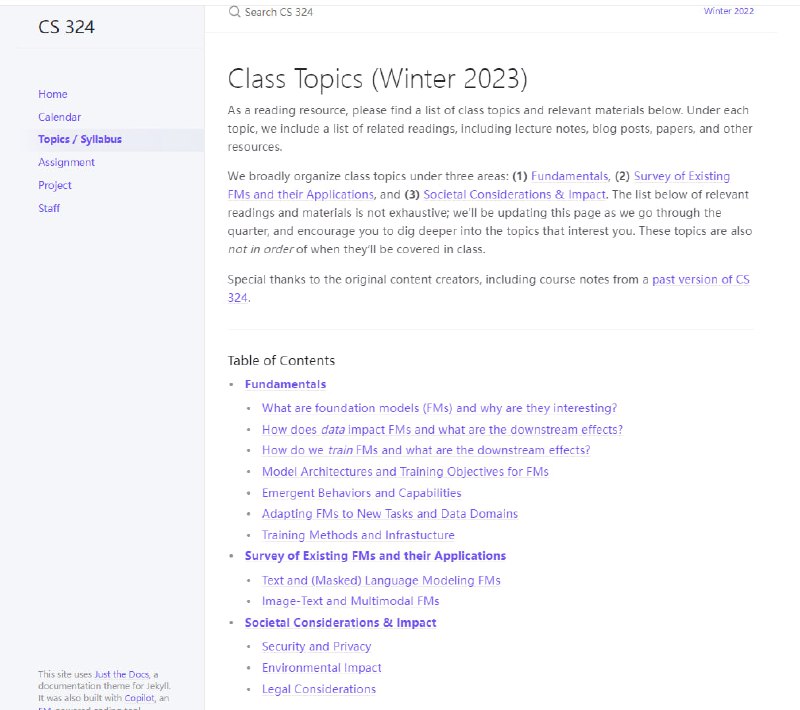
-
-
- 内推|HVV急需红蓝选手 | 详情
- Twitter算法对于人类的解读 第一部分:权威性。

在Twitter上,权威性是非常重要的因素之一。Twitter算法将会考虑一个用户的权威性,以决定他们的推文是否会显示在其他用户的时间线上。
Twitter使用多种方式来确定用户的权威性,其中包括:
关注者数量:一个用户的关注者数量越多,通常表示这个用户在Twitter社区中的地位越高。
关注者的权威性:如果关注一个用户的其他用户也是Twitter社区的重要成员,那么这个用户的权威性就会更高。
发送的推文的互动:如果一个用户的推文得到了其他用户的喜欢、转发、回复等互动,那么这个用户的权威性就会更高。
个人资料信息:用户的个人资料中包含的信息,如他们的个人简介、位置、教育背景等,也会被算法考虑在内。
总之,要提高自己在Twitter上的权威性,一个用户需要努力吸引更多的关注者,与Twitter社区的其他成员互动,并确保他们的个人资料信息准确完整。 - 开源版的"文心一言":Visual OpenLLM,基于 ChatGLM + Visual ChatGPT + Stable Diffusion,以交互方式连接不同视觉模型的开源工具 | #工具
- 有推主(@tarantulae)吐槽最近99%的类ChatGPT模型,几乎都是来源Meta开源的LLaMA,然后拿ChatGPT的数据(来自ShareGPT插件,这是个快速分享ChatGPT AI 对话的浏览器插件)做了一些微调,然后改个名字就变成开源了新的ChatGPT模型,本质上是在营销而已。
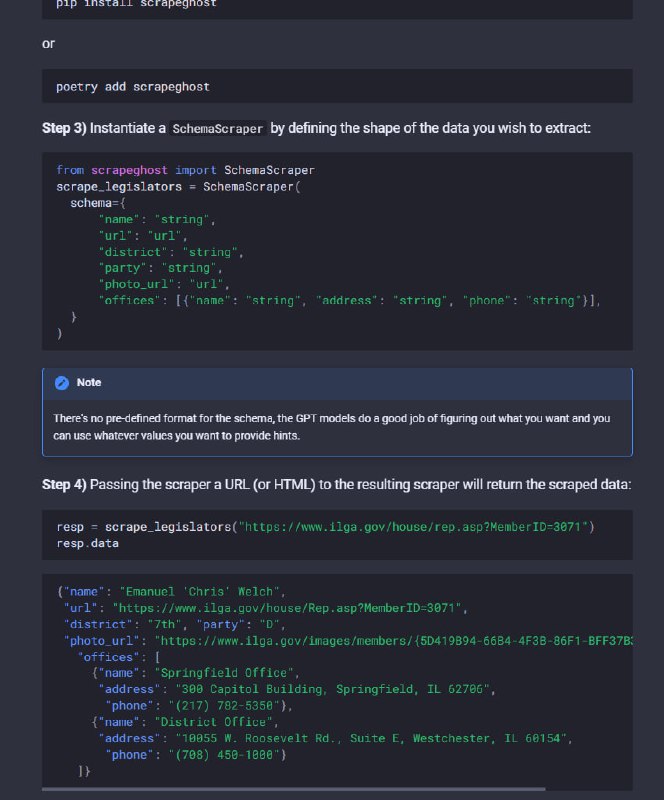
