黑洞资源笔记
- 如何使用 Jupyter Notebook 在 Python 中创建仪表板? | 博文
-
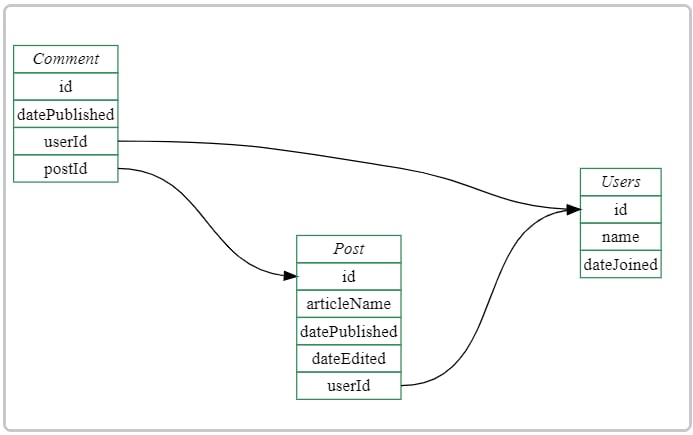
- 设计系统文档收集
Storybook是国外用来写设计系统文档的工具,而showcase就是用来展示他们的成功案例,包含微软、爱彼迎和Adobe等知名公司的86个设计系统,支持按标签和组件名称进行筛选。
Storybook是一个用于UI开发的工具,通过隔离组件使开发更快、更容易。允许你一次只在一个组件上工作。可以开发整个UI,而不需要启动一个复杂的开发堆栈,强制某些数据进入你的数据库,或在你的应用程序中导航。
Storybook showcase - 优惠活动明晚结束,代理还剩一个名额。需要的联系
-
-

- 雅思官方已经出了免费的模考系统了
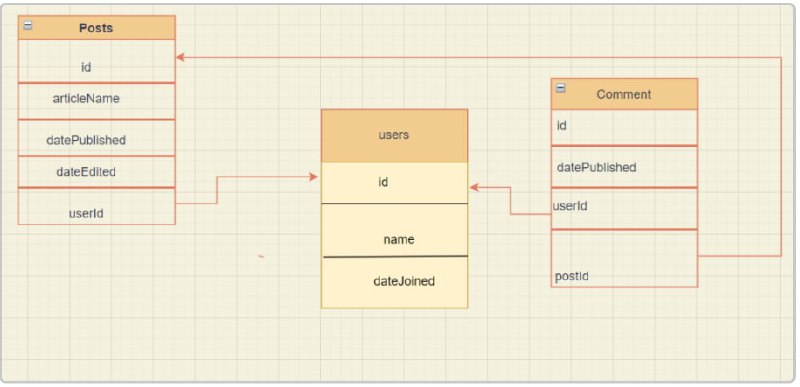
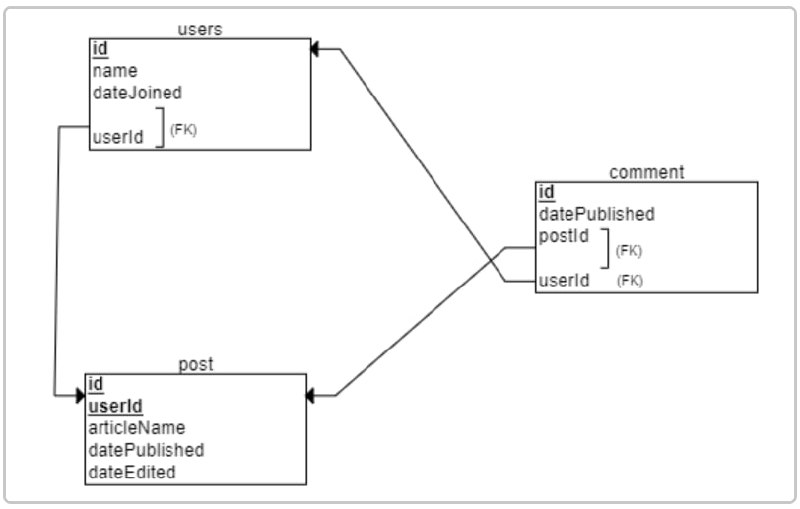
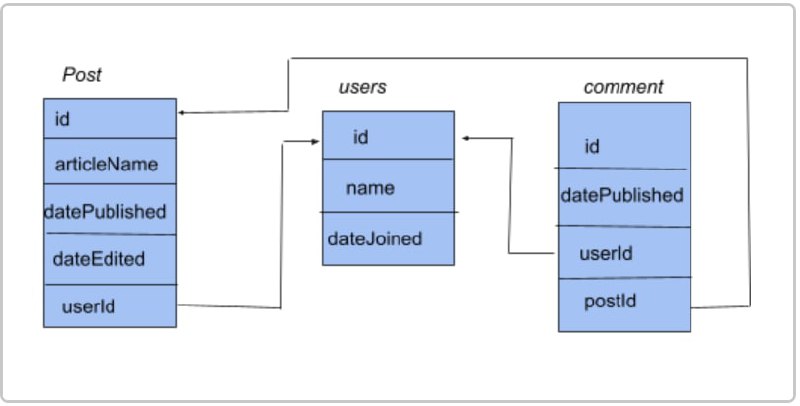
第一步 登录并注册
登录雅思中国官网在“雅思机考”页面就可以找到,也可以直接登入网址,就可以进入注册界面啦。
接着只需要在注册界面按要求输入名字和邮箱地址(一定要确保邮箱准确,因为最后会在你注册的邮箱收到官方发来的模考成绩),就可以直接进入考试界面了。完全不需要提前预约,也不需要支付任何费用(所有考生都可以免费体验)!
