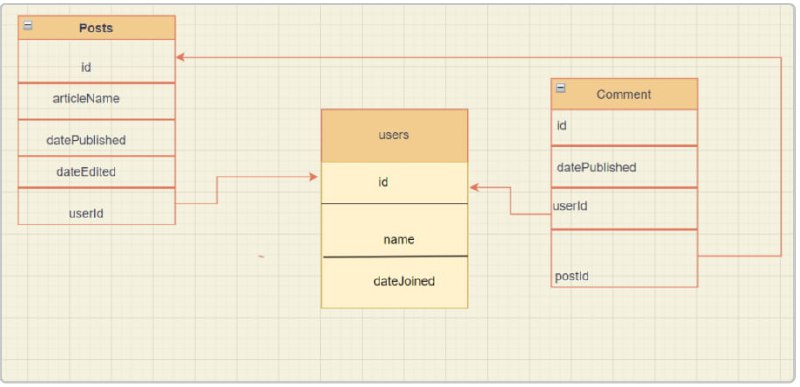
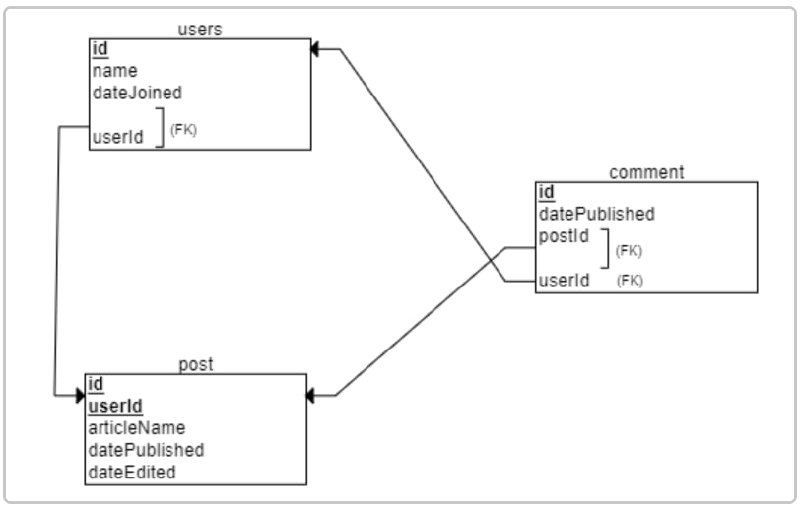
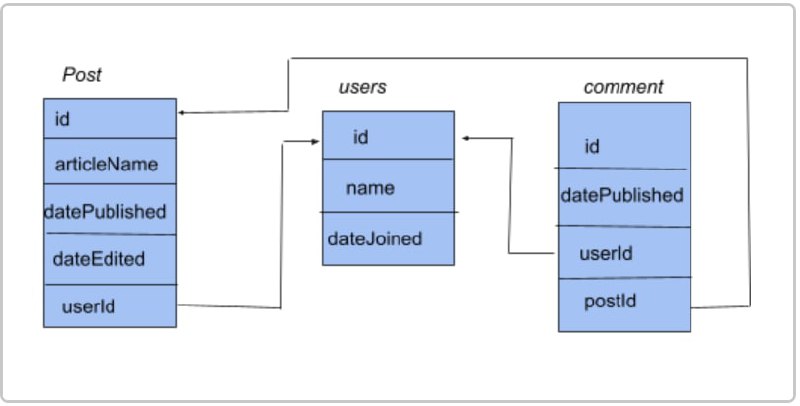
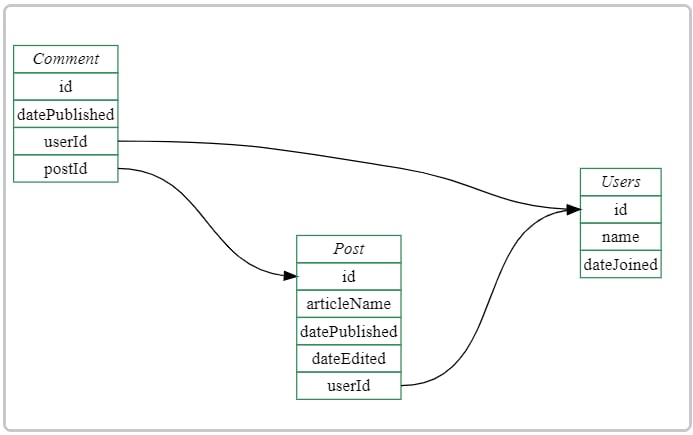
机器学习方案手册,一本包含逐步说明为各种任务训练深度学习模型的书。内容覆盖自然语言处理、计算机视觉、图像与文字
本书分为3个部分:
自然语言处理(NLP)
计算机视觉(CV)
图片和文字
以下是本节各章的简要概述:
命名实体识别- 讨论使用conllpp 数据集识别命名实体的训练转换器模型。我们将使用的特定模型称为bert-base-cased。该模型是原始 BERT 的较小版本,并且区分大小写,这意味着它将大写和小写字母视为不同。
掩蔽语言建模- 与填空问题类似,我们训练一个模型来使用xsum 数据集预测句子中的掩蔽词。我们将使用的特定模型称为distilbert-base-uncased。这是 bert base uncased 模型的精炼版本,它以相同的方式处理大写和小写字母。
机器翻译——在本章中,训练一个模型将文本从英语翻译成西班牙语。我们将在新闻评论数据集上训练来自赫尔辛基 NLP 小组的变压器模型。
总结——在本章中,训练了一个多语言模型来总结英语和西班牙语句子。使用的模型是 T5 Transformer 模型的多语言版本,使用的数据集是amazon reviews dataset。
因果语言建模- 本章重点介绍训练模型以自动完成 Python 代码。为此,我们将使用用于训练代码鹦鹉模型的数据。
计算机视觉部分涵盖了该领域下最常见的任务。本节中的章节使用pytorch 闪电、pytorch 图像模型(timm)、 albumentations库和权重和偏差平台。以下是本节各章的简要概述:
图像分类- 我们将训练卷积神经网络 (CNN) 模型对动物图像进行分类。我们将使用的 CNN 模型是“resnet34”,使用的数据集是动物图像数据集。
图像分割- 本章侧重于训练模型以分割给定图像中的道路。我们将使用 U-net 模型来完成此任务。
物体检测——在本章中,我们将专注于检测图像中的汽车。我们将预测与图像中包围汽车的边界框相对应的坐标。对于这个任务,我们将使用 fast-rcnn 模型。
最后一节包含训练模型以在给定图像的情况下生成标题的章节。它将有一个视觉转换器作为编码器,gpt-2 模型作为解码器。
在线阅读 |
ML Recipe |
#电子书 #机器学习 #手册