- 使用 OpenAI 的 GPT API 抓取网站的实验库scrapeghost。该库提供了一种从 HTML 中抓取结构化数据的方法,而无需编写特定于页面的代码。| 传送门
- 使用 AI 在研究论文中寻找答案,基于 GPT-4 的科学总结。目前为beta版本。
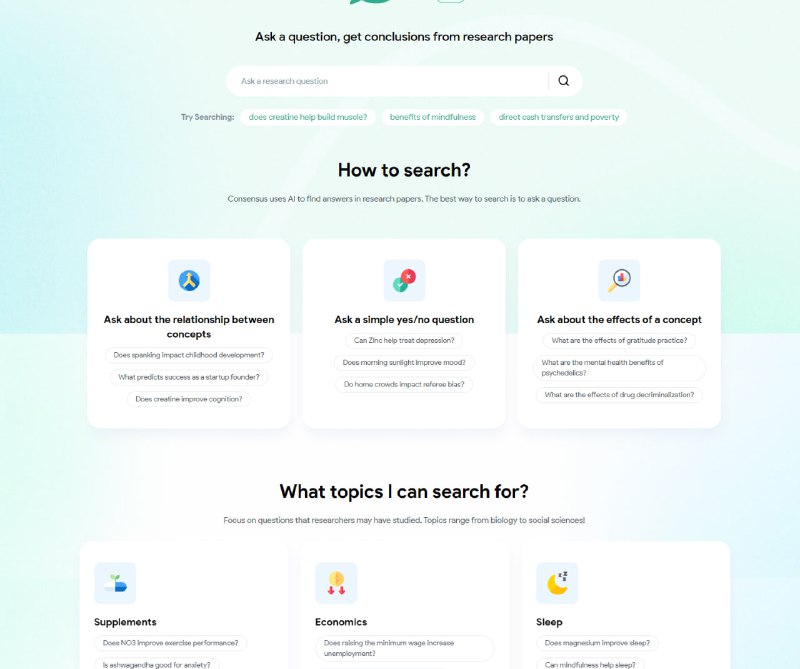
网站让你可以输入问题,然后它利用GPT-4来帮你找到最贴切的 5-10 篇论文里的答案。目前不支持中文输入。
Consensus -
-





-
-
- NSA Ghidra 软件逆向工程框架。
Ghidra是由美国国家安全局研究总局创建和维护的软件逆向工程(SRE)框架。该框架包括一套全功能的高端软件分析工具,使用户能够在各种平台上分析编译代码,包括Windows、macOS和Linux。其功能包括反汇编、汇编、反编译、图形化和脚本化,以及数百个其他功能。Ghidra支持各种处理器指令集和可执行格式,并可在用户交互和自动化模式下运行。用户还可以使用Java或Python开发自己的Ghidra扩展组件和/或脚本。
为支持NSA的网络安全任务,Ghidra旨在解决复杂SRE工作中的可扩展性和团队协作问题,并提供可定制和可扩展的SRE研究平台。NSA已将Ghidra SRE能力应用于涉及分析恶意代码和为SRE分析师生成深入洞察力的各种问题中,以更好地了解网络和系统中潜在的漏洞。
Ghidra | #框架 - TaxyAI:使用 GPT-4 的开源浏览器自动化
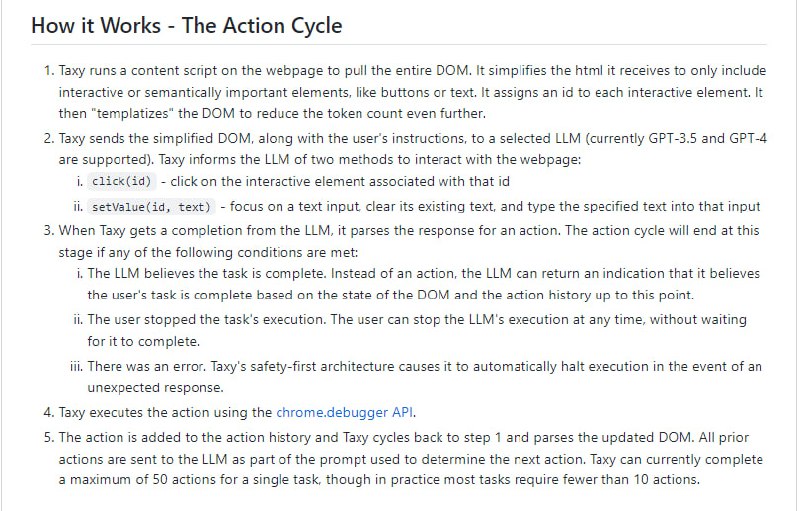
Taxy使用GPT-4控制浏览器,并代表人来执行重复的操作。目前,它允许定义临时指令。将来,它还将支持保存和预定工作流。
Taxy目前处于研究预览状态。许多工作流程失败或使代理程序混淆。如果想在Taxy上进行改进或在自己的工作流程上进行测试,请按照说明在本地运行。
评论区有演示