黑洞资源笔记
-
-

-
-
-

- GitHub 上最近比较火的一款低代码开发工具,可让你在短短几分钟内,快速搭建一个企业内部应用。
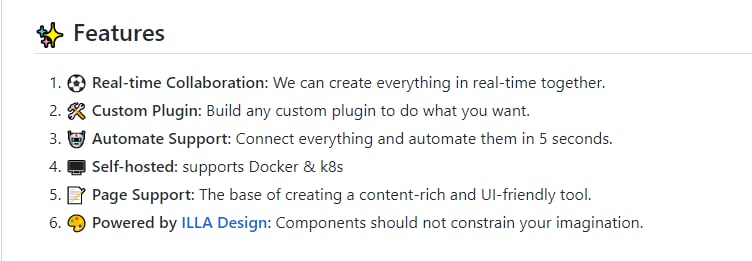
项目内置了一整套 UI 组件库,通过拖拽组件,即可完成应用搭建。此外,工具还接入了多种数据库和 API,让数据调用更加简单方便。
不仅如此, ILLA 还提供了在线协作功能,让团队成员一起以更高效的方式,推进项目研发。
ILLA Builder | #工具 -
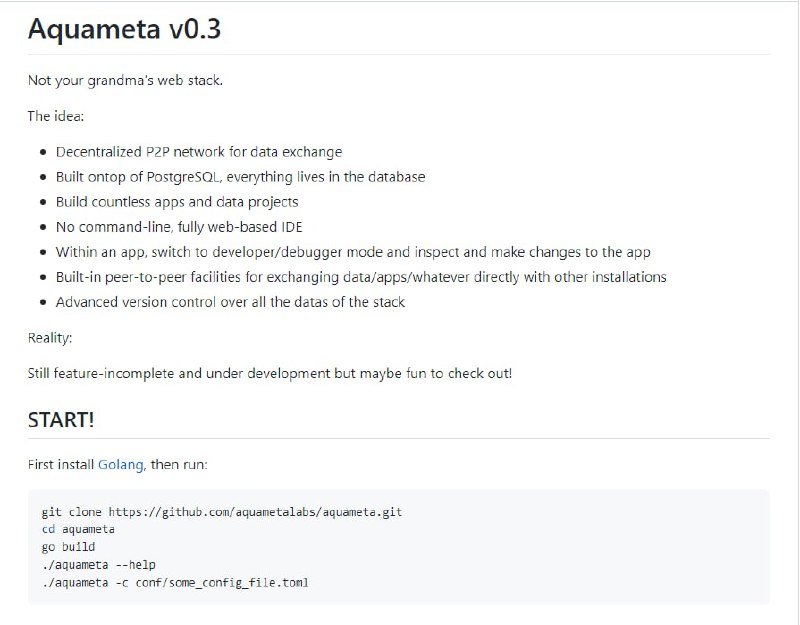
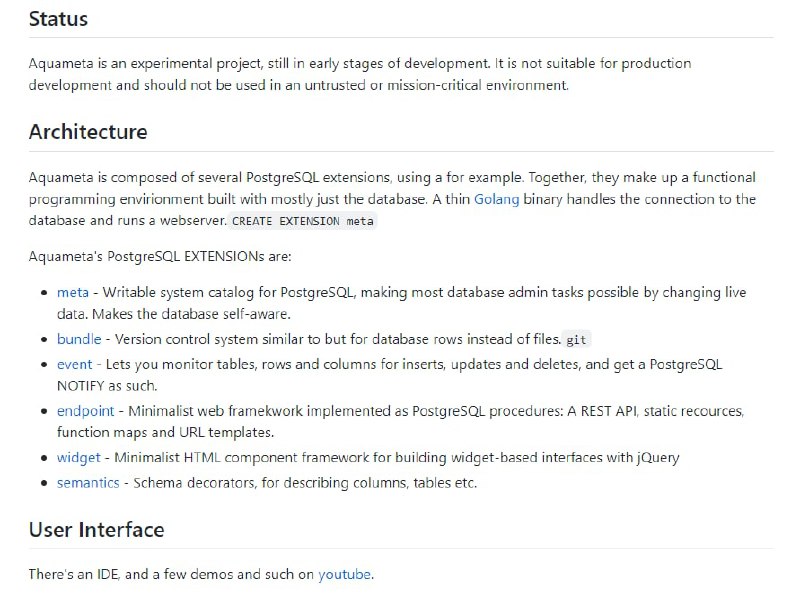
- 如何在 RSS 之上重建社交媒体? | 详文
- 终极的 SQLite 扩展集 | sqlean