注册之后,就进入到了模考选择界面,模考系统中提供了学术类和培训类的两种模考真题。
第二步 开始考试
选择好考试种类之后,就可以进入模考了。模考时间长达2.5小时,完整的还原了雅思机考中阅读、听力和写作考试内容。
如果只想练习阅读、听力或者写作其中某一个section,可以在页面上自行选择。
屏幕的右上角就有一个finish section的按钮,点击这个按钮就可以立刻结束这个环节的考试,直接进入下一个section了。
第三步 查收成绩
当完成三个环节的模考之后,就会在注册的邮箱中收到一封邮件。
点击其中的"click here to access your marks"按钮,就可以立刻查看你的模考成绩了。
最终反馈的这份成绩只有阅读和听力两个部分。等级是按照欧洲语言共同参考框架(CEFR)等级的形式来评价的,大家可以根据CEFR等级与雅思分数的对应关系,估测自己的水平。
注册登记地址 -
-
-

- B站魔力赏陷赌博争议
近日,B站一位UP主发动态称,自己是“会员购魔力赏跳楼第一人”。魔力赏是B站“会员购”栏目下的一种玩法,简而言之,就是最近一直很流行的抽盲盒。然而在黑猫投诉平台中,关于B站魔力赏玩法的投诉达到3000多条。其中,消费者投诉的主要问题集中在:魔力赏不施行7天无理由退换;不支持回收;不发货;诱导消费,赌博等。
该UP主透露,短短十多天,自己在魔力赏中花了两万五千多元钱,结果只获得了三百个拼图,一个价值几百元以上的东西都没有。目前,身上背了4万多元的外债,心态爆炸。最后,这名UP主表示过几天将直播跳楼。令人庆幸的是,6月14日,他再次更新动态表示,将会努力挣钱争取花半年时间把债还清,一切重新开始。(三言财经) - 机器学习方案手册,一本包含逐步说明为各种任务训练深度学习模型的书。内容覆盖自然语言处理、计算机视觉、图像与文字
本书分为3个部分:
自然语言处理(NLP)
计算机视觉(CV)
图片和文字
以下是本节各章的简要概述:
命名实体识别- 讨论使用conllpp 数据集识别命名实体的训练转换器模型。我们将使用的特定模型称为bert-base-cased。该模型是原始 BERT 的较小版本,并且区分大小写,这意味着它将大写和小写字母视为不同。
掩蔽语言建模- 与填空问题类似,我们训练一个模型来使用xsum 数据集预测句子中的掩蔽词。我们将使用的特定模型称为distilbert-base-uncased。这是 bert base uncased 模型的精炼版本,它以相同的方式处理大写和小写字母。
机器翻译——在本章中,训练一个模型将文本从英语翻译成西班牙语。我们将在新闻评论数据集上训练来自赫尔辛基 NLP 小组的变压器模型。
总结——在本章中,训练了一个多语言模型来总结英语和西班牙语句子。使用的模型是 T5 Transformer 模型的多语言版本,使用的数据集是amazon reviews dataset。
因果语言建模- 本章重点介绍训练模型以自动完成 Python 代码。为此,我们将使用用于训练代码鹦鹉模型的数据。
计算机视觉部分涵盖了该领域下最常见的任务。本节中的章节使用pytorch 闪电、pytorch 图像模型(timm)、 albumentations库和权重和偏差平台。以下是本节各章的简要概述:
图像分类- 我们将训练卷积神经网络 (CNN) 模型对动物图像进行分类。我们将使用的 CNN 模型是“resnet34”,使用的数据集是动物图像数据集。
图像分割- 本章侧重于训练模型以分割给定图像中的道路。我们将使用 U-net 模型来完成此任务。
物体检测——在本章中,我们将专注于检测图像中的汽车。我们将预测与图像中包围汽车的边界框相对应的坐标。对于这个任务,我们将使用 fast-rcnn 模型。
最后一节包含训练模型以在给定图像的情况下生成标题的章节。它将有一个视觉转换器作为编码器,gpt-2 模型作为解码器。
在线阅读 | ML Recipe | #电子书 #机器学习 #手册 -