- 词汇生成器和 NLP CLI | Github
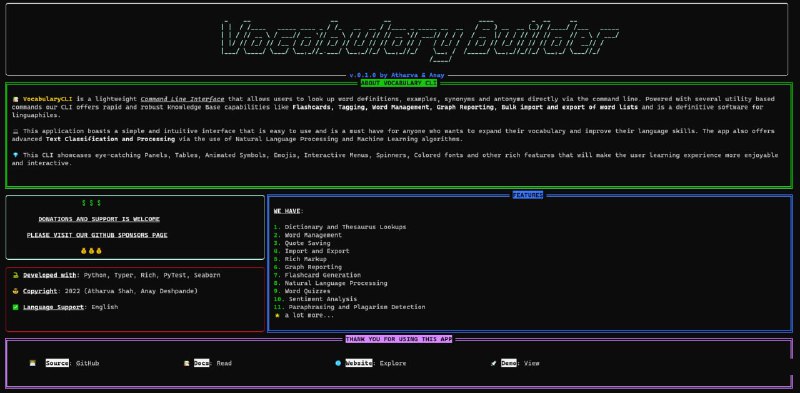
VocabularyCLI 是一个轻量级的命令行界面,允许用户直接通过命令行查找单词定义、示例、同义词和反义词。借助多个基于实用程序的命令,我们的 CLI 提供了快速而强大的知识库功能,例如抽认卡、标记、单词管理、图形报告、单词列表的批量导入和导出,是语言爱好者的权威软件。
此应用程序拥有简单直观的界面,易于使用,是任何想要扩展词汇量和提高语言技能的人的必备工具。该应用程序还通过使用自然语言处理和机器学习算法提供高级文本分类和处理,这将在“范围和功能”部分中详细讨论。
CLI 将提供引人注目的面板、表格、动画符号、表情符号、交互式菜单、微调器、彩色字体和其他丰富的功能,使用户体验更加愉快和互动。CLI 还将提供全面的用户手册和详细的文档,以帮助用户开始使用 CLI 并充分发挥其潜力。 -


- 使用低代码方法构建 MVP 的优缺点 | 详文

-
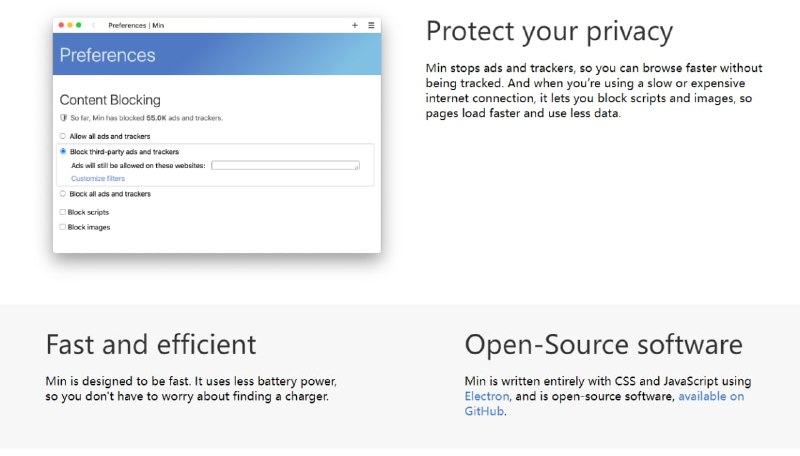
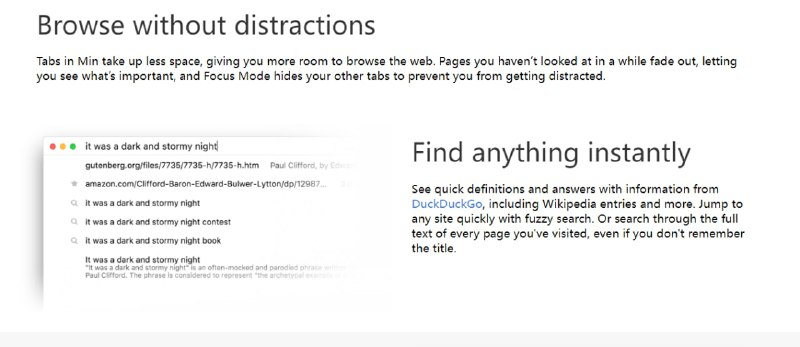
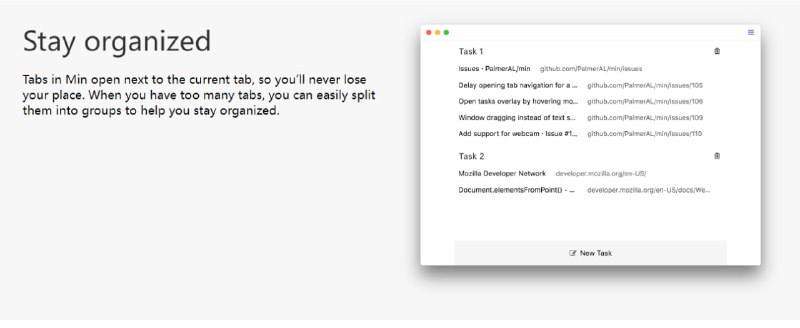
- 视觉、语音、文本的高效自监督学习 | Data2vec 2.0
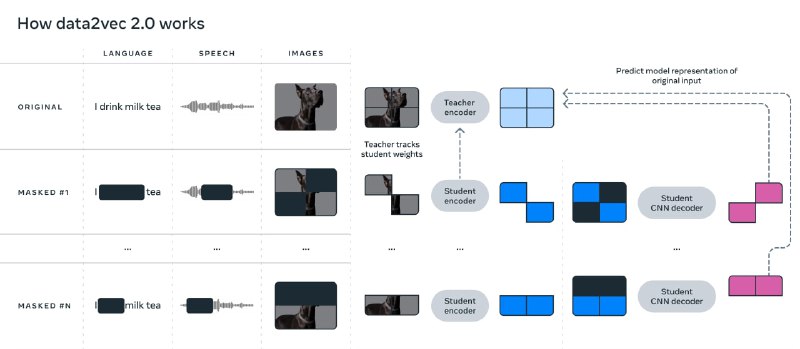
导语:人工智能最近的许多突破都是由自我监督学习推动的,它使机器能够在不依赖标记数据的情况下进行学习。但是当前的算法有几个明显的局限性,通常包括专门用于单一模态(例如图像或文本)并且需要大量的计算能力。这与人类学习形成鲜明对比:人们似乎比当前的 AI 学习效率更高,并且还以类似的方式从不同类型的信息中学习,而不是依赖于文本、语音和其他模式的单独学习机制。
今年早些时候,当我们发布 data2vec 时,Meta AI 解决了其中一个限制, data2vec 是第一个以相同方式学习三种不同模式(语音、视觉和文本)的高性能自监督算法。Data2vec 使得将文本理解等方面的研究进展应用于图像分割或语音翻译任务变得更加容易。
今天,我们将分享 data2vec 2.0,这是一种新算法,它的效率大大提高,并且性能优于其前身的强大性能。它实现了与最流行的现有计算机视觉自监督算法相同的精度,但速度提高了 16 倍。